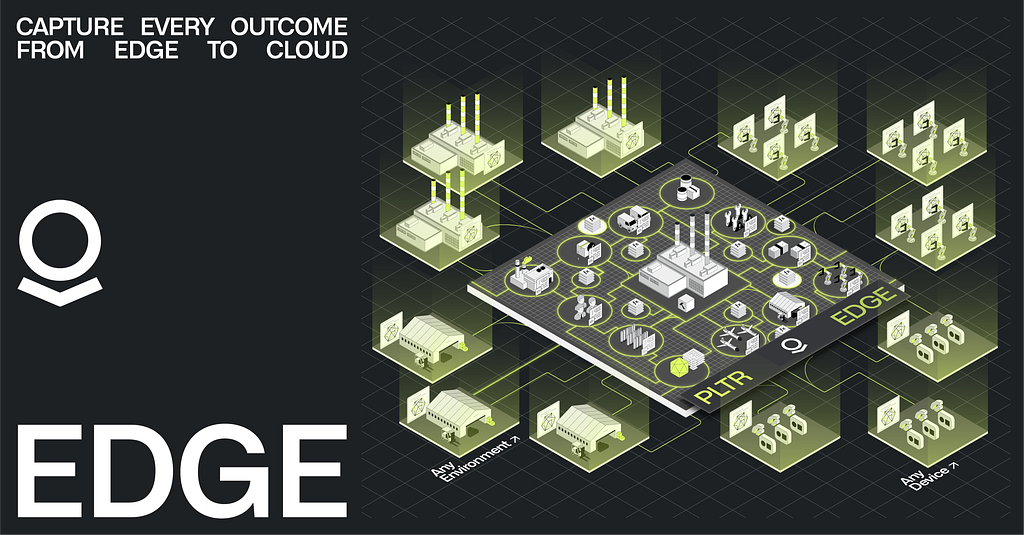
Industrial and defense environments generate massive amounts of data that can’t wait for the cloud. Latency is often measured in milliseconds, and resiliency is paramount. A manufacturing plant can’t go down due to flaky Wi-Fi or a public cloud outage. “Traditional” approaches — shipping servers, hiring local IT, bespoke development, managing one-off deployments — simply don’t scale. Critical operations require infrastructure that is purpose-built for complexity at the edge.
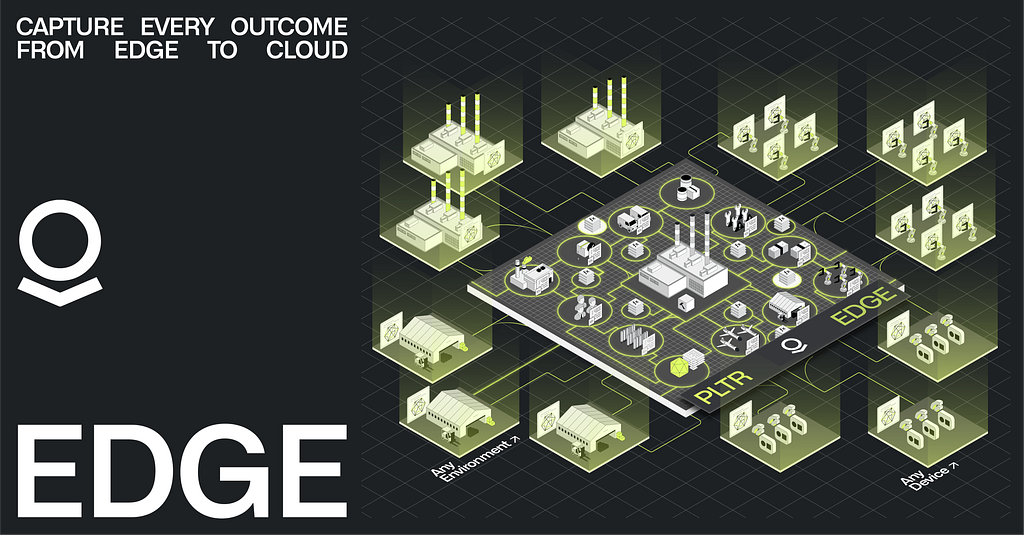
In the era of AI-enabled automation, the challenge isn’t building one edge device; it’s operating hundreds or thousands of devices, consistently and securely, without dedicated IT teams at every site. This requires a holistic architecture that spans three core dimensions:
- Data: Aggregating structured and unstructured streams from sensors like video, PLC(s), SCADA , MES(s), PLM(s), ERP(s) etc. into a unified namespace, which is accessible in real-time.
- Logic: Processing and analyzing that data locally, turning it into actionable intelligence for production control, material scheduling, real-time process optimization, quality inspection, predictive maintenance and more.
- Action: Closing the loop through automated responses and write-back, which respect granular guardrails and can interface with workflows happening across other environments.
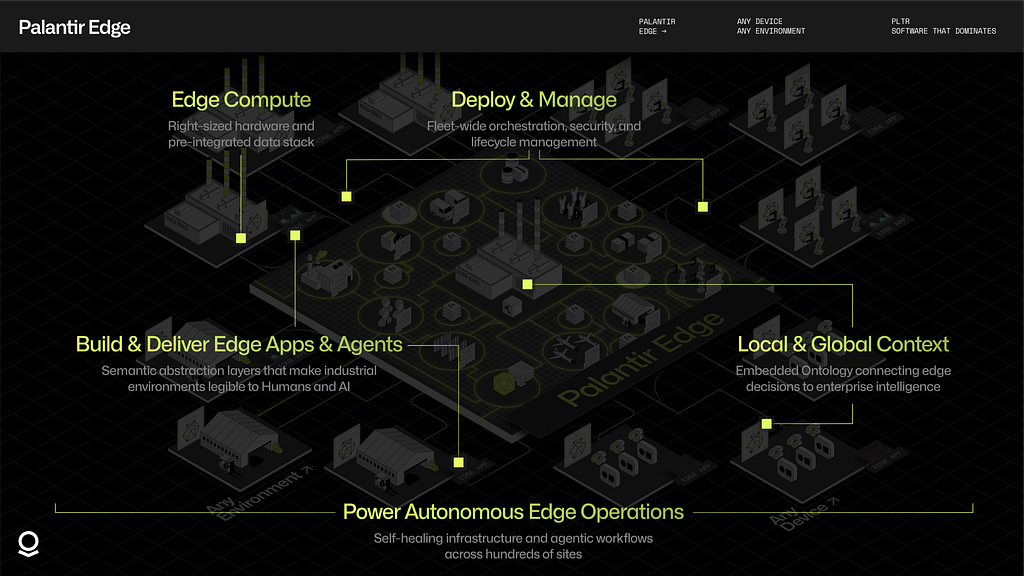
Functionally, the edge infrastructure for mission-critical operations can be segmented into five interlocking categories, which span the traditional boundaries between information technology (IT) and operational technology (OT):
- Edge Compute — right-sized hardware that powers a pre-integrated data stack
- Deploy & Manage — fleet-wide orchestration, security, and lifecycle management
- Local / Global Context — Embedded Ontology connecting edge decisions to enterprise intelligence
- Rapid Application Development — flexible toolchains that enable building against the enterprise model
- Autonomous Operations at Scale — self-healing infrastructure and agentic workflows that scale to hundreds of sites
These categories must be integrated and governed within an enterprise architecture that works across human teams, AI agents, devices, and environments.
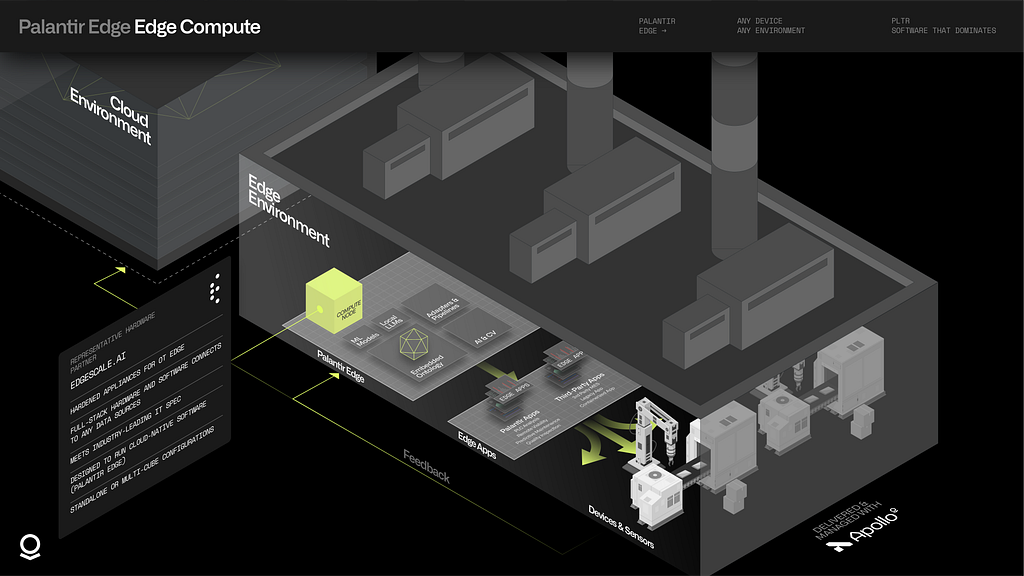
Edge Compute
Industrial environments generate massive volumes of data — from PLCs and sensors to vision systems and diagnostic equipment. Most of this data never leaves the factory floor. It is too large to backhaul, too latency-sensitive to round-trip to the cloud, and too operationally critical to depend on connectivity that may not exist.
At Palantir, we built our edge infrastructure for this reality.
In tandem with infrastructure partners, Palantir provides packaged compute, storage, and GPU acceleration into form factors that scale from industrial PCs to 3U rack-mounted servers, with connectivity spanning wired, wireless, and 5G cellular. The cellular channel is isolated for out-of-band management, and kept completely separate from production data.
What ships isn’t bare metal waiting to be configured, but a foundation centered around the Embedded Ontology — a lightweight, edge-native instantiation of Palantir’s Ontology that is designed to operate independently at each site. The platform includes a pre-integrated stack for time-series, relational, and object storage, along with local LLM and vector search capabilities for AI workloads. Industrial protocol adapters are pre-configured, with native support for message brokering, automatic tag discovery, and third-party compatibility. Data flows from ingestion to Ontology and ultimately to ROI-generating applications and services.
The edge environment operates independently, but stays connected to the cloud when bandwidth and connectivity allow. Models, configurations, and application updates push down from Foundry and AIP. Operational feedback, including refined datasets, performance telemetry, and edge-generated insights, flows back up. This means teams in a central operations center and teams on the plant floor work from the same ontology, with the edge acting as a local execution layer rather than a disconnected silo.
Beyond streaming data, the platform integrates with on-premises and cloud systems — merging data from ERP, CRM, MES, and SaaS applications. It supports unstructured data such as images, video, engineering schematics, training materials, and process specifications. This data is integrated into robust processing pipelines to create a comprehensive digital twin of operations — a key differentiator from architectures that require stitching together solutions to connect to these sources.
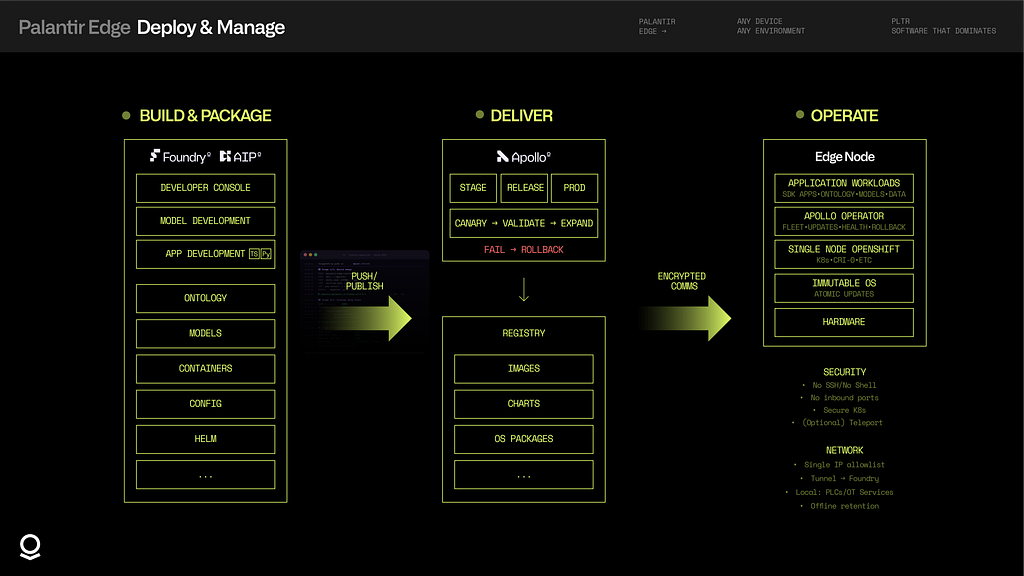
Deploy & Manage
Conventional edge infrastructure fails in predictable ways. Configuration drift accumulates. Updates break things. Networks partition. Someone accesses the system via SSH and pushes an undocumented change. These aren’t corner cases — they’re the default state of traditional deployments at scale.
Palantir takes a different approach. Our edge platform runs Single Node OpenShift (SNO) on an immutable operating system where the OS state is the build artifact — not a server that’s been hand-configured over months. Updates are atomic transactions that complete fully or roll back cleanly, with no partial states to debug.
Fleet management runs through Apollo, flowing container images, Helm charts, and OS updates from a central registry to edge devices via encrypted communications. Deployments use a “canary paradigm” by default: roll out to one device, validate health checks, and then expand. If something fails, it rolls back automatically — no stale runbooks, no 3 AM pages. Apollo supports release channels such as staging, release, and production to manage risk tolerance across air-gapped environments. Each edge node runs an Apollo Operator that manages fleet coordination, health checks, updates, and rollback locally.
Applications are built and packaged within AIP and Foundry using the Developer Console, model development tools, and standard app development workflows. Artifacts including containers, Helm charts, Ontology definitions, and model configs are published to a central registry for Apollo to distribute.
Security is zero-trust by design, not bolted on after the fact. There is no SSH access, no shell, and no exposed Kubernetes API. Edge devices initiate all connections outbound with no inbound ports ever exposed. Full observability and control, without compromising security.
Customer IT only whitelists one IP. Internet-bound traffic routes through managed secure tunnels; factory-local traffic (PLCs, sensors, MQTT) stays on-premises. When support access is needed, there are audited, time-limited sessions without VPN tunnels or firewall changes.
The platform is designed to manage itself: zero-downtime updates for software and model deployments without stopping data collection; predictive self-maintenance monitoring disk, memory, and database performance; and no ongoing local IT required to carry out core operations. Data retention ensures that if network access is lost, data can be safely pushed to Foundry once the connection is restored. Many of our customers are accelerating their deployments with our partners, such as Edgescale AI.
Local / Global Context
Data at the edge is only useful if it can be understood in context — both locally for real-time decision-making and globally as part of a broader operational picture.
Palantir’s edge platform runs an Embedded Ontology that models the relationships between physical assets, sensor streams, and operational events. This isn’t a static schema but a live representation of the environment that applications can query, update, and act upon. The Ontology connects Data, Logic, and Action into a decision-centric representation, allowing both humans and AI to interact with operations without needing deep knowledge of underlying data technologies or programming languages. Applications access the embedded ontology through the familiar OSDK APIs, providing a consistent interface whether querying assets, or triggering write back to PLCs and SCADA systems. For example, a quality inspection application defines which ontology objects to sync, then queries them locally:
import { Line, Sensor, Defect } from "@vision-inspection/sdk";
import { createClient } from "@osdk/client";
const client: Client = createClient(
foundryUrl,
ontologyRid,
auth,
{ syncObjects: [Line, Sensor, Defect] }
);
// Query defects on a specific line
const defects = await client.objects.Defect
.where({ line: "line-01", severity: "critical" })
.fetchPage();
// Act on results - trigger PLC rejection
for (const defect of defects.data) {
await client.actions.rejectPart({ partId: defect.partId });
}Once synchronized, the application queries and acts on these objects locally with full offline support, regardless of connectivity to Foundry.
CRUD operations and actions execute locally with millisecond latency, independent of cloud connectivity. When connectivity exists, local context synchronizes with the global Ontology in Foundry/AIP, where it can seamlessly power agent-based automation and optimization across the enterprise. When there is no connectivity, the edge operates autonomously — buffering changes, resolving conflicts, and reconciling state when the link restores. Resiliency isn’t a feature; it’s the baseline assumption. Edge nodes can also peer with each other, enabling cross-site coordination without routing through the cloud.
Often, to capture the full value of a process, the system must operate seamlessly between edge and cloud. An application serving shop floor technicians at a single site produces outputs that matter across the enterprise. Being able to deploy the right part of the workflow to the right environment using the same set of tools is essential. For example, an alert generated at the edge can be automatically triaged by a machine or plant technician augmented by AI. The resulting signal and operator actions and any additional context are seamlessly synchronized with cloud-side ontology for macro root-cause analysis, cross-plant materials comparison, etc. This seamless operation is enabled by extending Ontology to the edge; one model, two environments, and a unified context. Custom models and services run alongside the Ontology, consuming its data and writing results back, while the underlying infrastructure, including the Apollo Operator, SNO, and immutable OS, remains abstracted away for application developers.

Rapid Application Development and Delivery
The generative AI revolution has transformed what’s possible — but in industrial environments, possibility is dependent on operational reality. Models that reason, generate, and decide are only valuable if they can connect to the physical world: reading from sensors, understanding process context, and triggering actions on real equipment.
The hard part of edge development isn’t writing application logic — it’s everything else. Connecting to industrial protocols; managing credentials; handling intermittent connectivity; deploying updates without downtime. Doing all of this across hundreds or thousands of locations.
Palantir abstracts the complexity of building applications for the edge. Protocol adapters for OPC UA, MQTT, and more come pre-configured. The ontology provides a consistent API regardless of the underlying equipment, so developers build against the abstraction rather than the idiosyncrasies of individual sites. The same abstraction that simplifies development for human engineers makes industrial environments legible to AI — models query, reason, and act through governed interfaces. Deployments flow through the same Apollo pipeline that manages the platform itself — versioned, tested, rolled out incrementally, and rolled back automatically if health checks fail. Models run with GPU acceleration where available, using standard runtimes like ONNX. The result is a development experience closer to cloud-native than traditional industrial software, running on infrastructure that doesn’t require cloud connectivity to function.
Pro-code and low-code options make application development as simple as building an OSDK application for the browser or mobile. Let’s go step-by-step through the process of building a quality control application using computer-vision that integrates with PLCs to remove defective components from the production line.
For the purposes of readability and brevity, the code will be in TypeScript/JavaScript — but can be whichever language or framework is aligned with the non-functional requirements of the use case.
- Capture Image: A high-resolution camera captures images of each part as it moves through the line.
import { client } from "./client";
import { Line, Part, Inspection, Defect } from "@vision-inspection/sdk";
import { subscribe } from "@palantir/edge-adapters/opcua";
import { grabFrame } from "@palantir/edge-adapters/gige-vision";
import { runModel } from "@palantir/edge-runtime/inference";
const line = await client.objects.Line.get("line-01");
// PLC triggers frame grab when part reaches station
subscribe(line.plcEndpoint, "ns=2;s=PartReady", async ({ partId }) => {
const frame = await grabFrame(line.cameraEndpoint, {
exposure: "auto",
resolution: [2048, 2048],
});2. Ingest & Normalize: Edge node ingests & normalizes the images alongside time-series data from sensors and PLCs.
// Enrich frame with sensor context
const part = await client.objects.Part.get(partId);
const sensors = await client.objects.Sensor
.where({ line: line.id })
.fetchPage();
const input = {
image: frame.buffer,
partType: part.partType,
temperature: sensors.data[0]?.temperature,
lineSpeed: sensors.data[0]?.lineSpeed,
};
3. Model Inference: A CV model runs inference locally, classifying each part and detecting defects.
// Run CV model locally (GPU-accelerated)
const result = await runModel("defect-classifier-v3“, input);
4. Decision & Action: The application decides what to do: pass the part and continue the line, or trigger an actuator to reject it. Every inspection is logged as an Ontology event accessible through OSDK APIs.
// Reject part and save results for QA & model refinement
const inspection = await client.actions.createInspection({
partId,
line: line.id,
classification: result.label,
confidence: result.confidence,
imageRef: frame.storageRef,
});
if (result.label === "defect") {
await client.actions.createDefect({
inspectionId: inspection.id,
partId,
defectType: result.defectType,
confidence: result.confidence,
});
await client.actions.rejectPart({
partId,
actuator: line.rejectActuatorId,
});
}
});
The same code can handle all lines or be replicated to IPC(s) across Line 2, Line 3, through Line N, all managed from a single Apollo deployment. Meanwhile: results sync to Foundry/AIP for cross-line analytics, model retraining, defect dashboards, and integration with IT/OT systems like PLM, ERP, and MES. Pro-code and low-code options make this as simple as building a OSDK application for the browser or mobile using a PWA.

This is just one example from a wide spectrum of possible applications — from simple statistical process control and threshold alerting to sophisticated multi-modal AI that combines vision, sensor data, and historical context to drive autonomous decision-making.
Autonomous Operations at Scale
Operating edge infrastructure at a single site is manageable. Operating it across hundreds of factories — each with different equipment, network conditions, and operational constraints — requires a fundamentally different approach. The platform must manage itself.
With Palantir’s edge architecture, software and model deployments occur continuously, without stopping data collection. Near-zero downtime is the default, not a special case. The platform monitors its own health — disk usage, memory pressure, database performance — and self-optimizes before issues become incidents. When something does go wrong, self-healing operators execute automated remediation without waiting for human intervention.
Fleet-wide observability surfaces telemetry across every device, every site, in a single pane of glass. Operators see not just what’s happening at one factory, but patterns emerging across the entire fleet — which sites are drifting, which deployments are underperforming, which models need retraining. This isn’t monitoring for the sake of dashboards. It’s the foundation for continuous improvement at scale.
Minimal IT support is required. No on-site engineers babysitting servers. No per-factory operations teams. The hard problems — integration, security hardening, update orchestration, remediation — are solved once in the build pipeline and replicated identically across every deployment. What works at factory one works at factory 200; what’s learned at factory 200 improves factory one.
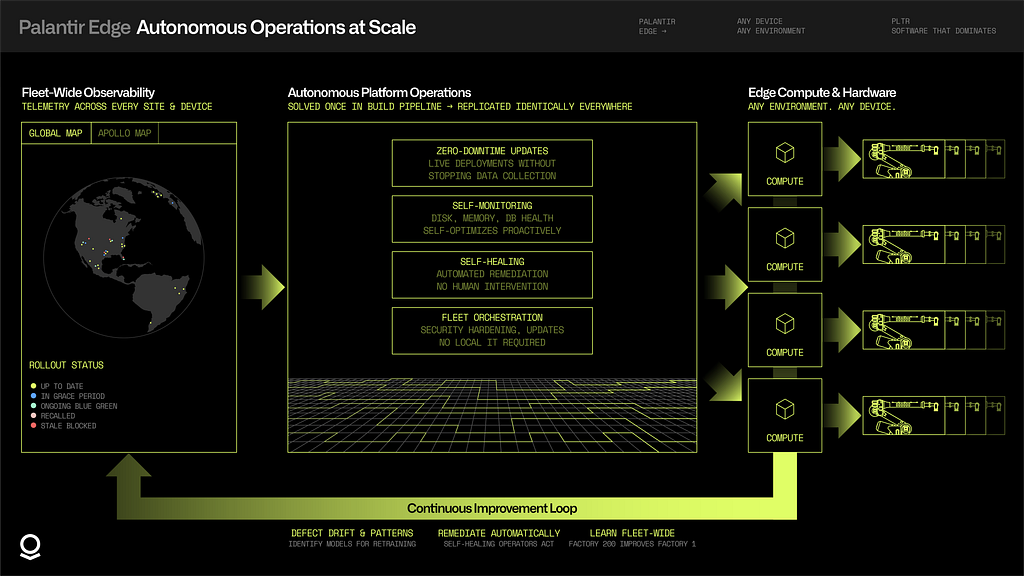
The edge must exist in a virtuous loop with the wider enterprise. The edge is where operations happen — where sensors fire, machines run, and decisions must be made in milliseconds. But the value of edge infrastructure only compounds when it connects to the whole.
Local actions execute autonomously at each site: a model detects an anomaly, triggers an alert, adjusts a process parameter — all without waiting for a round-trip to the cloud. The Embedded Ontology ensures these decisions are grounded in real-time context. When connectivity exists, that context flows upstream.
At the plant level, data from across production lines aggregates into a unified operational picture. Maintenance teams see which equipment is trending toward failure across the entire facility. Quality engineers correlate defects to specific batches, shifts, or environmental conditions. Plant managers run what-if scenarios against a digital twin built from live data.
At the enterprise level, patterns emerge that no single site could reveal. Performance benchmarks across hundreds of factories surface best practices and outliers. Supply chain signals propagate from shop floor to planning systems in near real-time. Models trained on fleet-wide data deploy back to the edge, smarter than any single-site model could be. AI agents operating in the cloud coordinate across sites: optimizing supply chains, rebalancing workloads, retraining models — while agents at the edge handle local decisions in real-time.
The global Ontology serves as the connective tissue — linking local actions to enterprise intelligence, and ensuring that enterprise learnings flow back to local decision-making.
Related Video: The Embedded Ontology connects AI with operations at the edge.
![]()
Manufacturing with the Connected Edge was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.