

Editor’s Note: This is the first in a series exploring Palantir AIP’s Agentic Runtime — the integrated toolchain for building, deploying, and managing agents in mission-critical settings.
Since Day 1, Palantir’s customers have demanded rigorous security and governance capabilities that stretch far beyond conventional role-driven policies on buckets of data. This includes a security architecture that can blend marking-, purpose-, and role-based policies; dynamic lineage that flows across data, logic, action, and application artifacts; and a full suite of integrated change and release management tools that apply across both human-driven and agentic workflows. In this blog post, we examine how AIP secures agents across the full operational lifecycle.
When designing an operational AI agent, there are several security “dimensions” that are core to any delivery:
- Secure and resilient access to the reasoning core
- Insulated orchestration of agent executors
- Granular policy enforcement across all forms of memory
- Governed access and utilization of multimodal tools
- Real-time observability and post-hoc auditing of agent activity
Secure and Resilient Access to the Reasoning Core
The starting point for agent design is selecting a large language model. Curiously, as frontier models have become more capable, they have also grown increasingly similar in aptitude and performance on key benchmarks; we are in a paradigm of “commodity cognition.” As such, Palantir AIP provides scalable access to a wide range of commercial and open-source models, through regionally dispersed model hubs. Developers who have worked with LLMs know that setting up a model endpoint is simple enough, and that the true complexity is in ensuring stable performance across heterogeneous workloads that have the potential to dramatically change in scope.
Palantir employs a shared security model, for the vast majority of our customers. This means that Palantir Foundry and AIP’s core infrastructure security — including the configuration of firewalls, the monitoring of network traffic, the enforced encryption of all data at rest and in transit, the management of an ephemeral compute environment, and the continuous delivery of new service updates and security patches — provides a robust foundation for the model hub, catalog, and management services. Access to LLMs can be controlled based on enterprise organization or user group, and made contingent on geographic availability or categorical policies set by administrators. Moreover, permission to utilize LLMs within general workflows (such as AIP Assist providing in-platform guidance and coding assistance) can be neatly segmented from permission to utilize those same LLMs for agent building and deeper development.

Every model provided through Palantir AIP’s model hubs provides rigorous assurances: no prompts or completions are retained by third-party model providers, and no exchanged data is used for model training. All utilization of models can be tracked as part of unified resource management, which automatically tracks token usage across specific projects, workflows, and users. Teams are also empowered to bring and register their own models, which might include existing subscriptions or fine-tuned models. This enables developers to switch between models as they iterate, without needing to worry about compliance, availability, or handling scale.
Insulated Orchestration of Agent Executors
An agent can be defined as a stateful control loop that repeatedly invokes a stateless reasoning core (e.g., a frontier language model), interprets its outputs, executes tools and memory options, and feeds the results back until a termination condition is met. This definition highlights the need for a robust compute substrate, where orchestration is secured by infrastructure- and platform-level guardrails, in addition to the discretionary controls configured by the developer. Palantir’s hardened Kubernetes infrastructure, Rubix, provides foundational guarantees for all agentic operations: every workload is securely isolated based on necessary requirements, enabling the safe execution of application-specific runtimes that operate with precisely governed permissions. Encryption is rigorously enforced across every element in the environment, and every interaction between workloads must be authenticated, authorized, and logged in accordance with immutable configurations.
Trustworthy infrastructure enables tremendous flexibility in the construction of the control loop. Agents can execute based on granular updates in enterprise context, predefined schedules, or triggers from external sources. These conditions are often codified in the Ontology — the common model of data, logic, and action that underpins both human and AI activities in Palantir Foundry and AIP. The automation runtimes, the Ontology backend services, and all other services benefit from the ephemeral, autoscaling infrastructure provided by Rubix, and are designed to work at the scale of tens of thousands of simultaneous agent orchestrations. Individual orchestrations can be configured with fallback effects, which can package error information and utilize different retry policies (like constant backoff versus exponential backoff). Critically, high availability is interwoven with Rubix’s approach to ephemerality; nodes in Rubix environments cannot live longer than 48 hours. This ensures that every agentic orchestration, whether built through a pro-code environment like Code Workspaces or a low-code environment like AIP Logic, is designed for disruption and resilient failover.
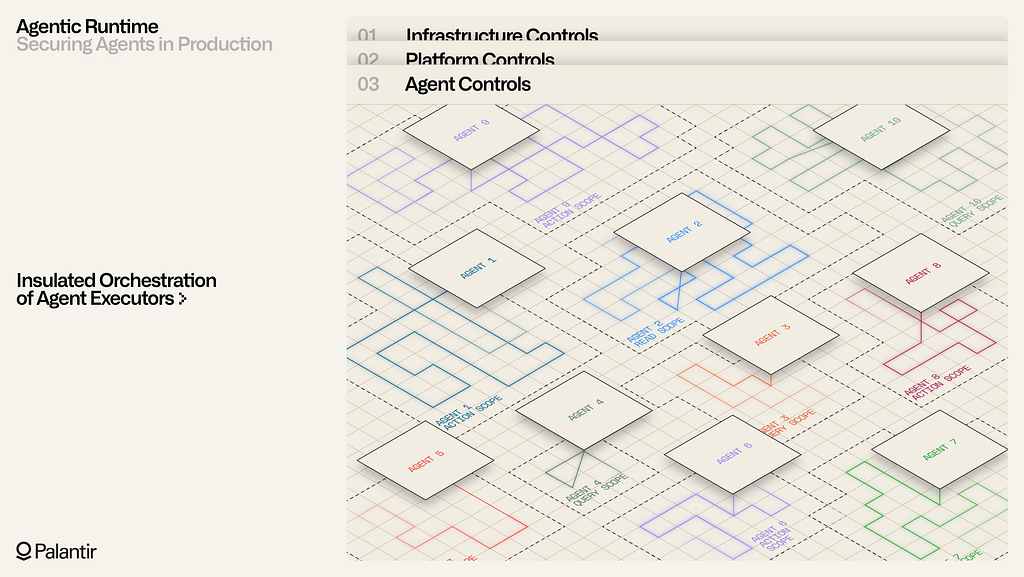
Regardless of how the agent’s control loop is configured, orchestrations themselves are platform-wide primitives which abide by the same security controls that govern system connections, Ontology context, analytical artifacts, and applications. A given agent runs with permissions that are a function of 1) the user that configures it and “owns” it; 2) the agent service user and/or agent OSDK scope; 3) the user on behalf of whom the agent is executing at a particular point in time. Production use-cases often require some combination of these permission schemes and traversing complex policies — for instance, conditional effects that must respect individual user permissions that are derived from granular data policies. As an example, consider an agent that assesses sales opportunities, which contain details that must be geographically restricted to certain users. When the agent encounters data from Europe and executes downstream analysis, only users with existing access to European data (through role-based or marking-based controls) will be notified of the new sales output. Other users will not be notified, and will not even be able to see record of the activity in AIP’s orchestration interfaces.
Granular Policy Enforcement Across All Forms of Memory
Among the myriad memory patterns that have emerged for agentic architectures, there are four common categories: working memory, episodic memory, semantic memory, and procedural memory. Working memory pertains to the information at the disposal of the agent during the current loop; i.e., the prompt information and the working variables that are expressly used to feed subsequent calls and achieve completion criteria. Episodic memory stores relevant information across execution sessions, and typically focuses on temporal markers that help inform subsequent operations. Semantic memory represents a learned collection of knowledge and skills, which tend to be more categorial than temporal in orientation. Finally, procedural memory is typically code that is designed to augment the implicit knowledge contained with the parametric weights of the model, to help drive stable execution and reliable usage of tools.
The Ontology system in AIP is designed to serve each of these memory modalities — providing flexible read/write interfaces, while ensuring common adherence to security and governance policies. Using the example of a logistics support agent: an agent is initialized through procedural memory, which can exist as literal code stored in Ontology objects, or facilitated through an orchestrating application (e.g., Agent Studio, AIP Logic). During initialization, both the system and tasks prompts can be loaded through Ontology SDK calls, from curated ontology objects (“knowledge nodes”) that specify working memory. Moreover, the semantic memory is also loaded through associated knowledge nodes; perhaps including the relevant details about the customer issue in question, feedback that this customer has provided in the past, and guidance on broader context (including full-scale production, fulfillment, support data) to query for the current state of the supply chain. As execution progresses, episodic memory can be situationally loaded through similarity searches made across vector-embedded Ontology properties, enabling prior learnings to steer the control loop. Throughout execution, variables and other elements of working memory can be updated through Ontology Actions — providing not only a transient scratchpad, but a rich session ledger that can power feedback-driven learning.

Granular policies can be affixed across the Ontology to constrain both agentic and human access to sensitive or context-dependent information. These policies are dynamically computed at runtime for every interaction, and can combine row- and column-level restrictions that have been applied to underlying datasets, attributes of particular user groups (including those that flow via SSO), security markings that propagate across underlying data pipelines, and more. In the logistics example: there might be a set of security markings that limit access to user data containing PII, and a set of customer details that can only be queried if the agent is operating as the delegate of a human user with particular attributes. As administrators manage policies over time, every mutation is automatically captured in audit logs.
The Ontology’s modular architecture reflects the fact that there is no one-size-fits-all for managing and wielding data. Specialized storage is employed for object and vector data, streaming data, geospatial data, and media data, among other modalities. Common governance across these data types is key to mitigating attack vectors, including prompt-injection risk. As agents not only retrieve relevant functional knowledge, but orchestrate queries that leverage the enterprise’s core operational information, it is critical to maintain a consistent and coherent security envelope. By using the Ontology as a multi-purpose memory system, AIP ensures a uniform surface area across working, episodic, semantic, and procedural structures — for both human and agentic users.

Governed Access and Utilization of Multimodal Tools
In an agentic paradigm, any information source, system, or actuator with an interface becomes a potential tool to wield. The most common types of tools are data-oriented, and involve querying specific sources of information. There are also logic-oriented tools, which perform some sort of calculation — whether a simple matrix multiplication routine, or a complex simulation that utilizes several compute modalities. These are complemented by action-oriented tools, which change the state of the world in some way; whether through a transactional update in an ERP, an updated state in a digital application, or a new instruction transmitted to an industrial machine. Securing a heterogeneous and ever-evolving landscape of tools requires enforcement at the system level.
Tool usage is dynamically enforced through the same security architecture that governs memory. This ensures, at minimum, that any tool invocations are dependent on access to the underlying objects, properties, and links in the Ontology. Moreover, tools can contain runtime validations that are dependent on granular submission criteria. In the prior logistics example, the ability for an agent to update a customer order might be dependent on a combination of the group association of the agent, the real-time status of the customer, and the approximated delivery window. Every agentic action depends on precise authorization grants that explicitly dictate the set of allowable operations, safeguarding against unexpected invocations (e.g., querying data that exists across organizational boundaries, or tools that connect to unspecified external systems) and other forms of privilege escalation.
When managing connections with external systems, AIP provides developers with layered defense. In addition to infrastructure-level networking and firewall protections managed by Palantir’s Information Security team, developers can manage the egress policies that are tied to the execution of human and agentic workloads. These policies govern all possible outbound connections to external data sources, webhooks, or API endpoints. Any exports to external systems must be explicitly configured with security markings that define the permissible types of data that can be transmitted.
As showcased at DevCon 4, the most powerful lever for managing tool usage across fleets of agents is provenance-based security. Provenance-based security enables developers to build tools (or functions of any kind) that respect the mandatory controls affixed on data sources and other primitives, at runtime. Critically, this scales as simpler functions become nested into more sophisticated tools; the entire call chain is resolved at runtime, such as preventing the downstream usage of marked data in executions (including export tasks) that are unsanctioned. At “compile time,” provenance-based controls also prevent new tool versions from being published if they violate policies, and provide developers with legible error messages.
See an example of provenance-based security in action:
Real-Time Observability and Post-Hoc Auditing of Agent Activity
There is no reliability without observability, especially with non-deterministic agents. While the agent’s control loop defines the relevant surface area (e.g., the potential reasoning calls, memory modalities, possible tool invocations), the possible traversals through the “decision manifold” are often innumerable, and can vary dramatically in functional depth. It is therefore essential for developers to have a system that collates all relevant telemetry across chained executions, visualizes the complete flow, and enables more targeted downstream workflows — including performance and compliance-driven monitoring.
AIP takes an integrated approach to observability, which enables monitoring from “data to decision.” For a given distributed trace, the individual LLM queries, function calls, transforms, and other discrete operations can all be reviewed and interrogated. Unlike with conventional platforms, each trace in AIP is a launching point for deeper analysis. Every data query can be tied to a full version history for the given data source — including the transformation logic that was used to produce that particular version of the data. Every function call can be tied to semantic versions, and versioned configurations of employed webhooks or source connections. For LLM-driven functions (like those that constitute sub-agents), the associated Evals suites are automatically tracked; this provides a granular accounting of how specific calls and responses have shifted over time, within the allowances defined by qualitative or quantitative rubrics.
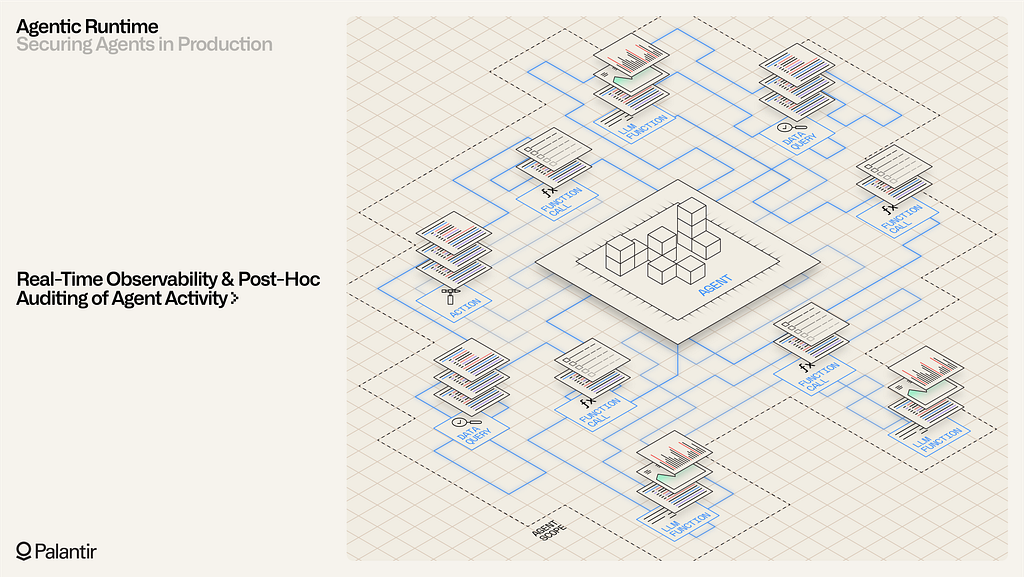
As detailed telemetry is generated by agents, the security and transmission of the logs is a critical last-mile concern. AIP enables administrators to control how logging is accessible across specific projects, workflows, and agents. Data markings and other active security primitives govern log access, in the same manner that they govern access to the underlying data, logic, and action primitives. Administrators can choose to allow real-time export of agent telemetry to streaming datasets in platform, or to external systems through authorized export tasks. Foundry’s built-in applications, such as Quiver and Contour, provide powerful tools for analyzing high-scale telemetry and generating synthesized downstream datasets, which can power closed-loop workflows.
Next Up
Beyond the five dimensions highlighted in this post, there are myriad other topics that relate to securing and governing agents in production, including deeper looks at:
- Building AI Evals
- Resource management
- Release management
- Scale and fault tolerance
- Knowledge management
Each of these elements must function as part of a cohesive system, which provides both the integrated assurances and interoperability required to power operations in the most demanding conditions.
Stay tuned to future posts on Palantir AIP’s Agentic Runtime, to learn more about how organizations are moving from prototype to production.
![]()
Securing Agents in Production (Agentic Runtime, #1) was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.