Wan-Animate is wild! Had the idea for this type of edit for a while and Wan-Animate was able to create a ton of clips that matched up perfectly.
submitted by /u/luckyyirish [link] [comments]
submitted by /u/luckyyirish [link] [comments]
My heart is shattered… Tl;dr from the discord member weiss: Some people from invoke team joined Adobe and no longer working for invoke Invoke is still a separate company from Adobe and part of the team leaving means nothing to Invoke as a company and Adobe still has no hand on Invoke Invoke as an …
The main idea for this video was to get as realistic and crisp visuals as possible without the need to disguise the smeared bland textures and imperfections with heavy film grain, as is usually done after heavy upscaling. Therefore, there is zero film grain here. The second idea was to make it different from the …

I’v been trying different prompt to get a 180 camera rotation, but just got subject rotation, so i tried 90 degrees angles and it worked, there are 3 prompt type: A. Turn the camera 90 degrees to the left/right (depending on the photo one work best) B. Turn the camera 90 degrees to the left/right, …
Read more “Qwen Edit – Sharing prompts: Rotate camera – shot from behind”
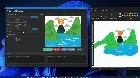
Hey everyone! 👋 I’ve just released something I’ve been working on for a while — ScreenDiffusion, a free open source realtime screen-to-image generator built around Stream Diffusion. Think of it like this: whatever you place inside the floating capture window — a 3D scene, artwork, video, or game — can be instantly transformed as you …
Read more “Introducing ScreenDiffusion v01 — Real-Time img2img Tool Is Now Free And Open Source”
submitted by /u/Fill_Espectro [link] [comments]

Got bored seeing the usual women pics every time I opened this sub so decided to make something a little friendlier for the work place. I was loosely working to a theme of “Scandinavian Fishing Town” and wanted to see how far I could get making them feel “realistic”. Yes I am aware there’s all …
Read more “An experiment with “realism” with Wan2.2 that are safe for work images”
submitted by /u/Jeffu [link] [comments]
Just wondering, this has been a head-scratcher for me for a while. Everywhere I look claims DoRA is superior to LoRA in what seems like all aspects. It doesn’t require more power or resources to train. I googled DoRA training for newer models – Wan, Qwen, etc. Didn’t find anything, except a reddit post from …
Read more “Why are we still training LoRA and not moved to DoRA as a standard?”
submitted by /u/alcaitiff [link] [comments]