“A Stable Vicuña” — Stable Diffusion XL
Background
In recent months, there has been a significant push in the development and release of chatbots. From Character.ai’s chatbot last spring to ChatGPT in November and Bard in December, the user experience created by tuning language models for chat has been a hot topic. The emergence of open access and open-source alternatives has further fueled this interest.
The Current Environment of Open Source Chatbots
The success of these chat models is due to two training paradigms: instruction finetuning and reinforcement learning through human feedback (RLHF). While there have been significant efforts to build open source frameworks for helping train these kinds of models, such as trlX, trl, DeepSpeed Chat and ColossalAI, there is a lack of open access and open source models that have both paradigms applied. In most models, instruction finetuning is applied without RLHF training because of the complexity that it involves.
Recently, Open Assistant, Anthropic, and Stanford have begun to make chat RLHF datasets readily available to the public. Those datasets, combined with the straightforward training of RLHF provided by trlX, are the backbone for the first large-scale instruction fintuned and RLHF model we present here today: StableVicuna.
Introducing the First Large-Scale Open Source RLHF LLM Chatbot
We are proud to present StableVicuna, the first large-scale open source chatbot trained via reinforced learning from human feedback (RHLF). StableVicuna is a further instruction fine tuned and RLHF trained version of Vicuna v0 13b, which is an instruction fine tuned LLaMA 13b model. For the interested reader, you can find more about Vicuna here.
Here are some of the examples with our Chatbot,
Ask it to do basic math
Ask it to write code
Ask it to help you with grammar



Similarly, here are a number of benchmarks showing the overall performance of StableVicuna compared to other similarly sized open source chatbots.

In order to achieve StableVicuna’s strong performance, we utilize Vicuna as the base model and follow the typical three-stage RLHF pipeline outlined by Steinnon et al. and Ouyang et al. Concretely, we further train the base Vicuna model with supervised finetuning (SFT) using a mixture of three datasets:
OpenAssistant Conversations Dataset (OASST1), a human-generated, human-annotated assistant-style conversation corpus comprising 161,443 messages distributed across 66,497 conversation trees, in 35 different languages;
GPT4All Prompt Generations, a dataset of 437,605 prompts and responses generated by GPT-3.5 Turbo;
And Alpaca, a dataset of 52,000 instructions and demonstrations generated by OpenAI’s text-davinci-003 engine.
We use trlx to train a reward model that is first initialized from our further SFT model on the following RLHF preference datasets:
OpenAssistant Conversations Dataset (OASST1) contains 7213 preferences samples;
Anthropic HH-RLHF, a dataset of preferences about AI assistant helpfulness and harmlessness containing 160,800 human labels;
And Stanford Human Preferences (SHP), a dataset of 348,718 collective human preferences over responses to questions/instructions in 18 different subject areas, from cooking to philosophy.
Finally, we use trlX to perform Proximal Policy Optimization (PPO) reinforcement learning to perform RLHF training of the SFT model to arrive at StableVicuna!
Obtaining StableVicuna-13B
StableVicuna is of course on the HuggingFace Hub! The model is downloadable as a weight delta against the original LLaMA model. To obtain StableVicuna-13B, you can download the weight delta from here. However, please note that you also need to have access to the original LLaMA model, which requires you to apply for LLaMA weights separately using the link provided in the GitHub repo or here. Once you have both the weight delta and the LLaMA weights, you can use a script provided in the GitHub repo to combine them and obtain StableVicuna-13B.
Announcing Our Upcoming Chatbot Interface
Alongside our chatbot, we are excited to preview our upcoming chat interface which is in the final stages of development. The following screenshots offer a glimpse of what users can expect.
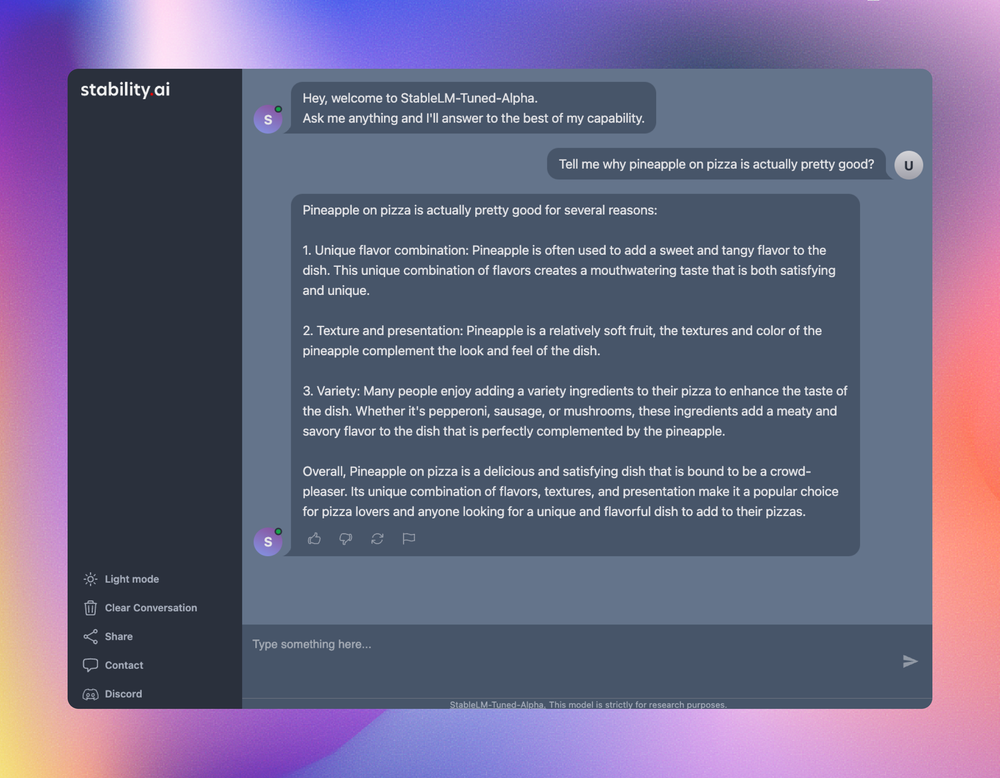
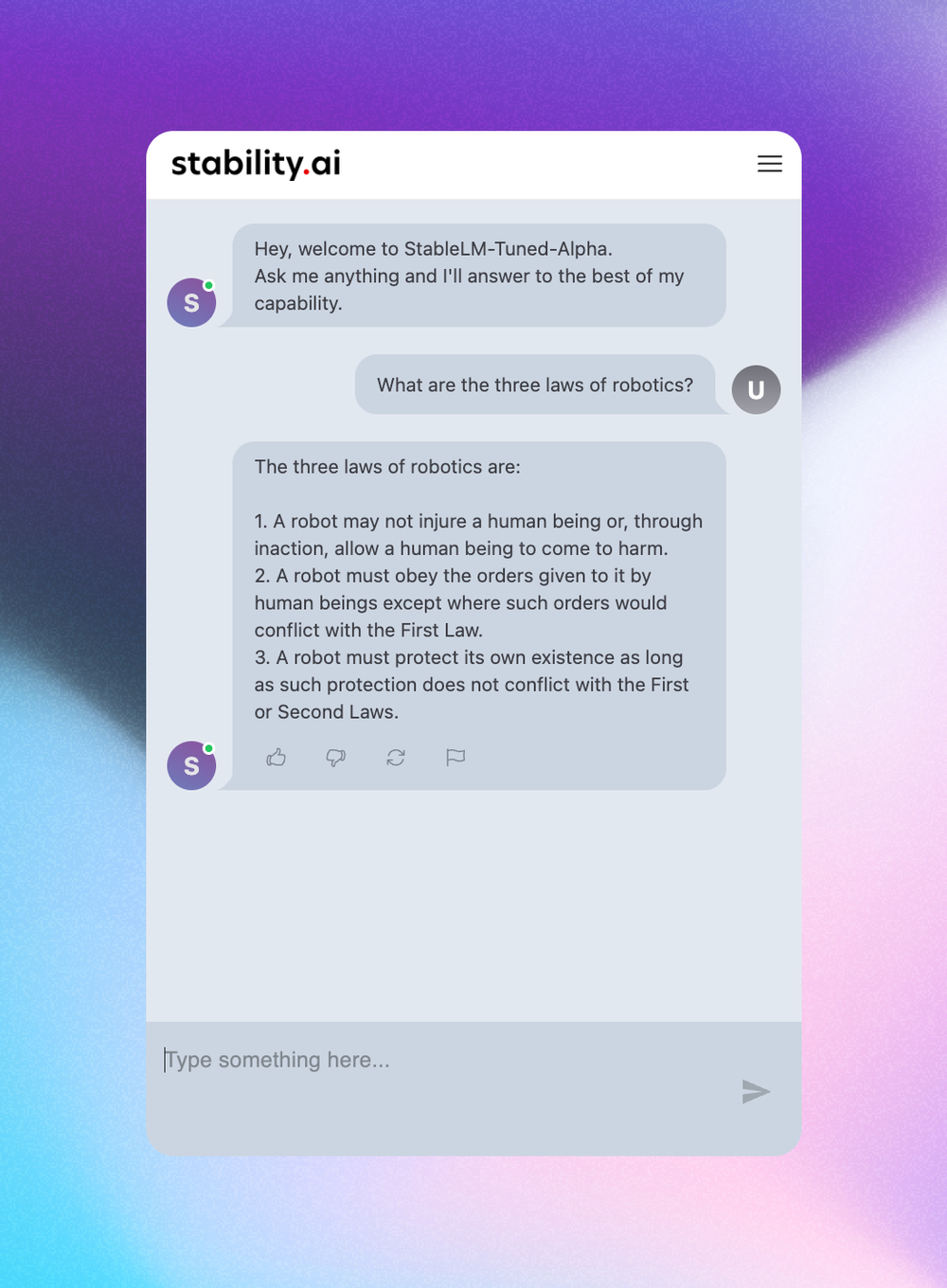
Our Commitment to Continuous Improvement
This is just the beginning for StableVicuna! Over the coming weeks, we will be iterating on this chatbot and deploying a Discord bot to the Stable Foundation server. We encourage you to try StableVicuna and provide us with valuable feedback to help us improve the user experience. For the time being, you can try the model on a HuggingFace space by visiting this link.
Goose on!
Acknowledgments
Big thanks to Duy Phung who trained the StableVicuna model. We’d also like to extend our gratitude to our open-source contributors who have played a crucial role in bringing this project to life.
Philwee who assisted in the evaluation of StableVicuna.
The OpenAssistant team for providing us with early access to their RLHF dataset.
Jonathan from CarperAI for working on the Gradio demo.
Poli and AK from Hugging Face for helping us set up the Gradio demo in Hugging Face.