

by Peter Wilczynski, Product Lead for the Ontology System
“Show me the incentive and I’ll show you the outcome” — Charlie Munger
I.
As an industry, we are producing more software at an ever-increasing rate and yet the impact of this software on economic productivity has been marginal.
This lack of progress is inherent to how the software industry itself is organized — the vast majority of human capital is focused on developing modular components rather than on integrating these components into cohesive enterprise systems that can actually impact business outcomes. We denigrate this integration work and elevate the components to the status of “systems,” instead of appropriately conceptualizing them as instrumental pieces of a larger puzzle. Digital transformation has become a goal in its own right, rather than a journey undertaken by skilled practitioners with a destination defined by the business itself.
We’ve lost the plot by tricking ourselves into believing that because it’s easier to build individual parts, someone else must be able to assemble them into something worthwhile.
The resulting software architecture is optimized to produce returns for venture capitalists, not to achieve outcomes for customers; it rewards zero-sum competition between suppliers of individual components rather than positive sum collaboration between partners focused on overall system performance. And while these individual pieces have improved drastically over the past twenty years, the paradox is that this has come at the expense of the enterprise system as a whole. By optimizing components in isolation, it becomes increasingly difficult to synchronize changes across multiple disintegrated components. As a result, improvements at the component level have failed to deliver improvements at the system level.
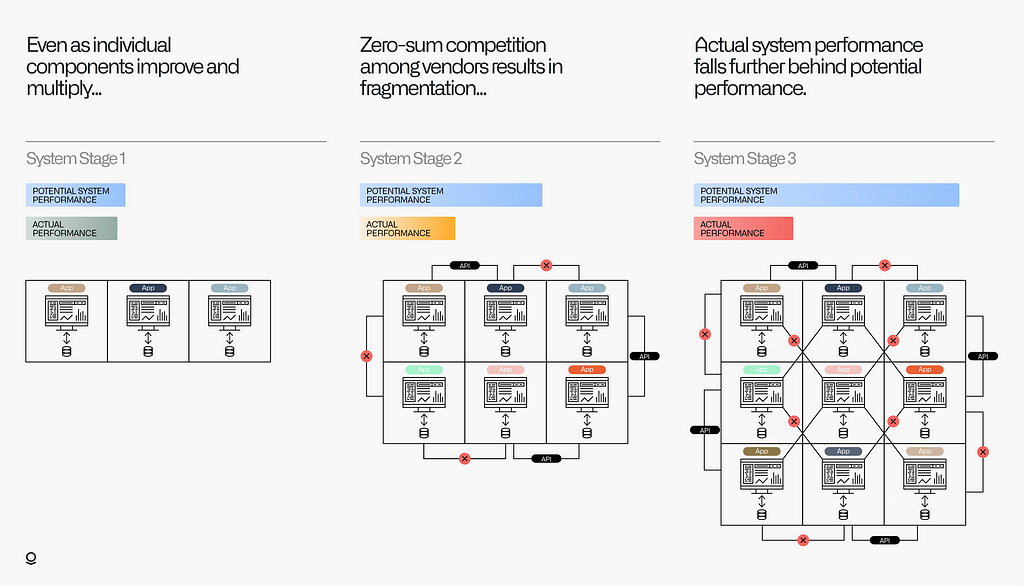
Despite being sold modularity, customers of this software-industrial complex have received a product that is fragmented and disintegrated. Rather than enabling agility, these investments have resulted in rigid enterprise architectures.¹ This technical rigidity seeps into the broader organizational culture and creates stasis.
At Palantir, our mission is to realize the emancipatory power of technology-driven progress for humanity — by empowering organizations to build bespoke software tools which can catalyze widespread enterprise transformation. Inconveniently, we quickly realized that there wasn’t a single product that could do that across the entire economy; i.e., this mission couldn’t be achieved by metabolizing a shared set of requirements and secreting the same shrink-wrapped software to all of our customers. The artisanal software engineering had to happen in situ.
And to make that economically feasible, we needed to build technology which could drive the marginal cost of bespoke enterprise software development to zero.
The architecture underpinning this is the Palantir Ontology, described in Akshay’s last blog post. This technology, along with its Software Development Kit (what we call the “Ontology SDK” or “OSDK”), makes it possible to defragment the enterprise by integrating isolated components into a holistic system. By implementing a decision-centric ontology which harmonizes data, logic and action elements from across the entire IT landscape, organizations can finally begin to think creatively about the intersection between their technology assets and business priorities.
II.
Consider an airline trying to reduce downtime and eliminate delays due to mechanical issues.
As soon as a warning light goes off during a routine pre-flight check, the pressure begins to mount as people across the organization start to assemble their options. Complex decisions that involve real tradeoffs between safety, employee health and customer impact need to be weighed.
This problem is a specific example of generalized resource allocation problems seen across industries. While resources may be proactively allocated according to a statistically optimal distribution, re-allocating these resources as the situation on the ground changes is the critical measure of enterprise agility: how quickly can the enterprise react to reality?
In our notional flight example, this involves answering three questions:
- Does the aircraft need to be grounded?
- Which airports have the right replacement parts and mechanics for performing the repair?
- What options allow us to swap the aircraft while minimizing customer impact?
Using IoT data from the plane (which can produce north of two million data points per flight), we need to understand how many flight hours the plane has left. To do this, our data scientists can load the IoT data and run a predictive maintenance model to get an initial estimation of how much service life is left.
Assuming the flight can take off, we need to start planning a fix. This means that our operations team needs to find out which airports have the right replacement parts in stock and cross-reference that data with maintenance crew schedules to identify a certified mechanic capable of performing the repair. Rather than kicking the can down the road, our goal is to swap the aircraft immediately so that it can arrive at a destination capable of completing the repair as soon as possible, ideally without impacting any customers.
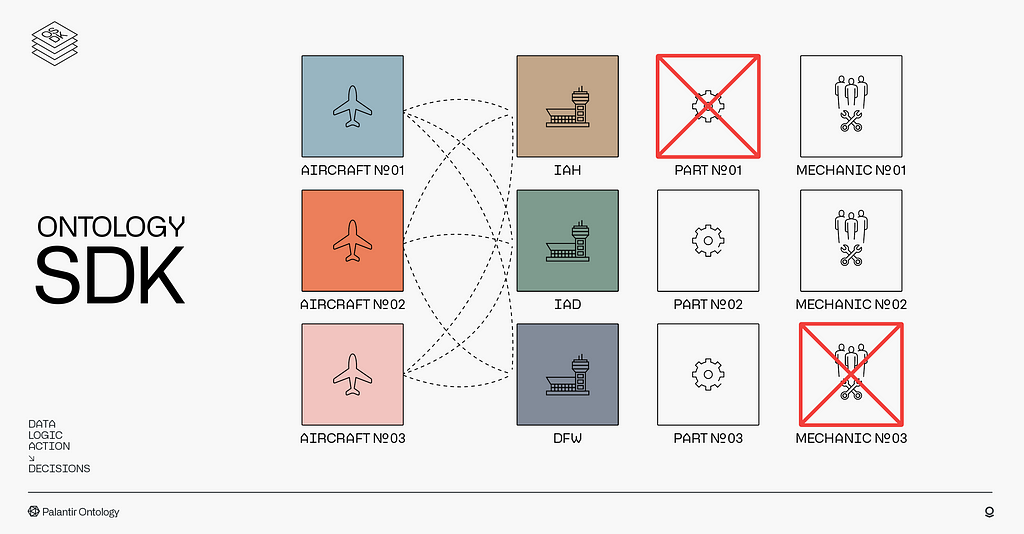
Based on this criteria, we might identify two swap options which would result in the aircraft landing at either IAD or DFW. DFW would meet all of the constraints for the repair, but because the airframe has a different seat configuration, we’ll end up bumping three passengers, costing us $5,000 plus a reduction in customer satisfaction. IAD has the part that will need to be replaced and an empty hanger to work on it, but there are no mechanics with the specific skills currently scheduled for when the plane arrives; getting the fix done overnight will require us to schedule a mechanic to work overtime at an increased cost of $2,000.
The first solution is simpler; the second, optimal solution requires swapping the plane and coordinating with the mechanic — i.e., requires more context and more degrees of freedom.
Finding the optimal solution programmatically involves the coordinated orchestration of many different data, logic and action elements. Data elements come from airport operational databases, flight manifests and resource management systems. These data elements are used as input to logic elements which can predict impact, model customer behavior and evaluate risk. Finally, the output of these logic elements are used to construct action elements which write back decisions to the appropriate operational systems and distribute real-time notifications to the right people.
Translating this solution into an application on top of today’s fragmented enterprise architecture requires dealing with data from core transactional business systems, reconciling that with SaaS tools and custom internal systems and orchestrating actions across multiple different parts of the value chain. An engineer implementing this solution would need to learn the APIs of each system, set up the connections with IT teams at each organization and build an application that interacts with each system directly.
This knowledge — the knowledge of how to interact with the systems, how to reconcile their different data models, how to access their disjointed logic elements and how to orchestrate their systems of action — would live in yet another fragmented application or service, inaccessible to other teams within the organization who are trying to perform similar tasks. While API gateways can play an important role in enabling API discovery, programmers are still stuck harmonizing system-specific representations with glue code in the application layer.
The Ontology centralizes this knowledge and encapsulates it within a shared system. This system, along with the OSDK, then functions as a higher-level abstraction for authoring business logic which operates on a harmonized layer of critical business concepts, operational processes and real-world tasks. This allows translations from component-centric representations into the shared conceptual model to happen once, rather than every time a new application is built.
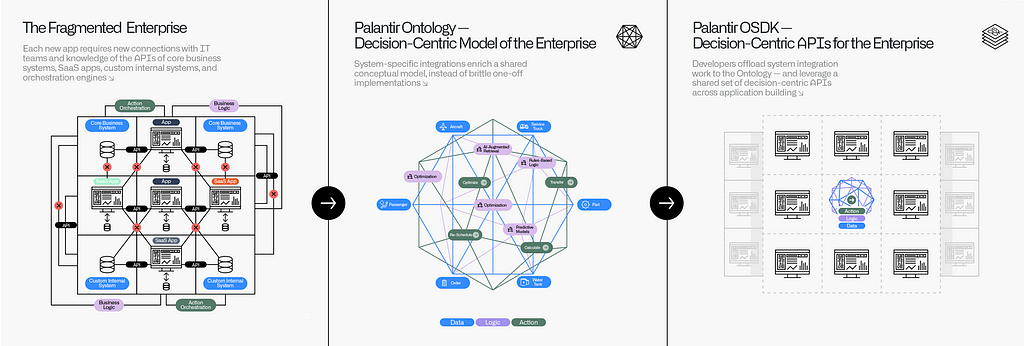
And this knowledge compounds rapidly; by relying on the shared decision-centric Ontology, new applications can take advantage of the preexisting system integration work, and new components can be onboarded quickly by harmonizing their data, action and logic elements with existing representations.²
Consider the example from above. In a world before the Ontology, a programmer would need to find the appropriate components and then interact with each one using a component-specific interface, language and / or dialect. As a result, the code itself is fundamentally component-centric:
const mysql = require('mysql');
const nodemailer = require('nodemailer');
const fetch = require('node-fetch');
// Inventory database connection configuration
const dbConfig = {
host: 'skyframe-internal',
user: 'db_admin',
password: process.env.DB_PASSWORD,
database: 'skyframe'
};
// Email server configuration (example using Gmail)
const transporter = nodemailer.createTransport({
service: 'gmail',
auth: {
user: 'swapbot@skyframe.com',
pass: process.env.EM_PASSWORD
}
});
// Connect to the inventory database and query for airports with inventory
async function findAirportsWithInventory(parts) {
const connection = mysql.createConnection(dbConfig);
const query = "SELECT airport_code FROM inventory WHERE part_number IN (?)";
return new Promise((resolve, reject) => {
connection.query(query, [parts.map(part => part.partNumber)], (error, results) => {
connection.end();
if (error) return reject(error);
resolve(results.map(row => new Airport(row.airport_code)));
});
});
}
// Connect to the database and query for swappable flights
async function findSwappableFlights(flightToSwap, aircraft, targetAirports) {
const connection = mysql.createConnection(dbConfig);
const query = `SELECT * FROM flights
WHERE departure_airport_code = ? AND aircraft_id = ? AND destination_airport_code IN (?)
ORDER BY departure_time ASC`;
return new Promise((resolve, reject) => {
connection.query(query, [flightToSwap.departureAirportCode, aircraft.id, targetAirports.map(airport => airport.id)], (error, results) => {
connection.end();
if (error) return reject(error);
resolve(results.map(row => new ScheduledFlight(row)));
});
});
}
// Function to calculate optimal swaps by calling an external REST endpoint
async function calculateOptimalSwaps(flightToSwap, swappableFlights) {
const requestBody = {
flightToSwap: flightToSwap,
swappableFlights: swappableFlights
};
const response = await fetch('https://skyframe-internal-gateway/api/calculateOptimalSwaps', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer Ym9zY236Ym9zY28'
},
body: JSON.stringify(requestBody)
});
if (!response.ok) {
const error = await response.text();
throw new Error(`Failed to calculate optimal swaps: ${error}`);
}
const swapOptions = await response.json();
return swapOptions;
}
// Function to calculate maintenance and customer impact costs by calling an external REST endpoint
async function calculateImpactCosts(swapOptions) {
const requestBody = {
swapOptions: swapOptions
};
const response = await fetch('https://skyframe-internal-gateway/api/calculateImpactCosts', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer Ym9zY236Ym9zY28'
},
body: JSON.stringify(requestBody)
});
if (!response.ok) {
const error = await response.text();
throw new Error(`Failed to calculate impact costs: ${error}`);
}
const impactCosts = await response.json();
return impactCosts;
}
// Function to perform the swap operation
async function swapAircraft(targetAircraft, aircraft) {
const requestBody = {
targetAircraft: targetAircraft,
aircraft: aircraft
};
const response = await fetch('https://skyframe-internal-gateway/api/swapAircraft', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer Ym9zY236Ym9zY28'
},
body: JSON.stringify(requestBody)
});
if (!response.ok) {
const error = await response.text();
throw new Error(`Failed to swap aircraft: ${error}`);
}
console.log(`Swapping aircraft ${targetAircraft.id} with ${aircraft.id}`);
}
// Function to send an email for swap approval (using nodemailer)
async function emailSwapsForApproval(swapOptions) {
const mailOptions = {
from: 'swapbot@skyframe.com',
to: 'ground-control@skyframe.com',
subject: 'Flight Swap Approval Required',
text: `Approval is required for the following swap options: ${JSON.stringify(swapOptions)}`
};
return transporter.sendMail(mailOptions);
}
// Main function to schedule preventative maintenance
async function schedulePreventativeMaintenance(aircraft, parts) {
try {
// Assuming aircraft.getSchedule() and schedule.getNextFlight() are defined elsewhere
const schedule = await aircraft.getSchedule();
const flightToSwap = await schedule.getNextFlight();
const targetAirports = await findAirportsWithInventory(parts);
const swappableFlights = await findSwappableFlights(flightToSwap, aircraft, targetAirports);
const swapOptions = await calculateOptimalSwaps(flightToSwap, swappableFlights);
const impactCosts = await calculateImpactCosts(swapOptions);
const cheapestOption = impactCosts.reduce((cheapest, option) =>
option.cost < cheapest.cost ? option : cheapest,
{ cost: Number.MAX_VALUE }
);
// Guardrails for Options
if (cheapestOption.cost < 1000) {
await swapAircraft(cheapestOption.swapOption.targetAircraft, aircraft);
} else {
await emailSwapsForApproval(swapOptions);
}
} catch (error) {
console.error('Failed to schedule preventative maintenance:', error);
}
}This is an intentionally abbreviated example — API request and response types are overly simplified, the underlying logic and action systems are exposed via a standard API gateway pattern, authentication is relatively consistent and the error handling is exceedingly trivial. Even still, the majority of the code is spent writing functions that connect directly to the underlying systems; the main scheduling function represents only a fraction of the total amount of code.
By contrast, with an ontology-oriented development model, the defragmentation code required to harmonize the data, logic and actions across systems exists within the enterprise’s ontology, substantially simplifying the client code.³
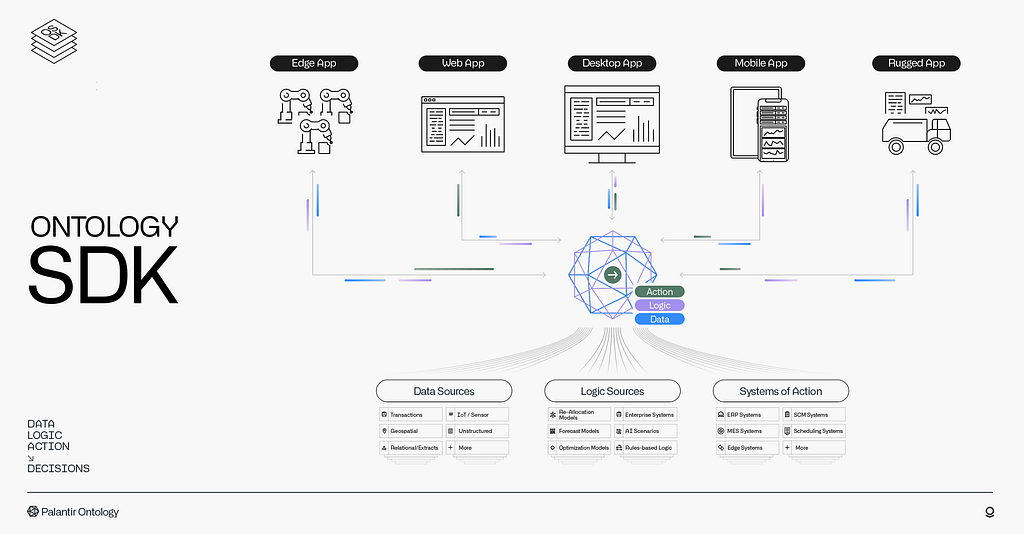
Using the Ontology Software Development Kit (OSDK), which exposes the data, logic and action elements of the Ontology in idiomatic Python, Typescript and Java, we’re able to push most of the complexity into the Ontology itself and expose enterprise objects which correspond to direct representations of actual business concepts:
async function schedulePreventativeMaintence(aircraft: Aircraft, parts: AircraftComponent[]) {
const schedule: FlightSchedule = await aircraft.getSchedule();
const flightToSwap: ScheduledFlight = await schedule.getNextFlight();
const targetAirports: Airport[] = await OntologyClient.search()
.airports()
.filter(a => a.inventory.containsAll(parts))
.all();
// Find flights from the same departure location to airports with inventory
const swappableFlights: ScheduledFlight[] = await flightToSwap.getDepartureAirport()
.scheduledFlights()
.filter(f => f.aircraft.airframe.exactMatch(aircraft.airframe))
.filter(f => f.destination.isOneOf(targetAirports))
.orderBy(f => f.departureTime.asc())
.all();
const swapOptions: FlightSwapOption[] = await OntologyClient.calculateOptimalSwaps(flightToSwap, swappableFlights);
const impactCosts: SwapOptionCost[] = await OntologyClient.calculateImpactCosts(swapOptions);
const cheapestOption = impactCosts.reduce((cheapestOption, option) =>
option.cost < cheapestOption.cost ? option : cheapestOption,
{ cost: Number.MAX_VALUE },
);
// Guardrails for Options
if (cheapestOption.cost < 1000)
await OntologyClient.action.swapAircraft(cheapestOption.flight, aircraft);
else
await OntologyClient.action.emailSwapsForApproval(swapOptions);As Brooks says in his seminal paper, there is no silver bullet: systems integration is replete with essential complexity which must be managed and cannot be eliminated. But by enforcing design patterns which encapsulate this complexity within the Ontology, ontology-oriented client code is able to operate at a higher level of abstraction. Much as higher-level languages allowed programmers to abstract away the internal implementation details of the hardware components that make up a physical computer, the ontology-oriented approach allows programmers to abstract away internal implementation details of software components that comprise an enterprise architecture.
In this example, the programmer interacts with these business concepts using the OSDK and writes code in the language of the business — not in terms of rows and columns, but in terms of Airplanes, Flight Schedules, and Airports. The OSDK isn’t providing a generic API for our product — it’s providing a toolkit for building APIs for your business, in the language of your business.
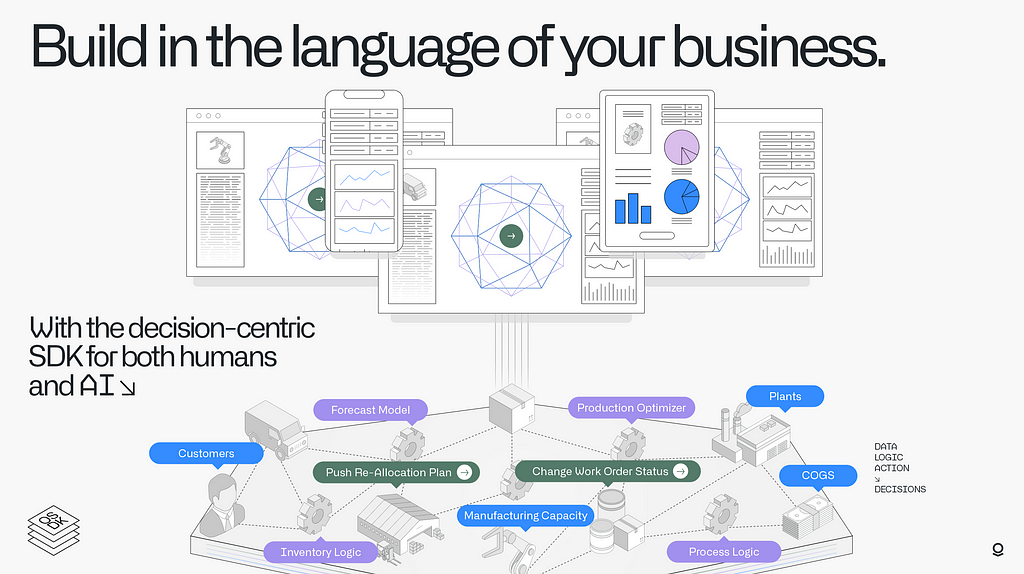
III.
Higher-level abstractions in software are always disruptive in the precise sense described by Clayton Christensen — they start by tackling the simplest programs, but because of their underlying structural advantages, the developing technology is then able to leapfrog the incumbents.
With the Ontology, the leapfrogging occurred by supercharging our ability to build custom applications. As anyone who’s used low-code visual programming tools knows, those applications always hit a ceiling. As a result, the implicit decision you’re making when choosing a low-code development tool is to constrain the ambition of the solution you’re building.
Establishing our application building platform on top of the Ontology changed this situation in three ways.
First, it made low-code applications more powerful. Low-code builders could leverage code-based data, logic and action elements in their low-code applications, pushing the performance ceiling higher than we’ve seen in any other low-code environment. This power enables builders to develop operational line-of-business applications directly within a visual programming environment.
Second, when builders reached the threshold of what was possible to build using a low-code development environment, the OSDK allowed them to migrate seamlessly into a traditional code-based development environment without having to reimplement the entire application from scratch.
Third, the Ontology made it easy to build low-code and pro-code applications designed to interoperate with one another. Both low-code and pro-code approaches have different tradeoffs: low-code tools lower the threshold for getting things built and make application development more accessible, while code-based tools raise the ceiling, enabling advanced users to do more powerful things and build more complex experiences. Synthesizing the two approaches via the Ontology lets users pick the right tool for the job at hand.
Recently, we’ve seen the same structural advantage provided by the Ontology play out with our AI Platform (AIP), which provides a foundational set of user-facing capabilities along with a development toolchain for building bespoke AI systems and deploying them directly into operational workflows.
Why were we able to release AIP so fast?
It’s because from one crucial perspective, AI systems are more like applications than they are like users — they interact directly with APIs!
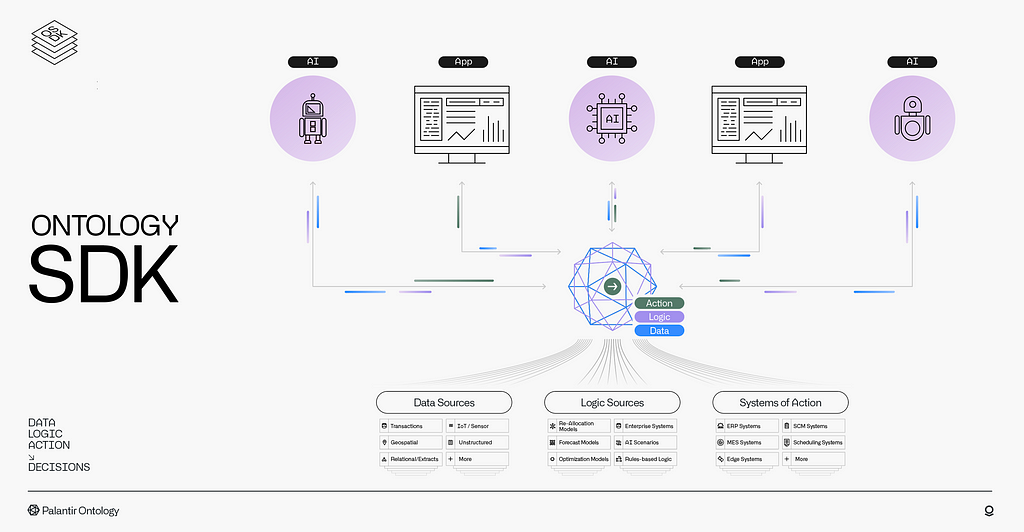
Since the dawn of computing, interface design has always been optimized to make digital systems more accessible to humans, either as users or programmers. Over the past century, we’ve shifted from punch cards to CLIs, and from CLIs to GUIs, always with human usability as the north star.
But as we transition into a world in which humans collaborate directly with progressively more functional AI systems to achieve their missions, our definition of accessibility must expand to allow autonomous systems to take on progressively more complex tasks.
LLM-based systems have been made in our image; like humans, they can use text-based interfaces and interact with natural language representations of the world. But this similarity is deceptive, and will not be true for all AI systems; indeed, it is not true for all AI systems today — AlphaStar does not interact with pixels or words when it plays StarCraft.⁴
By deconstructing applications and data systems into their constituent data, logic and action elements, the Ontology exposes a singular, decision-centric model of the enterprise. This shared model can be used as a unitary representation which is exposed through three distinct types of interfaces:
- Graphical User Interfaces (GUIs), which provide users with visual representations of the Ontology.
- Application Programming Interfaces (APIs), which provide programmers and AI systems with direct access to the Ontology.
- Natural Language Interfaces (NLIs), which allow humans and language-based AI systems to interact with the Ontology using natural language.
As J. C. R. Licklider stated in Man-Computer Symbiosis, “the basic dissimilarity between human languages and computer languages may be the most serious obstacle to true symbiosis.” The Palantir Ontology is a technical solution to this linguistic challenge: instead of treating each different interface as a distinct language, an ontology represents a single language capable of being expressed in graphical, verbal and programmatic forms.
Realizing the potential of operational AI in an enterprise context is not an AI problem — it’s an ontology problem.
¹ Twenty-five years after publication of Big Ball of Mud, the paper’s observations about the state of enterprise architectures remain uncannily accurate; adopting new components has increased the complexity of the system, with the result that the underlying structural issues have only been exacerbated.
² For an example of what the end result of this development style looks like, browse through the Skywise Store to see what the result of ontology-centric development model looks like in practice.
³ It’s important to note that the actual implementations for data, logic and action elements still exist — they just exist as clearly-defined lower-level abstractions. One way to think about the Ontology is as a somewhat sophisticated monorepo which enforces certain conventions which lead to a more composable system: while it’s of course possible to abuse the Ontology and end up with the same amount of fragmentation, the patterns of encapsulation enforced by the Ontology are designed to prevent that.
⁴ At a fundamental level, while humans interact directly with the physical world and indirectly with digital systems, AI systems interact directly with digital systems and indirectly with the physical world. As a result, the vast apparatus of logic designed for serializing and deserializing information between an abstract conceptual representation and the physical representations used by I/O devices like monitors, speakers, microphones, mice and keyboards is designed to create an interface optimized for humans; it is not necessary for building interfaces that serve AI systems, and we should expect that at the limit these systems should be able to interact directly with the abstract representation at scales that are effectively unimaginable to us at this point.
![]()
Ontology-Oriented Software Development was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.