Almost 80% of today’s web content is user-generated, creating a deluge of content that organizations struggle to analyze with human-only processes. The availability of consumer information helps them make decisions, from buying a new pair of jeans to securing home loans. In a recent survey, 79% of consumers stated they rely on user videos, comments, and reviews more than ever and 78% of them said that brands are responsible for moderating such content. 40% said that they would disengage with a brand after a single exposure to toxic content.
Amazon Rekognition has two sets of APIs that help you moderate images or videos to keep digital communities safe and engaged.
One approach to moderate videos is to model video data as a sample of image frames and use image content moderation models to process the frames individually. This approach allows the reuse of image-based models. Some customers have asked if they could use this approach to moderate videos by sampling image frames and sending them to the Amazon Rekognition image moderation API. They are curious about how this solution compares with the Amazon Rekognition video moderation API.
We recommend using the Amazon Rekognition video moderation API to moderate video content. It’s designed and optimized for video moderation, offering better performance and lower costs. However, there are specific use cases where the image API solution is optimal.
This post compares the two video moderation solutions in terms of accuracy, cost, performance, and architecture complexity to help you choose the best solution for your use case.
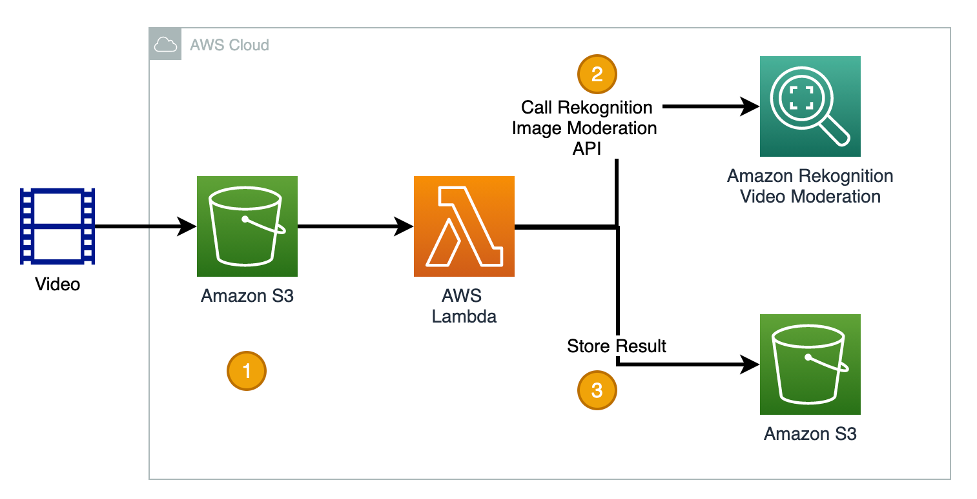
Moderate videos using the video moderation API
The Amazon Rekognition video content moderation API is the standard solution used to detect inappropriate or unwanted content in videos. It performs as an asynchronous operation on video content stored in an Amazon Simple Storage Service (Amazon S3) bucket. The analysis results are returned as an array of moderation labels along with a confidence score and timestamp indicating when the label was detected.
The video content moderation API uses the same machine learning (ML) model for image moderation. The output is filtered for noisy false positive results. The workflow is optimized for latency by parallelizing operations like decode, frame extraction, and inference.
The following diagram shows the logical steps of how to use the Amazon Rekognition video moderation API to moderate videos.

The steps are as follows:
- Upload videos to an S3 bucket.
- Call the video moderation API in an AWS Lambda function (or customized script on premises) with the video file location as a parameter. The API manages the heavy lifting of video decoding, sampling, and inference. You can either implement a heartbeat logic to check the moderation job status until it completes, or use Amazon Simple Notification Service (Amazon SNS) to implement an event-driven pattern. For details about the video moderation API, refer to the following Jupyter notebook for detailed examples.
- Store the moderation result as a file in an S3 bucket or database.
Moderate videos using the image moderation API
Instead of using the video content moderation API, some customers choose to independently sample frames from videos and detect inappropriate content by sending the images to the Amazon Rekognition DetectModerationLabels API. Image results are returned in real time with labels for inappropriate content or offensive content along with a confidence score.
The following diagram shows the logical steps of the image API solution.

The steps are as follows:
1. Use a customized application or script as an orchestrator, from loading the video to the local file system.
2. Decode the video.
3. Sample image frames from the video at a chosen interval, such as two frames per second. Then iterate through all the images to:
3.a. Send each image frame to the image moderation API.
3.b. Store the moderation results in a file or database.
Compare this with the video API solution, which requires a light Lambda function to orchestrate API calls. The image sampling solution is CPU intensive and requires more compute resources. You can host the application using AWS services such as Lambda, Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), AWS Fargate, or Amazon Elastic Compute Cloud (Amazon EC2).
Evaluation dataset
To evaluate both solutions, we use a sample dataset consisting of 200 short-form videos. The videos range from 10 seconds to 45 minutes. 60% of the videos are less than 2 minutes long. This sample dataset is used to test the performance, cost, and accuracy metrics for both solutions. The results compare the Amazon Rekognition image API sampling solution to the video API solution.
To test the image API solution, we use open-source libraries (ffmpeg and OpenCV) to sample images at a rate of two frames per second (one frame every 500 milliseconds). This rate mimics the sampling frequency used by the video content moderation API. Each image is sent to the image content moderation API to generate labels.
To test the video sampling solution, we send the videos directly to the video content moderation API to generate labels.
Results summary
We focus on the following key results:
- Accuracy – Both solutions offer similar accuracy (false positive and false negative percentages) using the same sampling frequency of two frames per second
- Cost – The image API sampling solution is more expensive than the video API solution using the same sampling frequency of two frames per second
- The image API sampling solution cost can be reduced by sampling fewer frames per second
- Performance – On average, the video API has a 425% faster processing time than the image API solution for the sample dataset
- The image API solution performs better in situations with a high frame sample interval and on videos less than 90 seconds
- Architecture complexity – The video API solution has a low architecture complexity, whereas the image API sampling solution has a medium architecture complexity
Accuracy
We tested both solutions using the sample set and the same sampling frequency of two frames per second. The results demonstrated that both solutions provide a similar false positive and true positive ratio. This result is expected because under the hood, Amazon Rekognition uses the same ML model for both the video and image moderation APIs.
To learn more about metrics for evaluating content moderation, refer to Metrics for evaluating content moderation in Amazon Rekognition and other content moderation services.
Cost
The cost analysis demonstrates that the image API solution is more expensive than the video API solution if you use the same sampling frequency of two frames per second. The image API solution can be more cost effective if you reduce the number of frames sampled per second.
The two primary factors that impact the cost of a content moderation solution are the Amazon Rekognition API costs and compute costs. The default pricing for the video content moderation API is $0.10 per minute and $0.001 per image for the image content moderation API. A 60-second video produces 120 frames using a rate of two frames per second. The video API costs $0.10 to moderate a 60-second video, whereas the image API costs $0.120.
The price calculation is based on the official price in Region us-east-1 at the time of writing this post. For more information, refer to Amazon Rekognition pricing.
The cost analysis looks at the total cost to generate content moderation labels for the 200 videos in the sample set. The calculations are based on us-east-1 pricing. If you’re using another Region, modify the parameters with the pricing for that Region. The 200 videos contain 4271.39 minutes of content and generate 512,567 image frames at a sampling rate of two frames per second.
This comparison doesn’t consider other costs, such as Amazon S3 storage. We use Lambda as an example to calculate the AWS compute cost. Compute costs take into account the number of requests to Lambda and AWS Step Functions to run the analysis. The Lambda memory/CPU setting is estimated based on the Amazon EC2 specifications. This cost estimate uses a four GB, 2-second Lambda request per image API call. Lambda functions have a maximum invocation timeout limit of 15 minutes. For longer videos, the user may need to implement iteration logic using Step Functions to reduce the number of frames processed per Lambda call. The actual Lambda settings and cost patterns may differ depending on your requirements. It’s recommended to test the solution end to end for a more accurate cost estimation.
The following table summarizes the costs.
| Type | Amazon Rekognition Costs | Compute Costs | Total Cost |
| Video API Solution | $427.14 | $0 (Free tier) | $427.14 |
| Image API Solution: Two frames per second | $512.57 | $164.23 | $676.80 |
| Image API Solution: One frame per second | $256.28 | $82.12 | $338.40 |
Performance
On average, the video API solution has a four times faster processing time than the image API solution. The image API solution performs better in situations with a high frame sample interval and on videos shorter than 90 seconds.
This analysis measures performance as the average processing time in seconds per video. It looks at the total and average time to generate content moderation labels for the 200 videos in the sample set. The processing time is measured from the video upload to the result output and includes each step in the image sampling and video API process.
The video API solution has an average processing time of 35.2 seconds per video for the sample set. This is compared to the image API solution with an average processing time of 156.24 seconds per video for the sample set. On average, the video API performs four times faster than the image API solution. The following table summarizes these findings.
| Type | Average Processing Time (All Videos) | Average Processing Time (Videos Under 1.5 Minutes) |
| Video API Solution | 35.2 seconds | 24.05 seconds |
| Image API Solution: Two frames per second | 156.24 seconds | 8.45 seconds |
| Difference | 425% | -185% |
The image API performs better than the video API when the video is shorter than 90 seconds. This is because the video API has a queue managing the tasks that has a lead time. The image API can also perform better if you have a lower sampling frequency. Increasing the frame interval to over 5 seconds can decrease the processing time by 6–10 times. It’s important to note that increasing intervals introduces the risk of missed identification of inappropriate content between frame samples.
Architecture complexity
The video API solution has a low architecture complexity. You can set up a serverless pipeline or run a script to retrieve content moderation results. Amazon Rekognition manages the heavy computing and inference. The application orchestrating the Amazon Rekognition APIs can be hosted on a light machine.
The image API solution has a medium architecture complexity. The application logic has to orchestrate additional steps to store videos on the local drive, run image processing to capture frames, and call the image API. The server hosting the application requires higher computing capacity to support the local image processing. For the evaluation, we launched an EC2 instance with 4 vCPU and 8 G RAM to support two parallel threads. Higher compute requirements may lead to additional operation overhead.
Optimal use cases for the image API solution
The image API solution is ideal for three specific use cases when processing videos.
The first is real-time video streaming. You can capture image frames from a live video stream and send the images to the image moderation API.
The second use case is content moderation with a low frame sampling rate requirement. The image API solution is more cost-effective and performant if you sample frames at a low frequency. It’s important to note that there will be a trade-off between cost and accuracy. Sampling frames at a lower rate may increase the risk of missing frames with inappropriate content.
The third use case is for the early detection of inappropriate content in video. The image API solution is flexible and allows you to stop processing and flag the video early on, saving cost and time.
Conclusion
The video moderation API is ideal for most video moderation use cases. It’s more cost effective and performant than the image API solution when you sample frames at a frequency such as two frames per second. Additionally, it has a low architectural complexity and reduced operational overhead requirements.
The following table summarizes our findings to help you maximize the use of the Amazon Rekognition image and video APIs for your specific video moderation use cases. Although these results are averages achieved during testing and by some of our customers, they should give you ideas to balance the use of each API.
| . | Video API Solution | Image API Solution |
| Accuracy | Same accuracy | . |
| Cost | Lower cost using the default image sampling interval | Lower cost if you reduce the number of frames sampled per second (sacrifice accuracy) |
| Performance | Faster for videos longer than 90 seconds | Faster for videos less than 90 seconds |
| Architecture Complexity | Low complexity | Medium complexity |
Amazon Rekognition content moderation can not only help your business protect and keep customers safe and engaged, but also contribute to your ongoing efforts to maximize the return on your content moderation investment. Learn more about Content Moderation on AWS and our Content Moderation ML use cases.
About the authors
 Lana Zhang is a Sr. Solutions Architect at the AWS WWSO AI Services team, with expertise in AI and ML for content moderation and computer vision. She is passionate about promoting AWS AI services and helping customers transform their business solutions.
Lana Zhang is a Sr. Solutions Architect at the AWS WWSO AI Services team, with expertise in AI and ML for content moderation and computer vision. She is passionate about promoting AWS AI services and helping customers transform their business solutions.
 Brigit Brown is a Solutions Architect at Amazon Web Services. Brigit is passionate about helping customers find innovative solutions to complex business challenges using machine learning and artificial intelligence. Her core areas of depth are natural language processing and content moderation.
Brigit Brown is a Solutions Architect at Amazon Web Services. Brigit is passionate about helping customers find innovative solutions to complex business challenges using machine learning and artificial intelligence. Her core areas of depth are natural language processing and content moderation.