
Data Lifecycles: Protecting Data with Privacy First Principles

From the Ukraine war and COVID-19 pandemic to preventing wildfires in California and facilitating cancer research — Palantir’s impact in supporting mission critical problems is widely known. What may be less apparent is the effort it takes for our products to even be in the room when it comes to enabling solutions for these real-world challenges.
Most institutions we work with require us to meet and exceed specific requirements before they are willing to trust our platforms with their most sensitive data — this is something we have invested 20 years of engineering into and continuously adapt based on learnings in the field.
We have seen organizations approach data protection assessments of our product from a variety of levels — some work towards the lower bound of data protection and privacy regulations and laws, others have built their brand on security and privacy.
In this post, we will cover how we use privacy first principles to approach data protection broadly and in Palantir Foundry throughout the data lifecycle — from the moment it lands in the platform, right through to when that data should be deleted.
A brief history
While there are many privacy frameworks, we’ll use the Fair Information Practice Principles (FIPPs) as one of the most widely accepted privacy frameworks. These were first proposed in the 1973 report “Records, Computers and the Rights of Citizens” by the Secretary’s Advisory Committee on Automated Personal Data Systems, U.S. Department of Health, Education, and Welfare — with a long history of evolution and adaptions since, and push for core principles including:
- Accountability and Auditing (A&A)
- Individual Participation (IP)
- Data Minimization (DM)
- Purpose Specification (PS)
- Use Limitation (UL)
- Data Quality and Integrity (DQ&I)
- Security (S)
- Transparency (T)
What may be surprising is that these privacy concepts existed well before mobile phones, the internet, GPS, and social media — the root of much of the privacy community’s consternation in the last few decades. Yet, in each new iteration of data protection regulations — whether it’s HIPAA, GDPR, LGPD, CCPA/CPRA, or others — the FIPPs tend to lend a consistent set of principles across these ever-changing assemblage of acronyms.
How we approach it?
We are often asked how our products comply with different data protection regulations. More specifically:
- Aligning with Privacy Principles — We require our products to implement technical controls that map to privacy principles, such as FIPPs, before they can be used by our customers. This is further detailed in How it works in Palantir Foundry below.
- Tackling the Most Stringent Privacy and Security Requirements — Our products have been deployed in sensitive environments with some of the most stringent data protection requirements, which has pushed us to innovate and develop advanced privacy and security functionalities. These capabilities are then fed back into the core product, which benefit all our customer deployments.
- Building for Configurability — We know that compliance doesn’t always come out of the box — privacy is context-dependent and this means solutions need to be context-aware. Instead of designing for specific checklists by sector or country, we’ve designed our products to be highly configurable so organizations can adapt the platform to their specific needs.
Our approach has enabled us to quickly ensure our clients not only meet the base privacy requirements relevant to them, but also achieve more ambitious privacy objectives.
What do we mean by data lifecycles?
Data lifecycles normally start from collection and ends with deletion. Since Palantir’s products do not collect data and instead support our customers in the processing of their data, we’ll approach this topic starting from the data ingestion phase. Below we outline some distinct phases in the data lifecycle that prompt data protection needs:

- Ingestion — Data makes its debut in Foundry at the data ingestion phase. This is when data should be hosted in an appropriate environment, sensitivity classified, access controlled, cataloged, and tagged.
- Preparation and Integration — Data is then transformed and integrated with other datasets to be operationalized via analytics, models, or applications to support users of all different types. Here, we ensure data is prepared to the right level of granularity, appropriately permissioned, and checked for data quality.
- Interaction and Analysis — Once the data is prepared, it is then time for users to interact with it. This means not only ensuring the data is access controlled, but also that data is only used for appropriate purposes.
- Deletion — Eventually, data and related artifacts will no longer be needed and should be deleted to reduce risk.
How it works in Palantir Foundry
Organizations often have steps prior to the data actually landing onto the platform.
Cataloging Data Governance Requirements [S, A&A, UL, DM]
Many organizations require identifying data protection and governance requirements prior to the data being used and do so with data catalogs. Capturing this information within the platform allows the data governance instructions to sit alongside the data, streamlining the process for getting context and using the data.
Once data has been approved, it’s time to bring the data onto the platform.
- Implementing User Prompts and Checks [A&A] — When users bring sensitive data onto the platform such as through data connections or drag-and-drop capabilities, Checkpoints provide a governance tool that surfaces a configurable prompt to or requests a justification from users prior to taking potentially sensitive actions in the platform.

Setting Access Controls [S, UL]
Organizations typically protect sensitive data by restricting user access, sometimes creating a sandbox for review before sharing data more broadly. Using granular access controls, markings, and restricted views, administrators control which users and groups can access what data and with what roles.
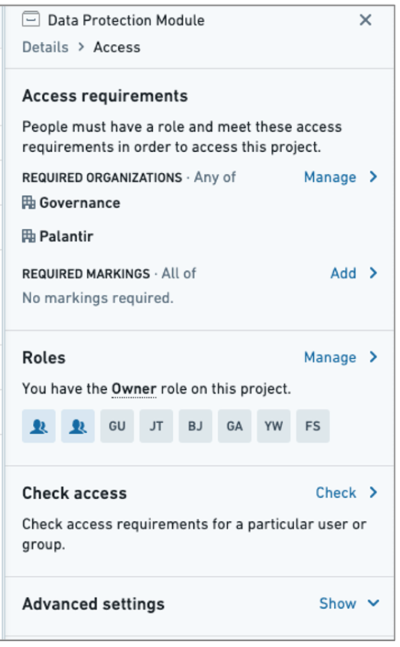
Tagging Data [S, UL, DM]
As described in Metadata Management for Data Protection, whether capturing PII, country-specific tags, or data protection metadata, Foundry enables users to tag data upfront which propagate everywhere the data goes across the platform. This gives users visibility into characteristics and metadata about the sensitive data.

Next, users can add some monitoring on where that sensitive data flows throughout the platform.
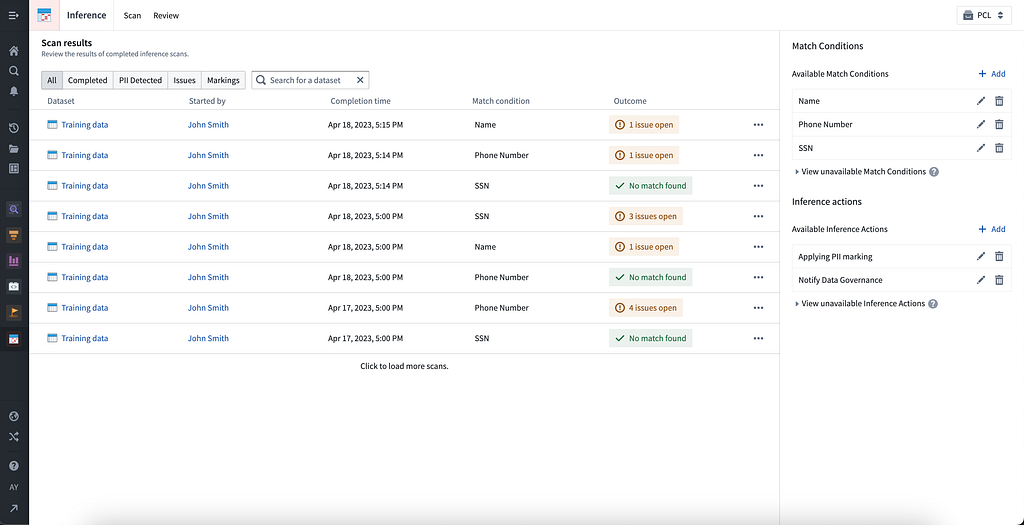
Detecting PII and Sensitive Data [S, UL]
Upon landing in the platform, Foundry Inference can be configured to allow administrators to set organization-specific definitions of sensitive data to alert, triage, and track sensitive data. For instance, when PII is detected, the platform can immediately lock down or alert reviewers to check the dataset to ensure it is only in authorized spaces and accessible by appropriate users.
Preparation and Integration
After data is ingested, tagged, and properly landed onto the platform, the next step is to ensure the necessary data minimization strategies, data quality checks, and access controls are applied everywhere the data goes.
De-identifying and Aggregating Data [DM, UL]
A common method of minimizing data and enforcing “need-to-know” access, while still allowing users to leverage the utility of data, is to prepare and transform the data to different levels of granularity. Some strategies:
- Dropping PII — Transforming data with Foundry applications to remove, filter, or replace sensitive data like PII in datasets using code or point-and-click front-ends.
- Aggregation — Converting line-level individual data into aggregated data that reduce the ability to identify or re-identify an individual.
- Generalization — Suppressing or reducing the granularity of information (e.g., bucketing age ranges) allowing data to retain line-level granularity, but with less specificity that could be used to re-identify an individual. This can be achieved using Foundry data transformation applications, such as the k-anonymization Contour board.
- Obfuscation — Masking, hashing, scrambling, or encrypting data in place of the original identifying data can reduce its re-identifiability. For instance, Foundry Cipher applies cryptographic operations to obfuscate sensitive data values by default, while enabling authorized users to request decryption of those values after providing justification.

Monitoring Data Quality [DQ&I]
As we describe in our earlier post Trust in Data (Palantir Explained, #4), Foundry allows users to leverage tools to make sure data is accurate, timely, and complete when representing individuals.
Validating Permissions [S]
As artifacts and resources are built, integrated, and joined together, it is important to continually monitor and check appropriate permissions and that they adhere to relevant policies. The Data Lineage tool gives all users, including data protection leads and platform administrators, the ability to inspect who has access to what data throughout the platform.

Interaction and Analysis
As data is handled by users, it is important to ensure accountable use of that data throughout the platform.
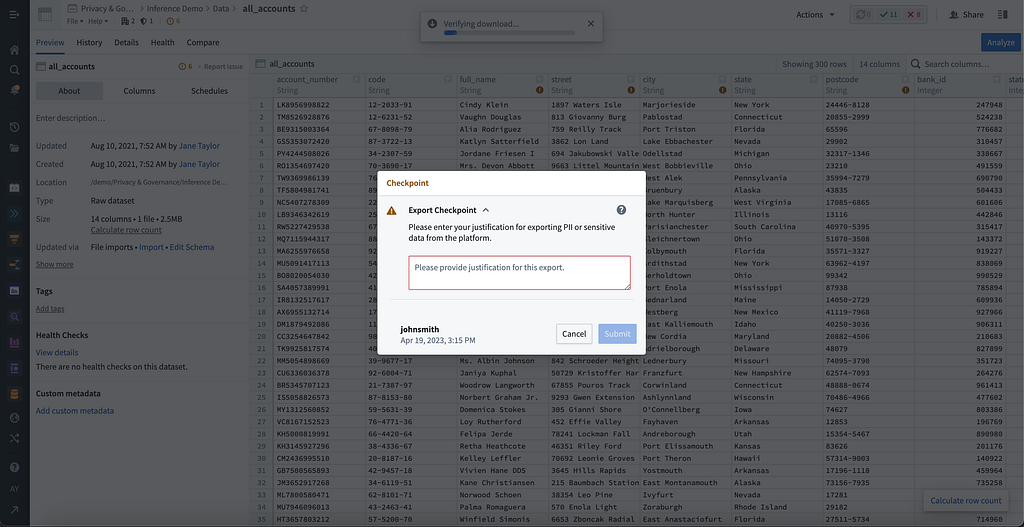
Capturing Purposes of Sensitive Data Use or Actions (e.g., Export and Downloads) [PS, A&A, UL]
For sensitive data, ensuring users are only using data for approved purposes becomes vital. This can be done with Checkpoints and with Purpose-based Access Controls at Palantir (Palantir Explained, #2), where all access to data can be traced to why the user needs it and matched to the authorized purposes. Another common configuration is setting up justifications or acknowledgements prior to data being exported from the platform, where these interactions are logged and audited directly on the platform.
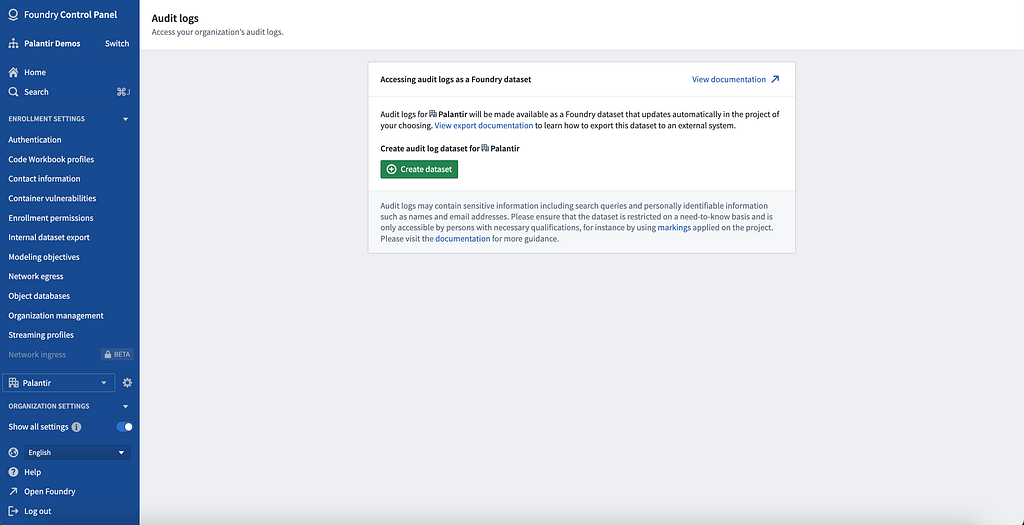
Auditing User Interactions [A&A]
Foundry captures audit logs, which has information such as who performed what action when and where, to enable monitoring the appropriate use of sensitive data. Organizations should monitor security audit logs to identify anomalous behavior as well as understand any unauthorized access patterns as described in Building Software for a Zero Trust World.
Tracking Uses for Data Subject Rights [IP, T]
From models to applications to reports, all artifacts are registered and can be visualized through Foundry’s Data Lineage capability, meaning organizations can trace how data from any data subject is used for varying purposes on the platform. This makes workflows such as creating Data Subject Requests to help data subjects understand how their data is used by an organization possible.
Deletion
When data finally reaches its end of life, whether through the data no longer being useful or due to governance policies, it is eventually time for deletion.
Deleting Data [DM]
Foundry provides administrators tools to set retention dates and delete data to adhere to legal hold or regulatory requirements, as well as for Right to be Forgotten requests. Leveraging Palantir’s data lineage tracking, Foundry allow administrators to trace data use across the platform and perform necessary deletions.
Decommissioning Projects [DM]
Whether for a migration or a decommissioning of entire use cases, Foundry has deletion protocols that deletes all resources through each layer of Foundry starting with access controls, then the application, storage, backup, and cloud infrastructure layers.
Conclusion
It can be overwhelming to think about the best way to ensure compliance and establish necessary policies when handling sensitive data, but Foundry provides the technical frameworks and tools to support best practices within the platform to complement organizational policies. Whether supporting health data for critical hospital operations to personnel data for the Department of Defense or marketing data for European customers, Palantir has worked with some of the most sensitive and protected data, while further supporting differentiated capabilities requiring best in class security and privacy, such as secure collaboration for defense to data sharing for health research.
While many organizations aim for compliance, we also know that regulations will often lag against the pace of technology, so we have invested in building privacy protective technologies from the first principles of privacy. Over time, we have seen how this has paid off in not only future-proofing our technology and architecture, but also continuing to push the boundaries of what is possible with our clients.
Author
Alice Yu, Privacy & Civil Liberties Commercial and Public Health Lead, Palantir Technologies
![]()
Protecting Data with Privacy First Principles was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.