
Swiss Re & Palantir
Scaling Data Operations with Foundry

Editor’s note: This guest post is authored by our customer, Swiss Re. Authors Lukasz Lewandowski, Marco Lotz, and Jarek Sobanski lead the core technical team responsible for the implementation of Palantir Foundry at the Swiss reinsurer. They have been managing overall platform operations, core architectural principles, site reliability, cost management, and governance for many years.
Introduction
As one of the world’s leading reinsurers, Swiss Re has been at the forefront of understanding risk for over 160 years. In the face of global challenges such as climate change, cyberattacks, and population increases, the company contends with increasingly interconnected risks in its mission to make the world more resilient.
Swiss Re’s workforce of over 14,000 individuals includes both consumers and producers of analytical data. The organisation gathers and generates data on natural catastrophes, life and health insurance, and business and credit risks from a variety of commercial sources.
To maintain agility and enable fast, data-driven decisions, Swiss Re must manage complex data at scale, identify connections between seemingly disparate trends and events, and operationalise these insights for their business function and clients. All of this must be done in compliance with applicable laws, rules, and regulations.
In 2018, we chose to partner with Palantir Technologies to upgrade our decentralised landscape and build a data platform on Palantir Foundry.
Data Platform for the Future
Swiss Re operates a variety of data-intensive applications, spanning origination, underwriting, and pricing to treaty and claims management. These applications further extend to actuarial analysis, solvency stress testing, finance-focused systems for treasury and asset management, and statutory reporting. These systems comprise numerous technologies and patterns, including operational data stores, data warehouses, data brokers, and information hubs.
Traditionally, data and analytics platforms were decentralised, with each function capturing input from its core systems and performing analytics on a platform of its choice. While this approach allowed for flexibility, it did not generate significant company-wide synergies.
To position our organisation for the future, we envisioned a set of objectives aimed at achieving transparency, robust governance and efficient data management, while maintaining a high degree of freedom for sub-organisations. These objectives include:
- Observability and provenance tracking across processes and services: Ensuring ownership of data assets and business logic, leading to clarity of purpose at each step of processing.
- Distinct and unique capabilities: Building a coherent, unambiguous set of technical standards and guidelines that cover the entire data processing spectrum, reducing the need for complementary and niche software.
- Clear links between cost and value: Ensuring transparency of costs across storage, processing, and observability of business logic, allowing for continuous, organisation-wide optimisation.
- Like-minded community: Formulating a cohesive approach to training and upskilling, advocacy, defining best practices, evangelism, and commonality of approach across business units.
To fulfill these objectives, we adopted a data mesh-inspired architecture and platform. The platform’s key focus would be on analytics and decision support applications. At a certain level of maturity, it would also serve as a data sharing platform, facilitating the controlled sharing of analytical outcomes while adhering to data usage restrictions from clients and regulators. To balance effectiveness and efficiency, Swiss Re devised processes to manage complexity and cost, adopting mesh principles for design and governance.

Managing Complexity: Divide and Conquer
Replacing decentralised and heterogenous platforms with a single platform that runs federated workloads greatly reduces technical complexity and avoids tech debt, thus allowing more focus on true value-adding developments. However, lowering the barrier to entry for new software development can also lead to governance challenges.
In response to this, Swiss Re established specific governance boundaries. Each bundle of data and logic is effectively treated as an application — a semi-autonomous unit of logic with designated business and IT ownership. These applications must be registered upfront and assessed across multiple dimensions: purpose, architecture, access controls, and data governance.
Applications are then grouped into domains, which act as digital twins of business units and corporate functions. Each domain assumes ownership and promotes the reusability and harmonisation of application and data assets. Standard Foundry project creation and access control UIs are augmented to enforce Swiss Re’s own naming conventions, ownership, and approval chains, all linked to the company-wide governance toolset. This augmentation is achieved through a combination of Workshop applications and scheduled transforms, which traverse the metadata catalogue to generate statistics, identify exceptions, and block non-compliant resources, such as projects or datasets.
This approach enforces two of the most critical principles of data mesh architecture: Domain Ownership and Self-Service Data Platform.
Implementing the Data Mesh Principles for Federation and Scalability
Centralising data management on a single platform significantly increases transparency but does not guarantee frictionless growth. While governance is ensured by federated ownership of data and applications, the ever-growing complexity of data flows and dependencies requires additional architectural constructs to keep entropy in check.
Consistency and compliance across domains are assured by a set of guidelines, constraining access management and permissible data flows. These guidelines are enforced through project archetypes and ongoing monitoring by the central platform team, which identifies exceptions and addresses them with owners early. Intra-domain, cross-application data flows are generally permitted without constraints, while cross-domain flows require additional scrutiny.
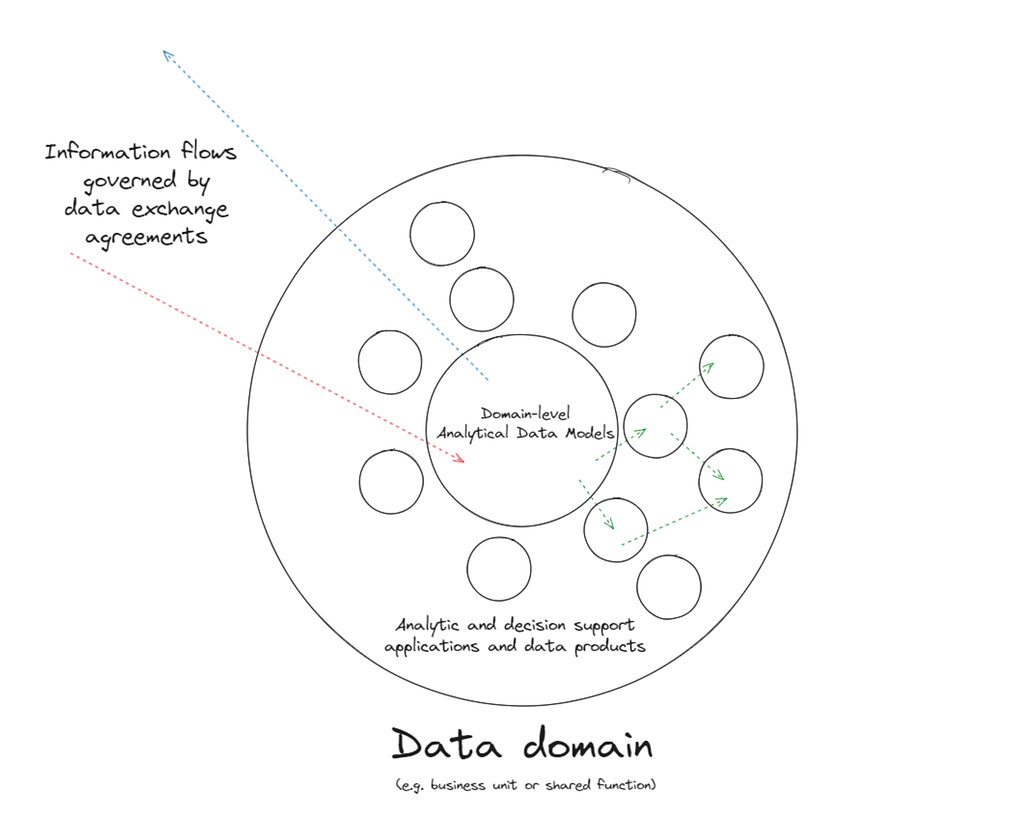
Implicit data exchange agreements are established at the point of implementation, allowing any two applications on the platform to exchange data. For cross-domain transfers, these exchange agreements become more explicit: Swiss Re mandates that the physical implementation of data exchange adheres to essential governance processes, such as identifying data owners and explicitly acknowledging the parameters of the exchange, including content, frequency, and quality.
Additionally, our operating models focus on reusability through alignment of data structures. Each domain maintains its key data assets, known as Analytical Data Models — a special class of data products — at the heart of their application mesh.
To encourage collaboration and data sharing while preventing silos, we rely on access management. The default role of ‘discoverer’ allows platform users to view metadata of all assets without accessing the actual content. We use a single organisation and namespace, achieving domain segregation through groupings of access products coupled with distinct project archetypes. Cross-domain data sharing is facilitated by creating projects that include access products from different domains.
This approach balances clear ownership responsibilities, compliant data access, and the need for transparency and sharing, effectively preventing data silos.
The same model in real life:

Cost-Conscious Petabyte Scale Processing
Palantir Foundry’s rapid application creation capabilities necessitate scalable platform management to keep pace with its velocity. The platform supports two dozen business domains, group functions, and specialised departments, managing several thousand inbound data feeds, and petabytes of data. With nearly half of the Swiss Re workforce using the platform quarterly, and the platform’s infrastructure initially doubling every year, we required a sustainable approach to observe and manage all hosting and processing costs.
The Foundry data platform consumes resources in three primary ways:
- Disk storage: Amount of storage used by dataset files, typically in classic ‘data lake’ blob storage.
- Compute (batch and interactive): Measures the number of vCPUs and the amount of memory used in computational tasks, such as Spark jobs or indexing.
- Indexed storage: Measures infrastructure for ontology-based workflows.
Swiss Re addresses the costs generated by these resources in three ways:
Improving observability: Swiss Re consumes numerous Foundry APIs and builds complementary Foundry datasets with usage information and transaction graphs. This information is analysed by types of usage, branches, predecessors and descendants, storage usage, complexity of query plans, size of datasets versus requested computational resources, etc. This increased observability allowed us to fine-tune data retention policies and reduce the size of the archive by more than 50% (~3.6 PB), without any material loss of functionality or auditability.
Limiting index storage: Index storage is the most expensive singular resource type in Swiss Re’s implementation. While the object layer is extremely useful to accelerate application-building which requires online processing, it comes with an overhead: batch compute (Spark) syncs every row and column to the indexing system (Lucene/Elastic Search), where it is maintained in block storage and memory for querying, often with multiple redundancies, load-balanced REST APIs, etc. It is important to index only what is required, rather than all data sets, columns, and search types for columns, and make conscious decisions about what can be analysed in Contour or Workbooks, versus Quiver and Workshop. Initial review of optimisation candidates and subsequent actions have resulted in a reduction or avoidance of infrastructure cost of up to 40%. Developer training sessions and pro-active monitoring of ‘overweight’ objects are now ongoing processes. Migration to Object Storage V2 has further reduced overheads by syncing only mapped columns.
On-going, dynamic optimisation, especially batch compute: Alerts and early warning mechanisms are necessary to identify redundant or inefficient processes, such as excessive scheduling, large builds of datasets outside the main branch, infrequently used assets, or force-building of unchanged datasets. We also track overprovisioned jobs with disproportionate vCPU or memory requirements through “profile adjustment campaigns.”
We analyse unnecessary column propagation, where columns from parent datasets are transmitted down the pipeline without any subsequent use. To address this, we collect and analyse Spark query plans and reconstruct basic column lineage. Eliminating redundant columns significantly impacts storage and processing, as narrower datasets load faster, require less memory in executors, and ultimately take up less space.
We also monitor projects with high growth rates rather than just high absolute cost to identify potential problems early. This monitoring process alone has yielded cost savings and cost avoidance in the range of 10–15%.
To ensure ongoing impact, we use a collection of Foundry-based tools to surface metrics and highlight exceptions to relevant users:
- Cost Dashboard: Indicates the entire cost per type and per resource, rolling up to applications and domains.
- Platform Dashboard: Comprises multiple platform metrics and computes their statistics in near real-time (average, p95, p99). It also tracks issue handling performance (response time, resolution time, etc.), platform services’ availability, and queue performance.
- Heuristics Dashboard: Monitors over 40 conditions regularly to keep entropy of data flows and their efficiency in check. This includes identifying data flows that contradict enterprise architecture guidelines, unexpected access grants, and unusual usage patterns (e.g., read and write access on certain resources over time, number of users performing these actions).
Since implementing these tools two years ago, we have generated substantial annual savings while more than doubling our user base and processes. These tools are crucial for maintaining a lean platform team, enabling a shift from reactive to proactive operations. This shift allows the team to concentrate on value-adding services such as engineering guidance, governance, and architecture blueprints.

The Elephant In the Room: The AI Revolution
Swiss Re, like many others, have begun the explorative journey to surface opportunities that generative AI, LLMs, and even LMMs, can bring to improving operations of both our insurance and reinsurance core businesses.
Our Ontology represents our organisation as a set of digital twins, and has traditionally leaned on structured data, but is now rapidly expanding with textual information as well. We have long recognised that extending our data mesh with ML processes, and now also with generative AI, is a strategic imperative. In many operational decision contexts that ‘go well beyond chat’, the need to harmonise, categorise and extract information is critical; coming from the myriad of document corpora such as insurance submissions, policies and claims. In order to achieve high levels of automation at a reasonable cost, employing modern AI is only natural.
Given the investments we have made in data ownership, observability, traceability, cost control, and optimisation over the last years, we are poised to navigate the blossoming and rapidly evolving industry from a relatively privileged position. Our data mesh architecture is evolving rapidly toward a data and AI mesh architecture, and the Palantir Foundry & AIP platforms allow us to make great strides in managing our architecture with the same cutting-edge security and governance standards. The high levels of transparency and flexibility the platforms offer help us react to the relentless pace of the AI movement, and to address the emerging regulatory landscape. We’re optimistic the choices we’ve made over the last years will be as important, if not more important, as the AI revolution continues to accelerate.
Conclusion
A single, addressable data space provides Swiss Re with numerous benefits, including:
- Domain-driven design. This preserves the autonomy of business units, enabling short development cycles and reactive solutions to changing requirements. Entire, near-production grade solutions have been incubated within weeks, benefiting from the availability of data, sometimes entirely authored by the information consumers themselves, with minimal support from technical teams.
- User experience cohesion: Familiarity with the visual layer and underlying solution mechanics is carried from domain to domain and user to user, encouraging increased self-service and connectedness between applications.
- Architectural cohesion: This allows Swiss Re to further generalise and refactor on an industrial scale, continually lowering time-to-market and cost-per-solution.
- Increased effectiveness of data governance processes: Prevents misuse and non-compliance by instilling strong information ownership, necessary for continued, scalable growth.
- Lower total cost of ownership: Ongoing optimisations effectively self-finance platform growth.
These transformative benefits underscore the power of a unified data strategy, positioning Swiss Re to not only meet current demands but also to seamlessly scale and innovate for future challenges. By leveraging the Palantir Foundry platform, Swiss Re exemplifies how forward-thinking IT solutions can drive sustainable growth and efficiency across the insurance industry.
Learn more about the Swiss Re — Palantir partnership: https://www.palantir.com/impact/swiss-re/
![]()
Swiss Re & Palantir: Scaling Data Operations with Foundry was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.