In our previous blog post, we presented Wayfair’s MLOps vision and how we implemented it within our Data Science & Machine Learning organization using Vertex AI, supported by tooling that we built in-house and state-of-the-art MLOps processes. We shared our MLOps reference architecture that includes a shared Python library that we built to interact with Vertex AI, as well as a CI/CD architecture to support continuously building and deploying Vertex AI solutions.
In this blog post, we will discuss how we applied said tools and processes in a high-impact, real-world project: a replatforming effort within the Supply Chain Science team to solve issues that had arisen with legacy technologies and modernize our tech stack as well as processes.
Our Supply Chain Science team is working on several projects that use machine learning to provide predictive capabilities for use cases such as delivery-time prediction, incidence-costs prediction or supply-chain simulation that enable a best-in-class customer experience. In particular, we focused on our delivery-time prediction project that aims to use machine learning to predict the time it takes for a product to reach a customer from the supplier.
While we migrated the project to Vertex AI at a rather late stage of the project, it has proven to play a crucial role in enabling further rapid development of the ML model, as well as significantly reducing our maintenance efforts and improving the reliability of our core systems, including data ingestion, model training, and model inference.
Empowering scientists to build world-class ML models
Besides conducting ad-hoc data analysis and experiments in notebook environments, one of the most crucial parts of data scientists’ work at Wayfair revolves around orchestrating their models, experiments and data pipelines, which has traditionally been done on a central self-hosted Apache Airflow server that was shared among all data science teams across the company. This caused several issues including slow delivery processes and noisy neighbor problems, effectively forcing scientists to dedicate significant amounts of time dealing with these issues instead of focusing on building ML models.
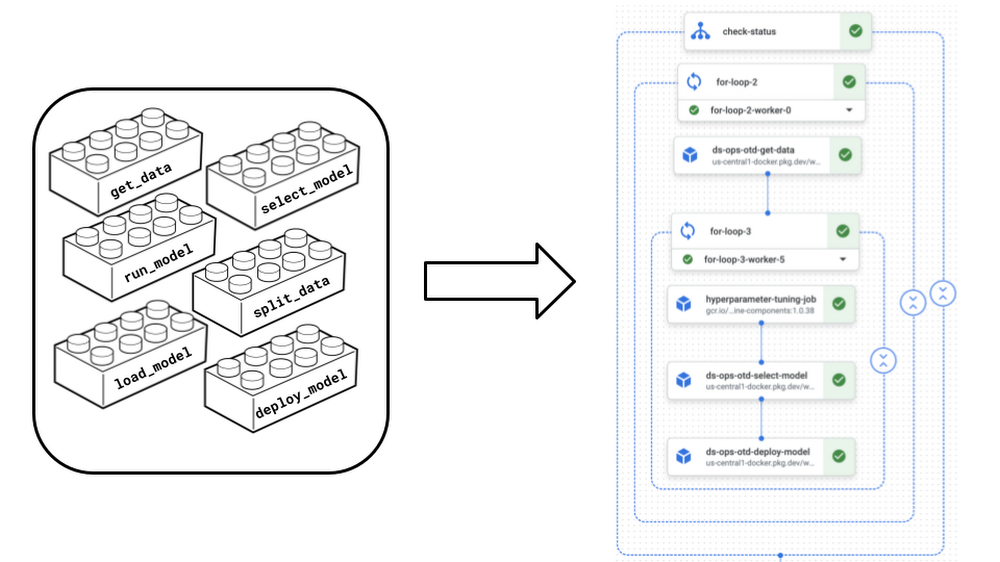
To ease this pain and simultaineously enable new capabilities, we migrated to Kubeflow-based Vertex AI Pipelines for orchestration while leveraging the internal tooling we built on top of Vertex AI that improves usability and integrates nicely with our existing systems. We migrated all of the team’s pipelines to Vertex AI Pipelines, including data ingestion, model training, model evaluation, and model inference pipelines while leveraging Kubeflow’s capabilities to build custom components and share them across pipelines. This allowed us to build and manage custom components for common operations centrally within our team and use them to compose pipelines, just like taking a box of Legos and composing the same bricks in creative ways to build awesome things. This way of establishing and re-using common pipeline components effectively reduced code duplication, improved maintainability, and increased collaboration between different projects and even teams.
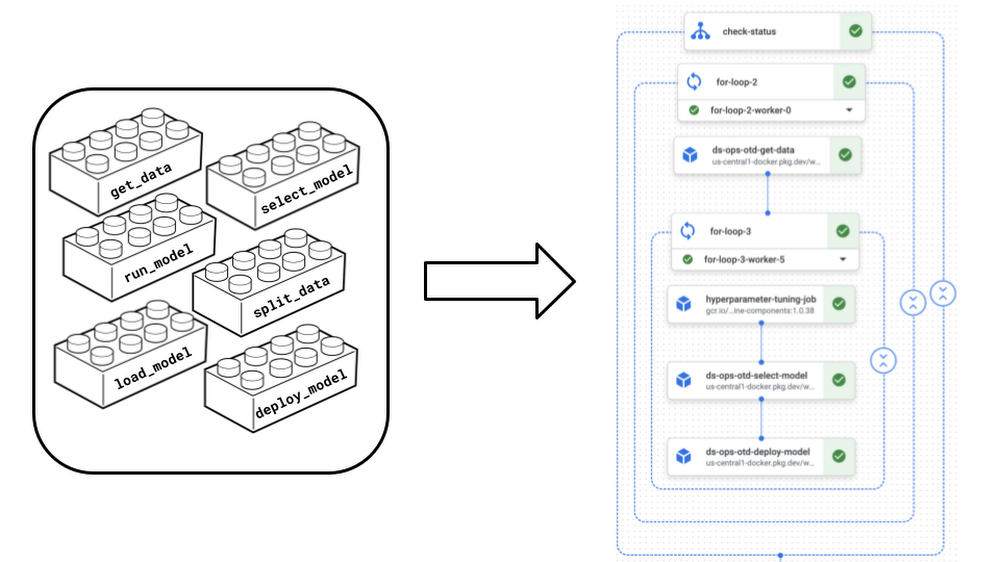
Our transition to Vertex AI Pipelines resolves one of the biggest pain points that our scientists faced with the legacy Airflow-based solution: slow and manual release processes. Instead of having to go through the process in the shared “monorepo,” scientists in our team can now autonomously manage releases, which after approval and subsequent merge get linted, tested, compiled, and deployed automatically. This significantly reduced time-to-value and allowed for much faster iteration cycles. Additionally, the isolated execution environments that Vertex AI Pipelines offers provide much higher stability and reliability and prevent noisy neighbor problems that often arose with our centralized legacy solution, which shared compute infrastructure between pipelines.
We also took the opportunity to gather our project-specific needs and refine some aspects of generic tooling across the company. For example, instead of having one Vertex AI pipeline per repository, we manage all projects’ pipelines centrally within a single model repository, using the same CI/CD capabilities that we enjoy with Vertex AI.
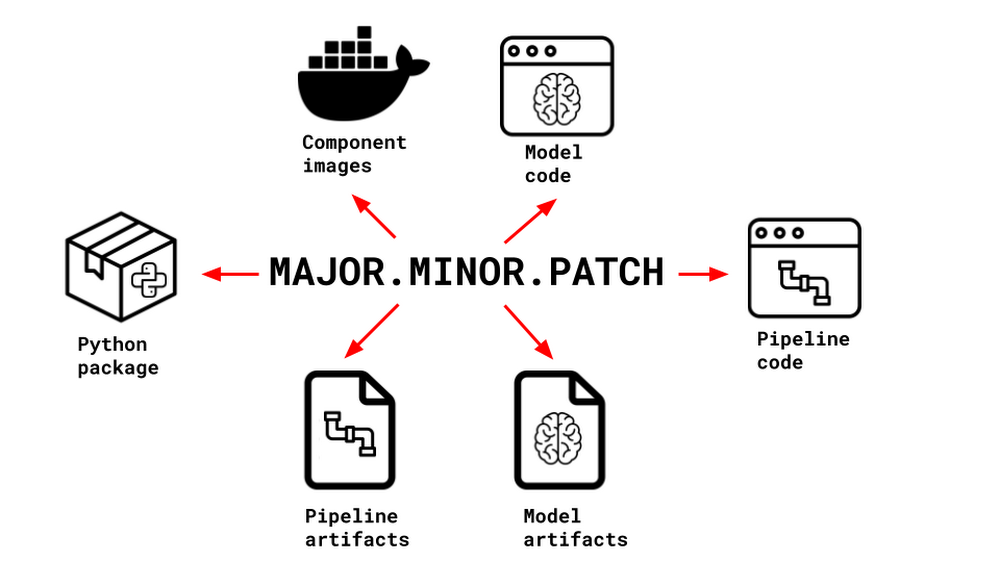
Another problem specific to our delivery time prediction project was the lack of traceability and reproducibility due to different versioning standards between different components of the system. It was essentially impossible to track and trace which version of the model code ran in which version of the pipeline code, and produced which set of model artifacts. With the help of Vertex AI Pipelines, we have solved this fundamental problem by introducing the concept of unified semantic versioning. Instead of having different (or no) versioning standards within the project, now all pieces of code and all artifacts are consistently versioned sharing the same semantic version, creating a clear link between them that, coupled with diligent change logging, allows us to trace back code and artifacts and confidently infer the state of the system at any point in time.
Unified semantic versioning was only possible because Vertex AI Pipelines is naturally compatible with MLOps processes such as continuous integration and continuous delivery: the combination of pipeline definition, components and base images gets compiled to a single JSON artifact that can be easily integrated into CI/CD workflows.
Finally, as part of the replatforming effort, we introduced several other miscellaneous architectural changes and best practices, such as clearly separated development and production environments, and decoupling of generalizable modules to a team-wide shared repository.
Lessons learned
At the end of the day, from a technical perspective, we expanded Wayfair’s MLOps capabilities to support multiple Vertex AI pipelines in a single project repository, providing additional pre-built Vertex AI Pipeline components for everyone in the company to use, and setting up a system architecture that is built around traceability and reproducibility by jointly versioning all code and artifacts in a unified way. Replatforming to Vertex AI helped make our workflows significantly more efficient and robust, and gave scientists full autonomy over their pipelines and release processes, removing dependencies on other teams and external processes and improving the team’s agility and lowering time-to-value.
Besides having a direct impact on our team, applying MLOps tools and best practices also led to further development and contributed back to our inner-sourced company-wide tools and processes, unlocking further capabilities and improving our development experience with Vertex AI.
To continue in the same direction, we are currently working on onboarding Vertex AI Feature Store to give the team autonomy over their feature pipelines and storage, as well as continuing to evaluate other Vertex AI services such as Model Registry and Endpoints.
To learn more about the impact the transition has had on the day-to-day work of our data scientists, read our next blog post about our work with Vertex AI in Supply Chain Science.