Editor’s note: The Jina AI Reader is a specialized tool that transforms raw web content from URLs or local files into a clean, structured, and LLM-friendly format. In this post, Han Xiao details how Cloud Run empowers Jina AI to build a secure, reliable, and massively scalable web scraping system that remains economically viable. This post explores the collaborative innovation, technical hurdles, and breakthrough achievements behind Jina Reader, a web grounding system now processing 100 billion tokens daily.
When Jina Reader launched in April 2024, its explosive growth — serving more than 10 million requests and 100 billion tokens daily — confirmed huge demand for reliable, LLM-friendly web content. Jina Reader isn’t just another scraper; it takes a different approach to how AI systems consume web content by transforming raw, noisy web pages into clean, structured markdown.
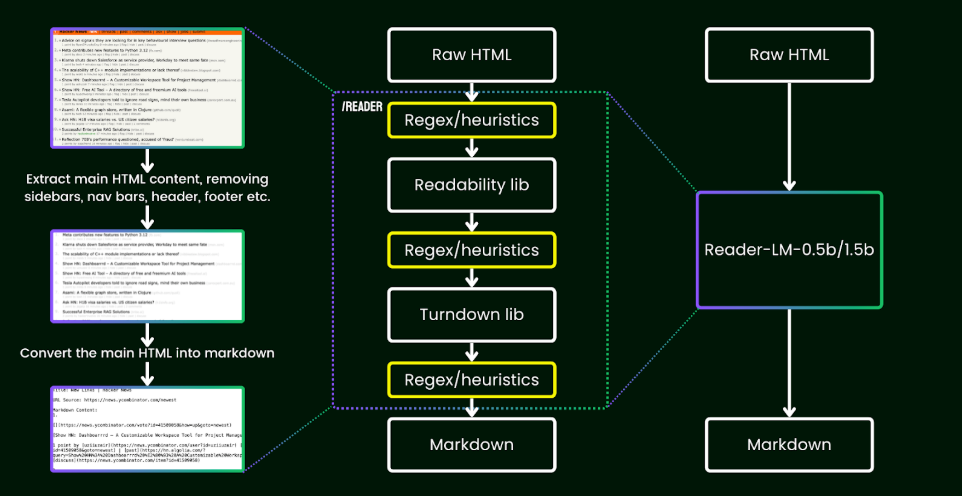
The core challenge for any AI system processing web data is the “web grounding problem.” Modern websites are a chaotic mix of content, ads, tracking scripts, and dynamic JavaScript, creating an overwhelming noise-to-signal ratio. Traditional scrapers struggle with this complexity, often failing on dynamic single-page applications or generating unusable, ungrounded data for LLMs. Jina Reader’s breakthrough, ReaderLM-v2, is a purpose-built 1.5-billion-parameter language model that intelligently extracts content, trained on millions of documents to understand web structure beyond simple rules.
FIgure 1: Jina Reader: a sophisticated browser automation system
Cloud Run: The engine behind Jina Reader’s scale
Jina Reader faced inherent burstiness and unpredictability of web scraping workloads. Traditional virtual machine setups meant either costly over-provisioning or critical failures under load. Google Cloud Run became the essential solution, enabling Jina Reader to build a web scraping system that is secure, reliable, massively scalable, and economically viable.
The web grounding app (the browser automation system that scrapes and cleans web content) is hosted on Cloud Run (CPU). It runs full Chrome browser instances.
ReaderLM-v2 is a purpose-built 1.5-billion-parameter language model for HTML-to-markdown conversion that runs on Cloud Run with serverless GPUs.
Cloud Run directly addressed several critical issues:
- Optimized Performance: The deep collaboration between Jina Reader and Google Cloud engineering was essential. We jointly optimized container lifecycle management for browser automation, reducing startup times from over 10 seconds to under two seconds through prewarming, optimized images, and intelligent resource allocation. For ReaderLM-v2, Google’s team helped create custom container configurations to efficiently run a 1.5-billion-parameter model on Cloud Run GPUs. The on-demand scaling and fast start capabilities of Cloud Run GPUs were critical in helping optimize model performance, directly impacting our ability to process 100 billion tokens daily.
Figure 2: On-demand AI inference with Cloud Run GPUs (hosting ReaderLM-v2 model)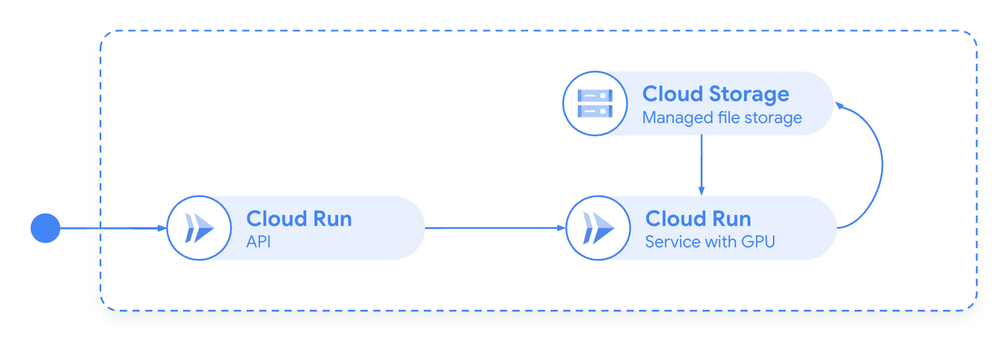
True Scale-to-Zero Serverless: Cloud Run’s ability to run full Chrome browser instances allowed cost-effective operations. Each request spawns an isolated container with its own headless Chrome, and crucially, these containers disappear when the request is done. This ephemeral nature is vital for processing untrusted web content, mitigating security risks and memory leaks.
Global Multi-Regional Deployment: Cloud Run’s global presence ensures requests are processed close to both the users and target websites. This significantly minimizes latency and boosts success rates, even against geo-restricted content.
Massive & Automatic Scaling: The platform seamlessly scales from a handful to over 1,000 container instances during peak traffic, handling the unpredictable nature of web scraping without manual intervention.
Economic Viability: With Cloud Run’s pay-per-use model, Jina Reader can offer a generous free tier to end users while maintaining profitability even with substantial monthly usage. This pricing flexibility was fundamental to our widespread adoption.
Resilience and Operational Excellence: During a recent sustained DDoS attack, Cloud Run’s serverless architecture proved invaluable. It scaled up to absorb massive loads (over 100,000 requests per minute), while intelligent rate limiting filtered malicious traffic. Critically, costs returned to normal immediately after the attack subsided due to its scale-to-zero capability. The system has maintained over 99.9% uptime.
Conclusion
Building Jina Reader on Google Cloud Run proved that AI capabilities and cloud-native architecture are complementary. Cloud Run’s unique capabilities — serverless GPUs, container isolation, global deployment and scale-to-zero economics — made the architecture possible. Our close partnership demonstrates that deep integration between AI-first systems and modern cloud infrastructure can create capabilities previously thought impossible, enabling us to process 100 billion tokens every day.
You can discover more about Cloud Run GPUs on our product page, and if you want to learn how to host a large language model on Cloud Run, watch this video.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘Try Google Cloud for free’), (‘body’, <wagtail.rich_text.RichText object at 0x3e0748320bb0>), (‘btn_text’, ‘Get started for free’), (‘href’, ‘https://console.cloud.google.com/freetrial?redirectPath=/welcome’), (‘image’, None)])]>