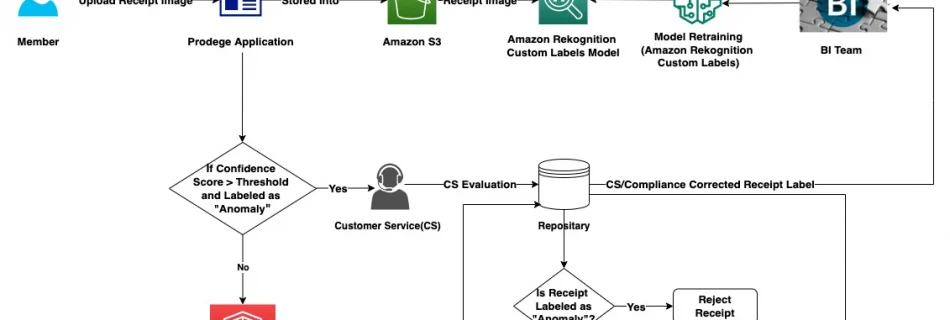
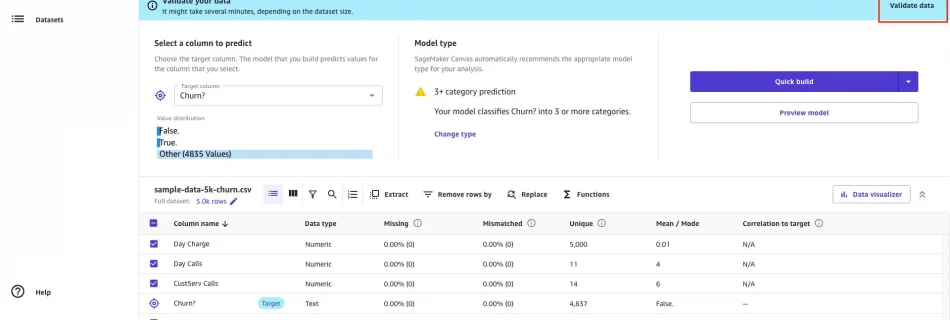
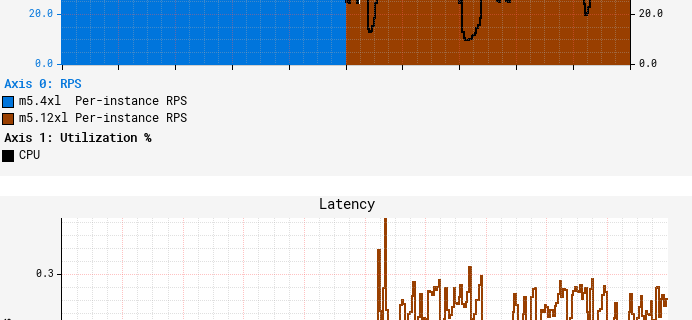
Amazon SageMaker Studio Lab continues to democratize ML with more scale and functionality
To make machine learning (ML) more accessible, Amazon launched Amazon SageMaker Studio Lab at AWS re:Invent 2021. Today, tens of thousands of customers use it every day to learn and experiment with ML for free. We made it simple to get started with just an email address, without the need for installs, setups, credit cards, …