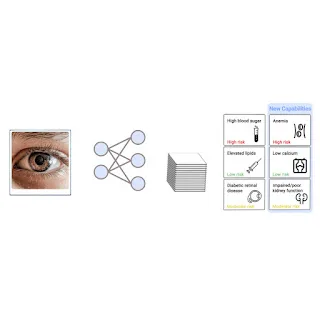
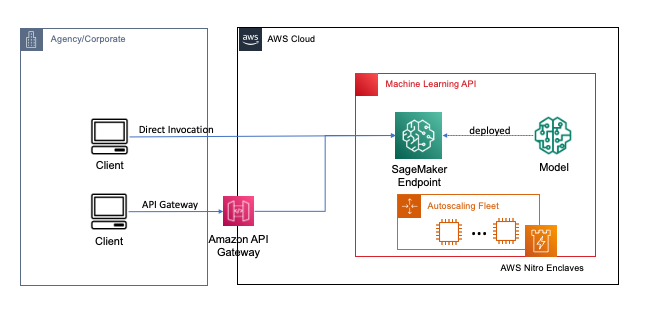
Palantir Polska: Często zadawane pytania
(Scroll down for English translation below) W przestrzeni publicznej pojawia się wiele pytań dotyczących działalności Palantira. Biorąc pod uwagę duże zainteresowanie naszą firmą, zebraliśmy pytania, które stawiane są najczęściej i tym wpisem na blogu, chcielibyśmy na nie odpowiedzieć. Czym jest Palantir? Palantir Technologies to międzynarodowa firma technologiczna założona w 2003 roku w Dolinie Krzemowej. Obecnie …