At Google Cloud, we strive to make it easy to deploy AI models onto our infrastructure. In this blog we explore how the Cross-Cloud Network solution supports your AI workloads.
Managed and Unmanaged AI options
Google Cloud provides both managed (Vertex AI) and do-it-yourself (DIY) approaches for running AI workloads.
Vertex AI: A fully managed machine learning platform. Vertex AI offers both pre-trained Google models and access to third-party models through Model Garden. As a managed service, Vertex AI handles infrastructure management, allowing you to concentrate on training, tuning, and inferencing your AI models.
Custom infrastructure deployments: These deployments utilize various compute, storage and networking options based on the type of workload the user is running. AI Hypercomputer is one way to deploy both HPC workloads that may not require GPU and TPUs, and also AI workloads running TPUs or GPUs.
Networking for managed AI
With Vertex AI you don’t have to worry about the underlying infrastructure. For network connectivity by default the service is accessible via public API. Enterprises that want to use private connectivity have a choice of Private Service Access, Private Google Access, Private Service Connect endpoints and Private Service Connect for Google APIs. The option you choose will vary based on the specific Vertex AI service you are using. You can learn more in the Accessing Vertex AI from on-premises and multicloud documentation.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 to try Google Cloud networking’), (‘body’, <wagtail.rich_text.RichText object at 0x3e4f0c92abe0>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectpath=/products?#networking’), (‘image’, None)])]>
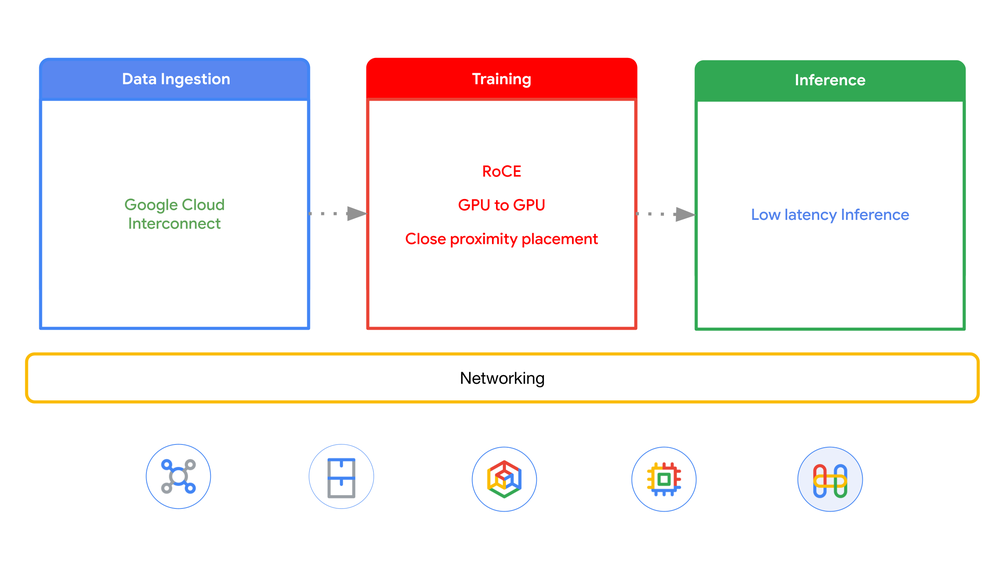
Networking AI infrastructure deployments
An organization has data located in another cloud, and would like to deploy an AI cluster with GPUs on Google Cloud. Let’s look at a sample case.
Based on this need, you need to analyze the networking based on planning, data ingestion, training and inference.
Planning: This crucial initial phase involves defining your requirements, the size of the cluster (number of GPUs), the type of GPUs needed, the desired region and zone for deployment, storage and anticipated network bandwidth for transfers. This planning informs the subsequent steps. For instance, training large language models like LLaMA which has billions of parameters requires a significantly larger cluster than fine-tuning smaller models.
Data ingestion: Since the data is located in another cloud, you need a high-speed connection so that the data can be accessed directly or transferred to a storage option in Google Cloud. To facilitate this, Cross-Cloud Interconnect offers a direct connection at high bandwidth with a choice of 10Gbps or 100Gbps per link. Alternatively if the data is located on-premises, you can use Cloud Interconnect.
Training: Training workloads demand high-bandwidth, low-latency, and lossless cluster networking. You can achieve GPU-to-GPU communication that bypasses the system OS with Remote Direct Memory Access (RDMA). Google Cloud networking supports the RDMA over converged ethernet (RoCE) protocol in special network VPCs using the RDMA network profile. Proximity is important so nodes and clusters need to be as close to each other as possible for best performance.
Inference: Inference requires low-latency connectivity to endpoints, which can be exposed via connectivity options like Network Connectivity Center (NCC), Cloud VPN, VPC network peering and Private Services Connect.

In the example above we use:
Cross-Cloud Interconnect to connect to Google Cloud to meet the high speed connection requirement
RDMA networking with RoCE, since we want to optimize our accelerators and have planned requirements.
Google Kubernetes Engine (GKE) as a compute option on which to deploy our cluster.
Learn more
To learn more about networking for AI workloads please explore the following:
Cross-Cloud Network: Accelerating the Enterprise AI Journey with Cross-Cloud Network
Compute: Blackwell is here — new A4 VMs powered by NVIDIA B200 now in preview
Want to ask a question, find out more or share a thought? Please connect with me on Linkedin.