Over the last 10 years, a number of players have developed autonomous vehicle (AV) systems using deep neural networks (DNNs). These systems have evolved from simple rule-based systems to Advanced Driver Assistance Systems (ADAS) and fully autonomous vehicles. These systems require petabytes of data and thousands of compute units (vCPUs and GPUs) to train.
This post covers build approaches, different functional units of ADAS, design approaches to building a modular pipeline, and the challenges of building an ADAS system.
DNN training methods and design
AV systems are built with deep neural networks. When it comes to the design of an AV system, there are two main approaches. The difference is based on how the DNNs are trained and the system boundary.
- Modular training – With a modular pipeline design, the system is split into individual functional units (for example, perception, localization, prediction, and planning). This is a common design paradigm used by many AV system providers. With the whole system split into individual modules, they can be built and trained independently.
- End-to-end training – This approach involves training a DNN model that takes raw sensor data as input and outputs the driving command. This is a monolithic architecture and is mainly explored by researchers. The DNN architecture is typically based on reinforcement learning (RL) based on a reward/penalty system or imitation learning (IL) by observing a human driving the vehicle. Although the overall architecture is simple, it’s hard to interpret and diagnose the monolith. However, annotations are cheap because the system learns from the data collected through human behavior.
In addition to these two approaches, researchers are also exploring a hybrid approach that trains two different DNNs that are connected by an intermediate representation.
This post explains the functions based on a modular pipeline approach.
Automation levels
The SAE International (formerly called as Society of Automotive Engineers) J3016 standard defines six levels of driving automation, and is the most cited source for driving automation. This ranges from Level 0 (no automation) to Level 5 (full driving automation), as shown in the following table.
| Level | Name | Feature |
| 0 | No Driving Automation | Human drives |
| 1 | Driving assistance | Human drives |
| 2 | Partial driving automation | Human drives |
| 3 | Conditional driving automation | System drives with human as backup |
| 4 | High driving automation | System drives |
| 5 | Full driving automation | System drives |
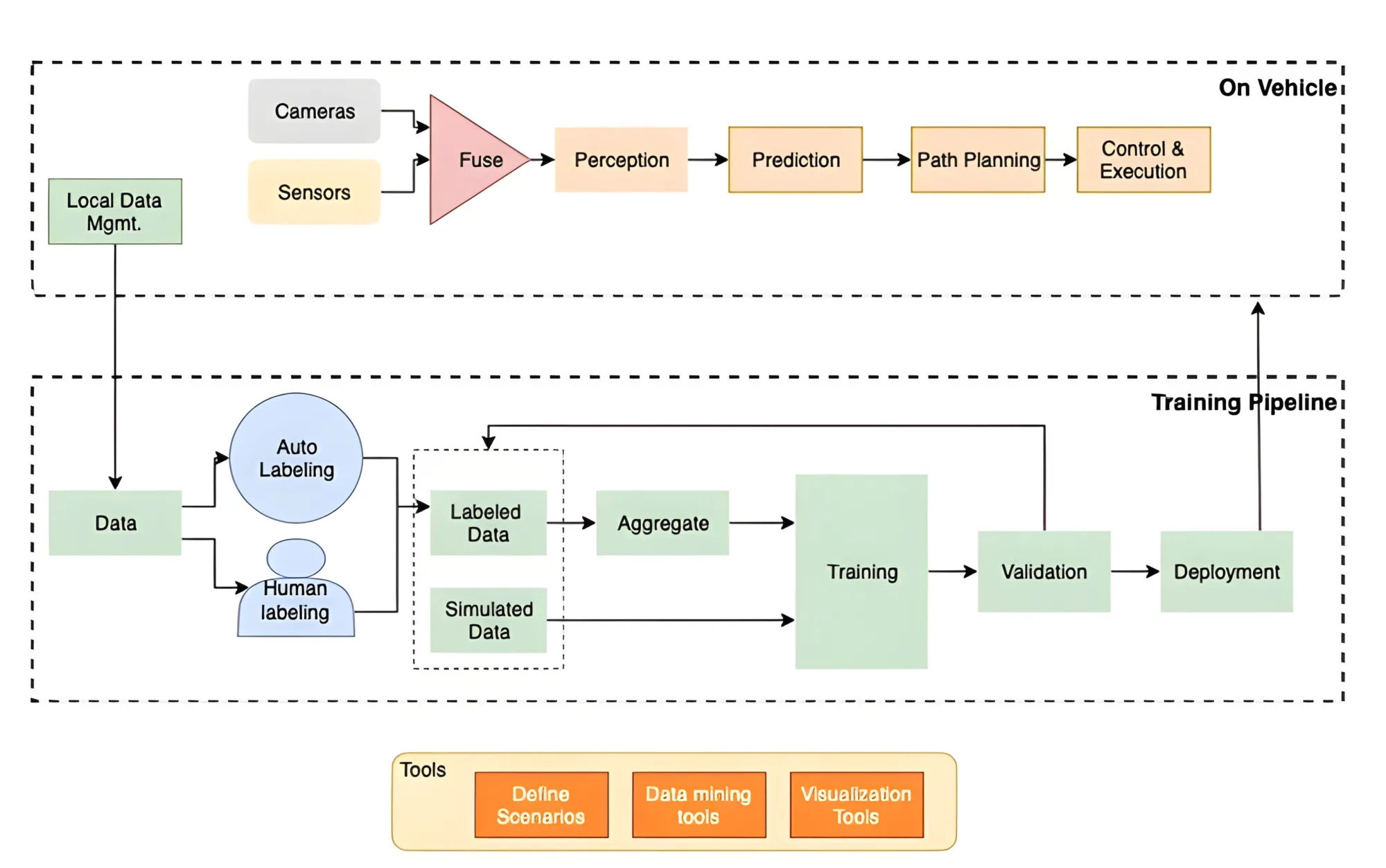
Modular functions
The following diagram provides an overview of a modular functions design.

At the higher levels of automation (Level 2 and above), the AD system performs multiple functions:
- Data collection – The AV system gathers information about the vehicle’s surroundings in real time with centimeter accuracy. The vehicle is equipped with various devices, and the functions of these devices vary and intersect in a number of ways. AV is still an evolving space and there is no consensus and standardization of types of sensors and devices attached. In addition to the devices listed here, vehicles might also have GPS for navigation, and use maps and Inertial Measurement Units (IMUs) to measure linear and angular acceleration. Depending on the type of ADAS system, you will see a combination of the following devices:
- Cameras – Visual devices conceptually similar to human perception. Supports high resolution but bad at depth estimation and handling extreme weather conditions.
- LiDAR – Expensive devices providing data about the surroundings as a 3D point cloud. Provides accurate depth and speed estimation.
- Ultrasonics – Small, inexpensive sensors but works well only in short ranges.
- Radar – Supports long and short ranges and works well in low visibility and extreme weather conditions.
- Data fusion – Multiple devices that are part of the AV system provide signals but have their limitations; however, signals across the devices provide complementary information. AV systems fuse data from the devices that are integrated together to build a comprehensive perception. This integrated dataset is used to train the DNN.
- Perception – AV systems analyze the raw data collected from the devices to construct information about the environment around the vehicle, including obstacles, traffic signs, and other objects. This is called road scene perception or simply perception. It involves detecting the objects and classifying them as nearby vehicles, pedestrians, traffic lights, and traffic signs. This function measures depth and performs lane detection, lane curvature estimation, curb detection, and occlusion. This information is key for path planning and route optimization.
- Localization and mapping – To operate and optimize vehicle safely, the AV systems need an understanding of the location of the objects detected by perception. The AV system constructs a 3D map and updates the position of the host vehicle (ego vehicle) and its surroundings in the map. It tracks the detected objects and their current location. Advanced systems predict the kinematics of the objects that are in motion.
- Prediction – With the information collected from other modules, AV systems predict how the immediate future of the environment is going to change. The DNN running on the vehicle predicts the position of the ego vehicle and the surrounding object interactions by projecting the kinematic states over time (position, velocity, acceleration, jerk). It can predict potential traffic violations and collisions or near collisions.
- Path planning – This function is responsible for drawing out the possible routes the vehicle can take as the next action based on inputs from perception, localization, and prediction. To plan the best possible route, the AV system takes localization, maps, GPS data, and predictions as input. Some AV systems construct a bird’s-eye view by projecting kinematics of the ego vehicle and other objects onto a static route to provide a 3D map. Some also fuse data from other vehicles. Overall, the planning function finds the optimal route from all the possible ones with a goal to maximize driver comfort (for example, smooth turns vs. sharp turns, slow down vs. stop abruptly at stop signs).
- Control and execution – Takes the input from the route planner to perform actions to accelerate, decelerate, stop, and rotate the steering wheel. The goal of the controller is to maintain the planned trajectory.
- Training pipeline – DNNs providing predictions on the vehicle need to be trained. They are typically trained in an offline fashion with data collected from the vehicles. Training requires thousands of compute units for an extended period of time. The amount of data required to train and the required compute power varies based on the model architecture and the AV system provider. To train the DNNs, the AV system provider requires labeled data that is partly annotated by humans and partly automated. Typically, personally identifiable information (PII) such as license plate number and face are anonymized via blurring. Many providers augment the labeled data with simulation. It provides the ability to generate data for specific scenarios and augment real-world data. AV system providers also utilize tools to mine relevant data for training, fine-tuning, and handling edge cases. The trained models are validated for accuracy with offline simulation. Some providers use a dormant model strategy and deploy candidate models (dormant) side by side with the production models. Although predictions from the dormant models aren’t used to control the vehicle, it helps the providers validate the model’s accuracy in real-world scenarios.
Challenges
DNNs for AV workloads need to be trained with huge volumes of data. You would need a compute infrastructure that is scalable to train the DNNs, handle large volumes of training data, and consider factors to optimize training with models and data parallelism.
Training with large volumes of data
AV systems collect a large volume of data from the devices attached to the vehicle. Depending on the AV system provider, the vehicle fleet ranges from a handful to thousands of vehicles. The following are some typical challenges an AV system provider may encounter:
- Collection, preprocessing, and storage of petabytes of data – Each vehicle collects more than 40 TB of data for every 8 hours of driving.
- Identification of relevant representation data from a huge volume of data – This is essential to reduce biases in the datasets so that common scenarios (driving at normal speed with obstruction) don’t create class imbalance. To yield better accuracy, DNNs require large volumes of diverse, good quality data.
- Volume of corner cases – ML models need to handle a wide range of corner cases. This is essential to ensure the safety of the AV system.
- Training time – Given a huge volume of data, training time is often in multiple days or even weeks. This reduces the development velocity and ability to fail fast.
To address the large value challenge, you can utilize the Amazon SageMaker distributed data parallelism feature (SMDDP). SageMaker is a fully managed machine learning (ML) service. With data parallelism, a large volume of data is split into batches. Blocks of data are sent to multiple CPUs or GPUs called as nodes, and the results are combined. Each node has a copy of the DNN. SageMaker has developed the distributed data parallel library, which splits data per node and optimizes the communication between the nodes. You can use the SageMaker Python SDK to trigger a job with data parallelism with minimal modifications to the training script. Data parallelism supports popular deep learning frameworks PyTorch, PyTorch Lightening, TensorFlow, and Hugging Face Transformers.
The Hyundai motor company utilized SageMaker data parallelism to reduce training time for their autonomous driving models and achieved more than 90% scaling efficiency with eight instances, each having 8 GPUs. The following diagram illustrates this architecture.

For more details, refer to Hyundai reduces ML model training time for autonomous driving models using Amazon SageMaker.
For more information about distributed training with SageMaker, refer to the AWS re:Invent 2020 video Fast training and near-linear scaling with DataParallel in Amazon SageMaker and The science behind Amazon SageMaker’s distributed-training engines.
Labeling a large volume of data
The training pipeline requires a large volume of labeled datasets. One of the common challenges faced by our customers is development of annotation tools to label the image, video, and sensor (for example, 3D point cloud); custom workflows for object detection; and semantic segmentation tasks. You need the ability to customize your workflows.
Amazon SageMaker Ground Truth is a fully managed data labeling service that provides flexibility to build and manage custom workflows. With Ground Truth, you can label image, video, and point cloud data for object detection, object tracking, and semantic segmentation tasks. You can transfer data collected from the vehicles and stored on premises to AWS using a data transfer mechanism such as AWS Storage Gateway, AWS Direct Connect, AWS DataSync, AWS Snowball, or AWS Transfer Family. After the data is preprocessed (such as blurring faces and license plates), the cleaned dataset is ready for labeling. Ground Truth supports sensor fusion of LiDAR data with video inputs from cameras. You can choose to use human annotators through Amazon Mechanical Turk, trusted third-party vendors, or your own private workforce.
In the following figure, we provide a reference architecture to preprocess data using AWS Batch and using Ground Truth to label the datasets.

For more information, refer to Field Notes: Automating Data Ingestion and Labeling for Autonomous Vehicle Development and Labeling data for 3D object tracking and sensor fusion in Amazon SageMaker Ground Truth.
For more information on using Ground Truth to label 3D point cloud data, refer to Use Ground Truth to Label 3D Point Clouds.
Training infrastructure
As the AV systems mature, the DNNs need to be trained to handle multiple edge cases (for example, humans walking on highways), and the model gets complex and big. This results in training the DNNs with more data from mining the recorded data or through simulations to handle newer scenarios. This demands more compute capacity and scaling compute infrastructure.
To support the computing needs for ML workloads, SageMaker provides multiple instance types for training. Each family is designed for a few specific workloads; you can choose based on the vCPU, GPU, memory, storage, and networking configurations of the instances. For full, end-to-end AV development, companies largely rely on the m, c, g, and p families.
Some of our customers use our Deep Learning AMIs (DLAMI) to launch NVIDIA GPU-based Amazon Elastic Compute Cloud (Amazon EC2) instances in the p family. Each EC2 p family instance generation integrates the latest NVIDIA technology, including the p2 instances (Tesla K80), p3 instances (Volta V100), and p4d instances (Ampere A100).
The following figure summarizes the available instances:

When the DNNs are complex and can’t fit in memory of one GPU, you can use the SageMaker model parallelism library. This splits the layers across GPUs and instances. You can use the library to automatically partition your TensorFlow and PyTorch models across multiple GPUs and multiple nodes with minimal code changes.
MLOps
When it comes to operationalizing, from data scientists conducting experiments on revised models to deploying across thousands of vehicles, AV system providers need a set of tools that work end to end seamlessly for various needs:
- Data collection and transformation at scale
- Automated analysis and evaluation of models
- Standardization of data pipelines
- The ability to define and conduct experiments for data scientists
- Monitoring model performance
- Establishing a repeatable process and eliminating human intervention with end-to-end automation
- Automated model deployment, which enables you to quickly deploy a trained model across millions of vehicles
SageMaker provides comprehensive MLOps tools. Data scientists can use Amazon SageMaker Experiments, which automatically tracks the inputs, parameters, configurations, and results of iterations as trials. You can further assign, group, and organize these trials into experiments. Amazon SageMaker Model Monitor helps continuously monitor the quality of your ML models in real time. You can set up automated alerts to notify when there are deviations in the model quality, such as data drift and anomalies. When it comes to orchestration, you can choose from a number of options, including the SageMaker Pipelines SDK, AWS Step Functions, Amazon Managed Apache Airflow (Amazon MWAA), and open-source tools like Kubeflow.
Conclusion
In this post, we covered the build approaches and different functional units of ADAS, a unified framework to build a modular pipeline, and the challenges of building an ADAS system. We provided reference architectures and links to case studies and blog posts that explain how our customers use SageMaker and other AWS services to build a scalable AV system. The proposed solutions can help our customers to address the challenges while building a scalable AV system. In a later post, we will do a deep dive into the DNNs used by ADAS systems.
About the Authors
 Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
 Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.