
By Ruben Stroh, Palantir Deployment Strategist
Introduction
Since the launch of AIP, Palantir has worked with a wide spectrum of customers to deploy AI-centric process mining & automation workflows that save time, money, and resources. Today we’ll walk through a notional, step-by-step example of how to build this kind of solution with AIP.
But before we dive in, let’s take a step back: why is process mining important? As we’ve seen at Palantir time and time again, organizations run on a myriad of processes. When processes function optimally, businesses can keep customers satisfied, do more with less, and hit their targets. When they don’t, there can be massive impacts — dissatisfied customers, forgone revenue, wasted resources, and more.
So how do we go about ensuring that processes are functioning optimally? Once we’ve done that, how do we implement scalable, sustainable change?
At its core, this is a matter of:
- Understanding the operational reality of how a given process is functioning. While many organizations believe that they fully understand how their processes work, the reality is that the day-to-day can look very different from process documentation and slideshows about expected flows and exception management. Few companies have granular, near real-time visibility into how their processes are functioning. To be able to improve a process, you need to have this visibility so that you can understand how the process interacts with the broader operational reality of the enterprise.
- Making better decisions, faster. Based on all the information we have about a given customer, should we fulfill that order? When we are short on a particular product, can we safely substitute it with another? What downstream effects will these choices have? At many enterprises, this kind of decision-making is slow, labor-intensive, and done in operational and informational silos. However, using AI-centric logic, companies can make these decisions quicker and in a more informed way.
In this post, we will walk through how to achieve both of these goals with AIP.
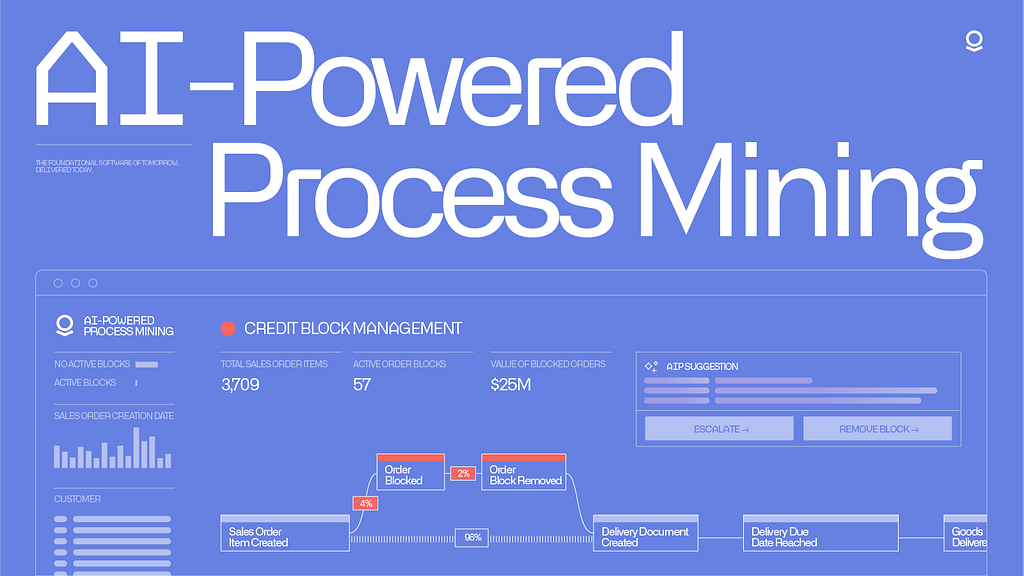
Using the example of credit blocks in the order-to-cash process for a notional company (Titan Industries), we’ll demonstrate how AIP enables you to quickly understand and analyze a given process, incorporate this understanding into the decision-centric model of your enterprise (the Palantir Ontology), and deploy AI-powered solutions to address bottlenecks — in this case, credit blocks — through enhanced, accelerated decision-making.

As background, the purpose of credit blocks in the order-to-cash process is to block orders from being fulfilled where there is a high risk of the customer not paying for the order. These blocks can be problematic, especially in cases where they delay order fulfillment for customers who have historically paid on time, as identifying and removing them can be a lengthy process.
Let’s dive in.
Sync Process Data with HyperAuto
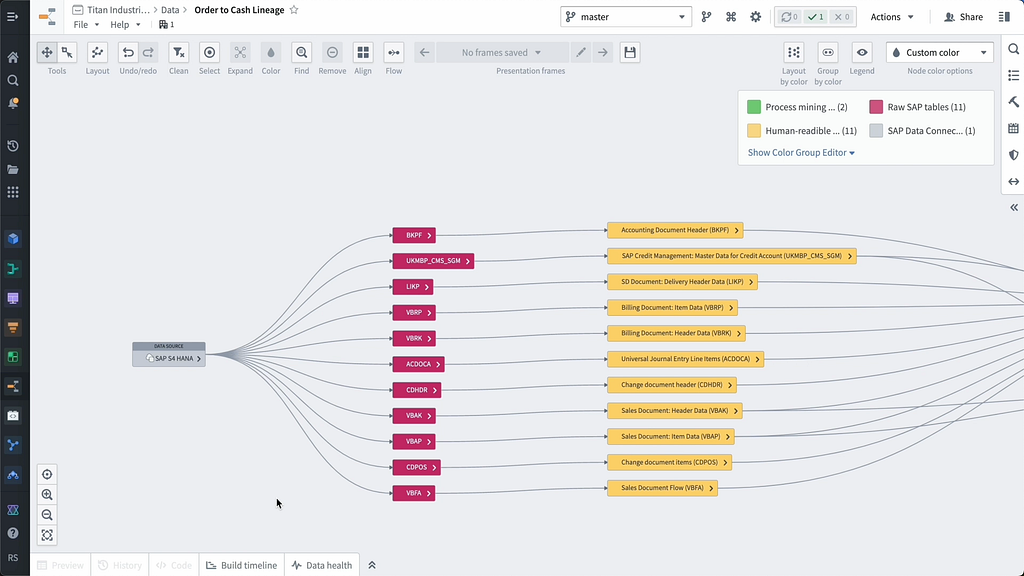
To start, we need to bring in the relevant source data from the systems that are used for the order-to-cash process and put it into a format that will enable process mining.
Palantir HyperAuto — also known as Software-Defined Data Integration, or SDDI — allows you to not only connect to common ERP and CRM systems (including SAP, Salesforce, Oracle NetSuite, and Hubspot), but also to programmatically generate data pipelines that clean, normalize, and harmonize datasets into a cohesive data asset at speed.
Titan Industries’ order-to-cash process operates in SAP. Given that we already have an SAP connection built, we’re able to deploy a HyperAuto pipeline out-of-the-box. When configuring the pipeline, we can take advantage of numerous time-saving features — e.g., generating automatic joins as well as primary and foreign keys, and translating column and table names into human-readable format.
Now that we have cleaned, synced, and made our order-to-cash data human-interpretable, we need to put it into the right format for process mining.
Transform Data with Pipeline Builder

To prepare our SAP order-to-cash data for process mining, we need to create two datasets:
- Process object dataset: this describes the type of object that is moving through the process in question. In a car manufacturing process, this would be the vehicle; in a recruiting process, this is the candidate moving through the different interview stages. In this case, it’s a sales order item that is moving through the order-to-cash process.
- Log object dataset: this describes the steps that a certain process object moves through. To enable process mining, you only need three columns: the primary key of the process object (in our example, the reference to the sales order item), the current state (i.e., the stage in the process), and the timestamp at which the process object entered this stage.
We can use Pipeline Builder to bring the synced SAP data into these two schemas. Pipeline Builder is Palantir’s low-code/no-code tool for developing production-grade data pipelines. In Pipeline Builder, we’re able to quickly apply transformations, choose from a library of hundreds of functions to execute almost any kind of transformation, and build scalable pipelines quickly.
Here, we’re able to quickly and easily put the synced SAP data on Titan’s order-to-cash process into our schema, and create a cohesive log dataset that combines these different datapoints. With this, we’ve created the backing dataset of our process logs.
We’re now ready to connect this to Titan Industries’ ontology.
Develop a Process Mining Ontology
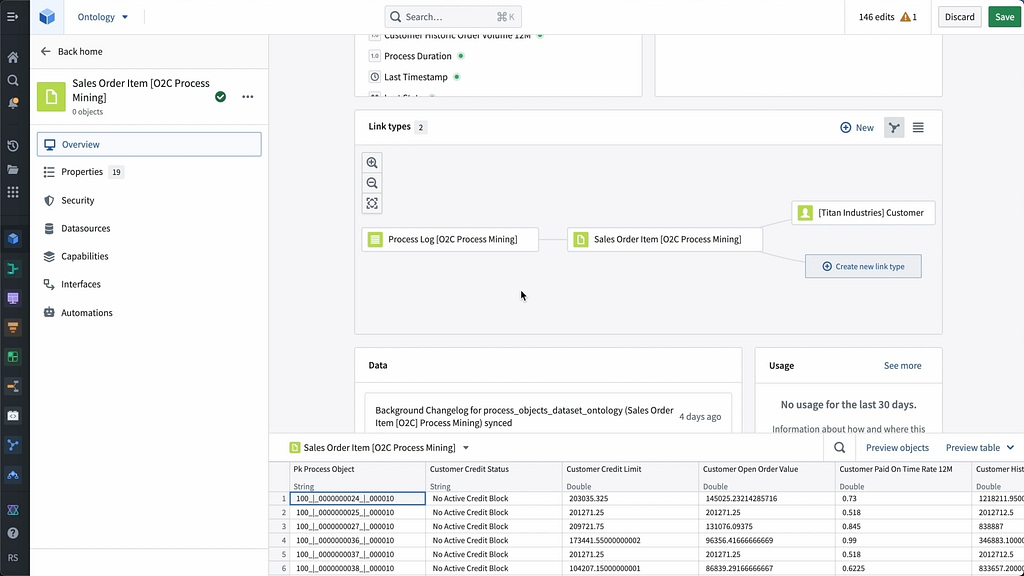
The Ontology is the decision-centric model of the enterprise — the data, logic, and actions that drive day-to-day decision-making. It is the foundation for Titan Industries’ data-driven workflows, and contains the context for the company’s operations.
To ensure that we’re operating as part of the broader enterprise-wide feedback loop and taking advantage of the interwoven relationships that already exist in Titan’s ontology — e.g., how a sales order might affect a particular production line — we need to make the order-to-cash workflow part of Titan’s ontology. To do that, we’ll create an order-to-cash ontology and link it to Titan Industries’ existing ontology.
We start by creating ontology objects for the order-to-cash ontology, which we are able to do in the dataset preview in Pipeline Builder. We can then define these objects in the Ontology Manager (e.g., assigning a name, configuring access management, calibrating property metadata) and link them to the other objects in Titan’s ontology. This involves defining the relationships between these objects; for example, a sales order is always connected to a specific customer.
Linking the order-to-cash data to the broader Titan ontology is an essential step in setting our AI tools up for success: the more faithful this decision-centric model is to Titan’s day-to-day operations, the more effectively we can put our AI tools to work.
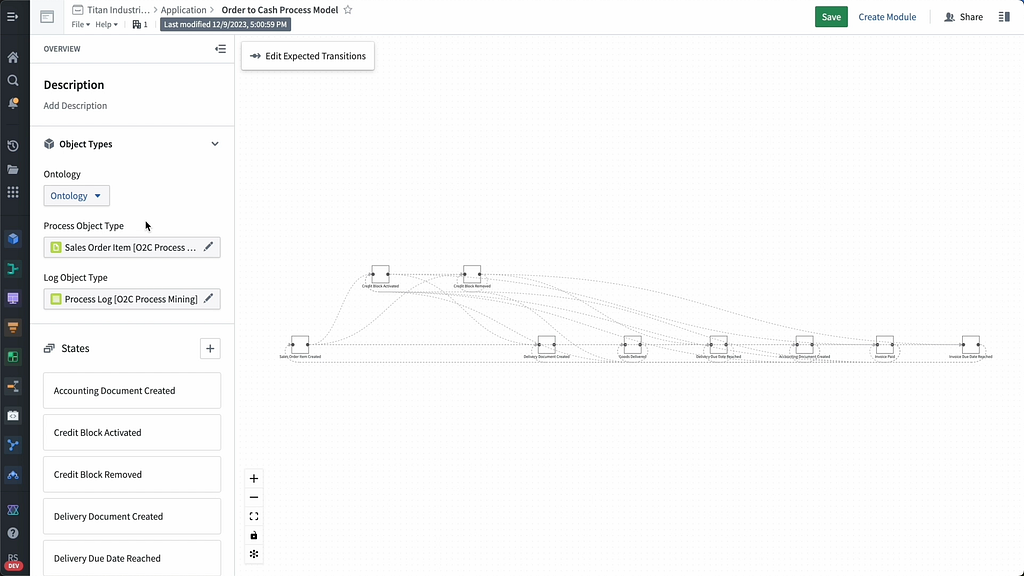
Now that we have this piece of Titan’s ontology built, we can utilize the point-and-click interface in Machinery to create an ontology-driven representation of the order-to-cash process. This Machinery path will provide us with an easy-to-navigate view of expected behavior and associated deviations, and allow us to investigate both at the level of individual steps and overall trends. We’ll then be able to use this model to take action to improve this process using the AI-driven tools throughout the Palantir platform.
To start, we pull in the ontology objects that we created from the order-to-cash process data, which contain the data on the attributes of the sales order items and their associated logs (the states that these items are moving through and the associated timestamps).
Machinery is then able to interpret this data to create an interactive representation of the order-to-cash process flow as it currently functions at Titan Industries. From there, we can investigate the steps in the process where credit blocks are activated at various levels of granularity, laying the foundation for the AI-centric resolution workflow we’re going to build.
Build a Process Mining Application with Workshop
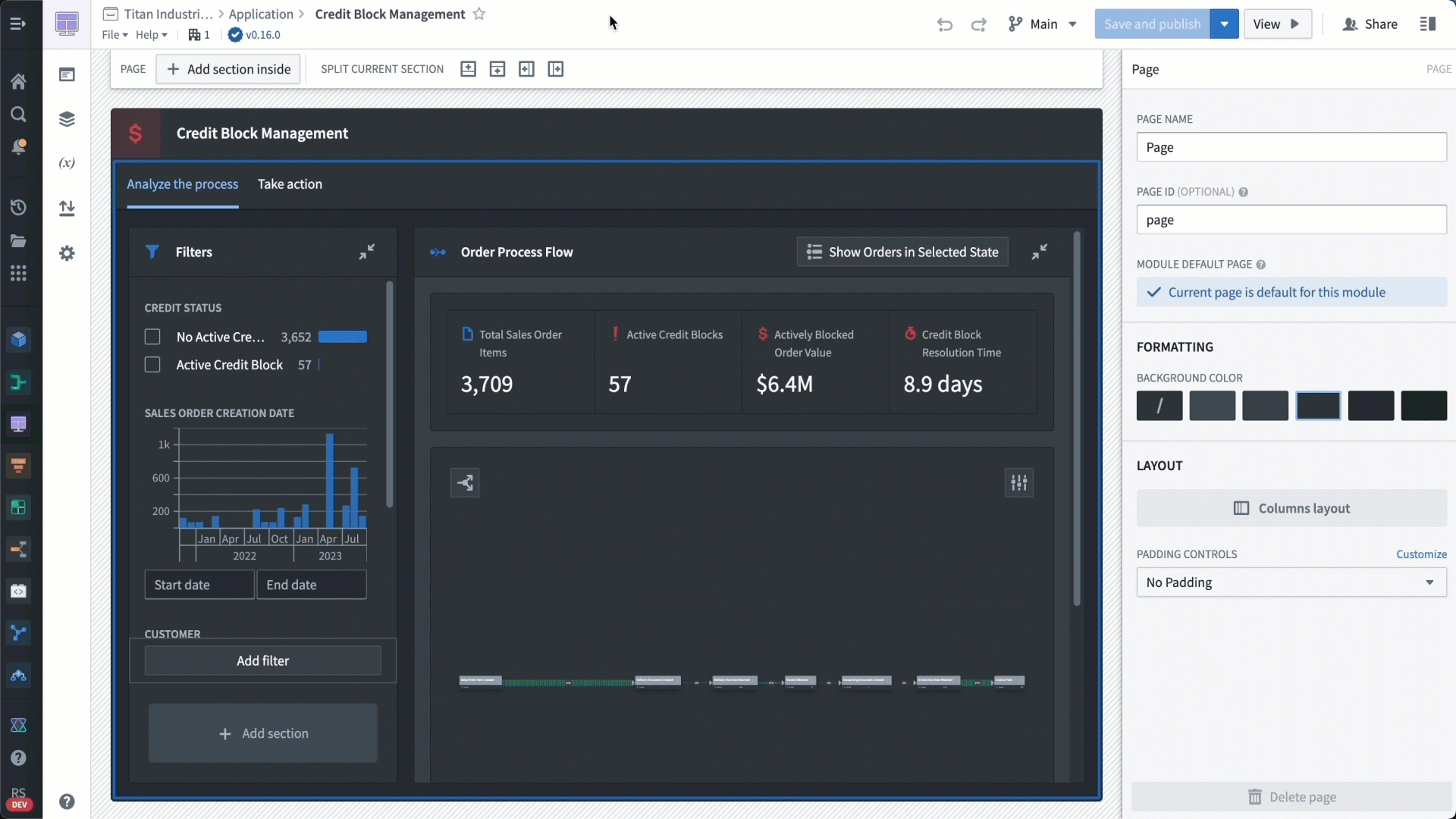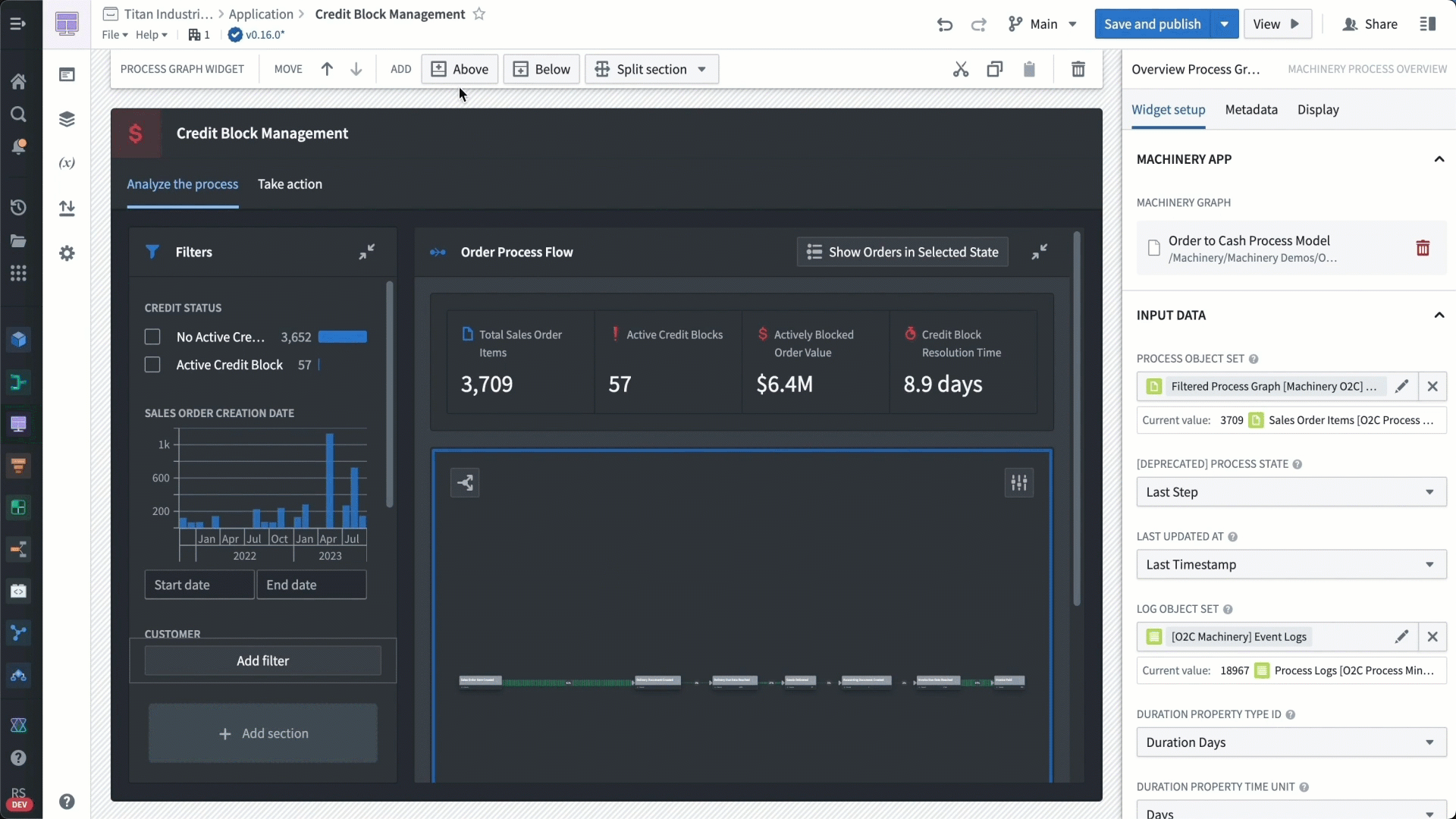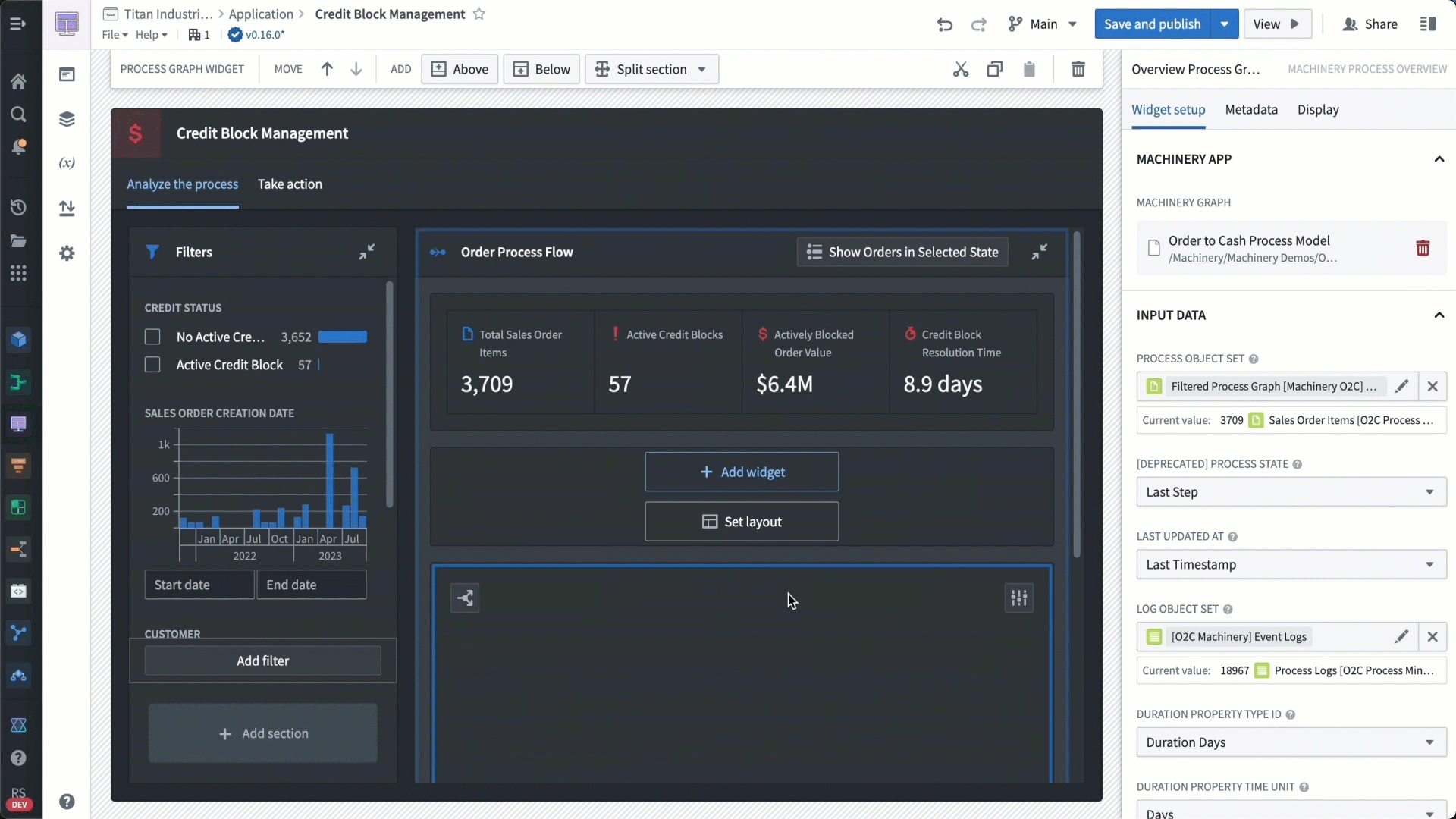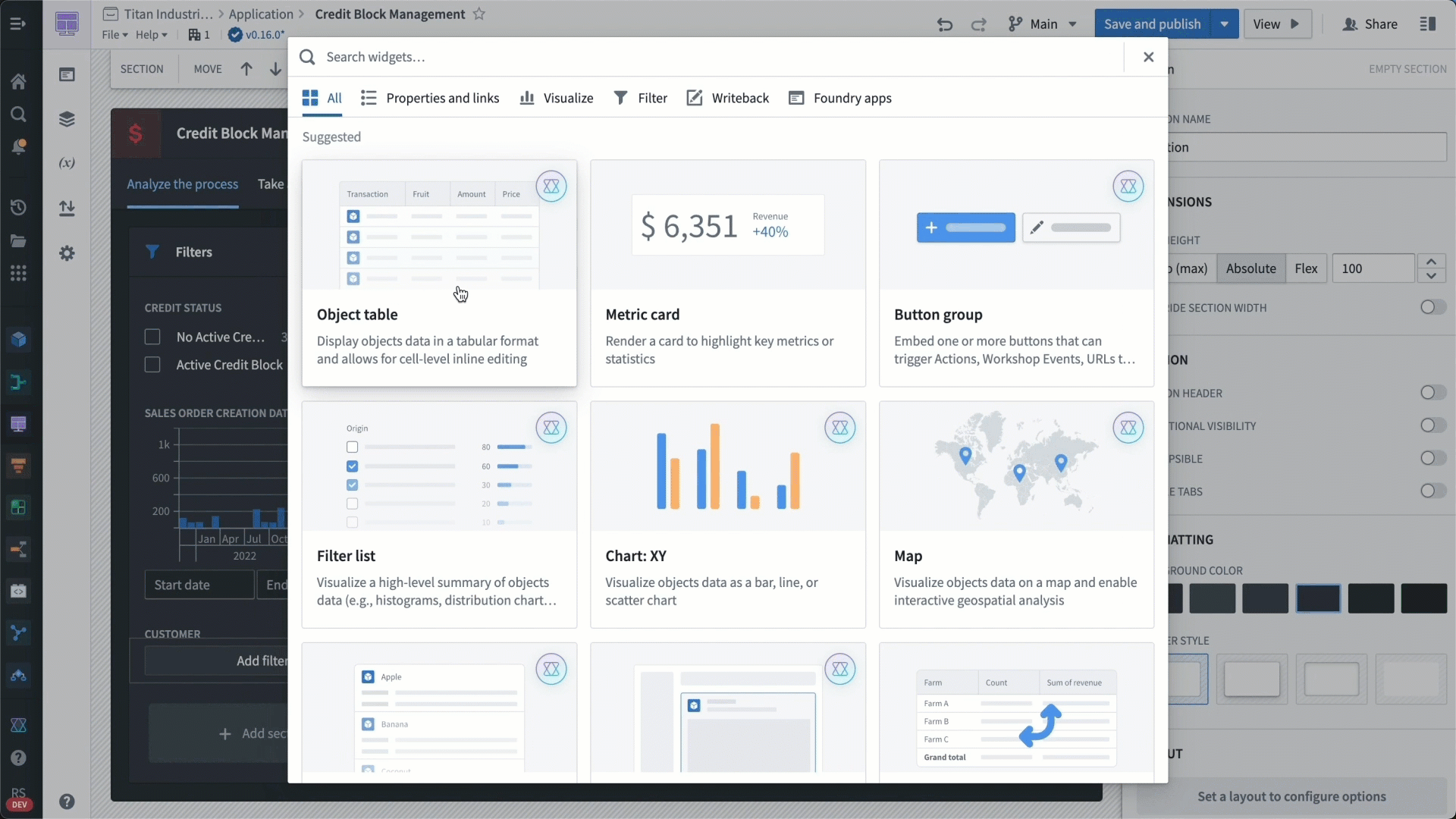
Now that we’ve built a model of our process with Machinery, we want business users and analysts to be able to interact with it. To do that, we’ll embed it in a Workshop application. Workshop enables application builders to create interactive and high-quality applications for operational users; it’s a simple, drag-and-drop way to build out frontends.
This application that we’re building is essentially a collection of Workshop widgets — for example, the process model is just a widget that we can embed in the final application.
With Workshop, we’re able to quickly build an end-to-end process mining application with views for operational users, containing all the relevant information they need to make a decision about these credit blocks.
Now we want to take things a step further and build an AI copilot to make decision-making even more efficient.
Set up a Decision-Making Copilot with AIP Logic
At this point, we’ve mined the order-to-cash process with Machinery and built a basic Workshop application that enables business users to manage credit blocks. Next, we want to make this manual application AI-centric and be in a position to automate AI-orchestrated decision-making — while keeping a human in the loop.
To do this, we’ll use AIP Logic. AIP Logic is a no-code development environment for building, testing, and releasing functions powered by LLMs; it enables builders and architects to embed generative AI in the form of LLMs into essentially any workflow, all while leveraging the Ontology.
In this case, we want to build an LLM-powered function that will propose a decision on whether to maintain or deactivate credit blocks and show us the reasoning behind its recommendation. We can approach this as if we were teaching an intern how to perform this task — someone who is intelligent, but lacking context and background.
We can leverage AIP Logic’s intuitive interface to select an object from Titan’s ontology for the LLM to work with — in this case, the sales order item. We then store specific properties from this object as parameters so we can reference them while teaching the LLM how to perform its task (e.g., credit status, order ID, customer credit limit, 12-month historic order volume).
We can then — in plain text — instruct the LLM on how to perform its task (no code necessary).
We start by providing high-level instructions. Next, we need to define the properties to explain them to the LLM, e.g., telling it that the 12-month paid on time rate is a value between 0 and 1 that indicates how often a given customer has paid on time (the closer to 1, the better).
We then provide the LLM with a set of rules to check for using these parameters — essentially, a rubric with which to make recommendations. For example, we tell the LLM that if the order value in question is substantially above the credit limit and historical order values, and the customer has a low paid-on-time rate, then it should likely maintain a credit block that has been activated.
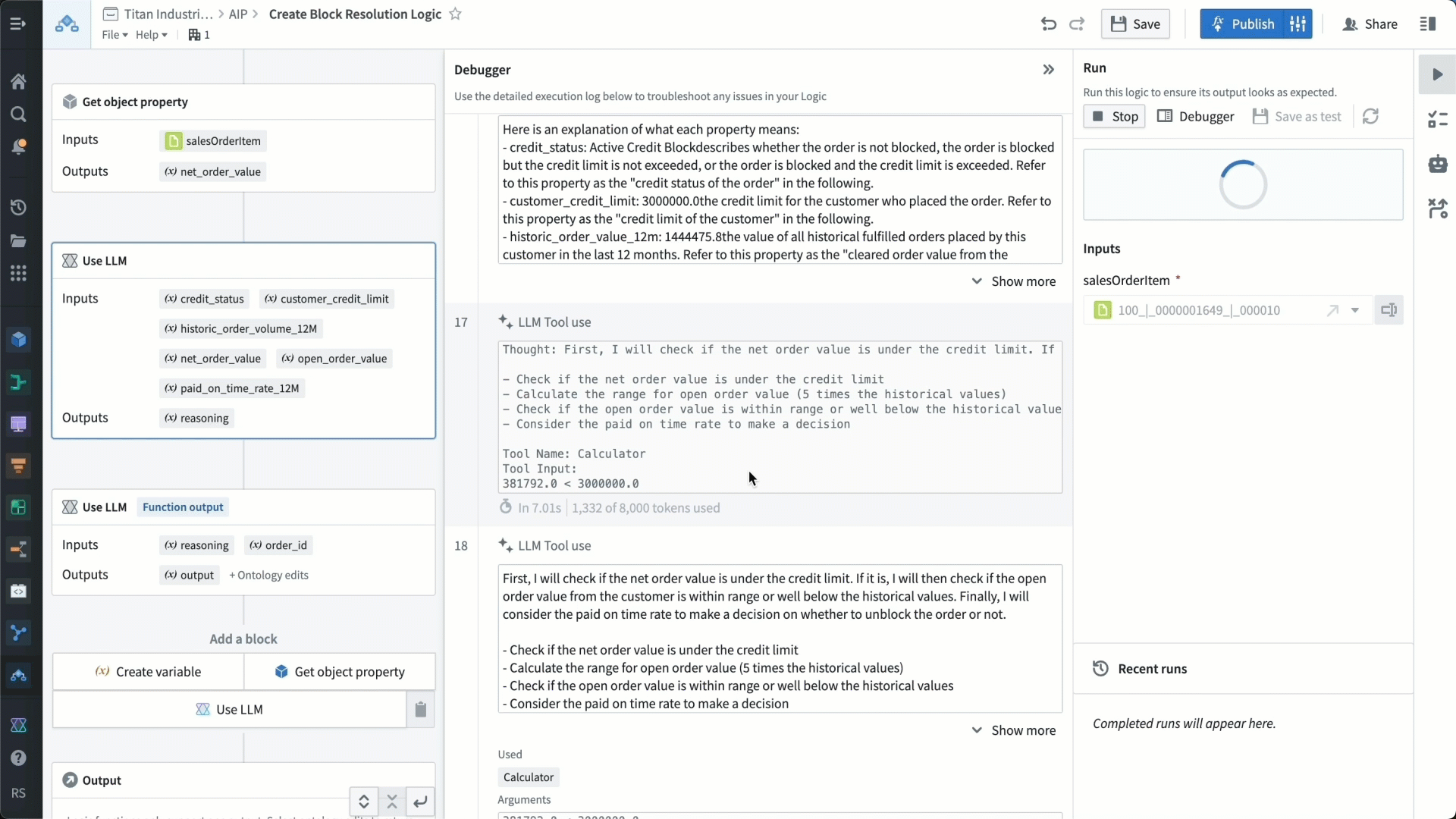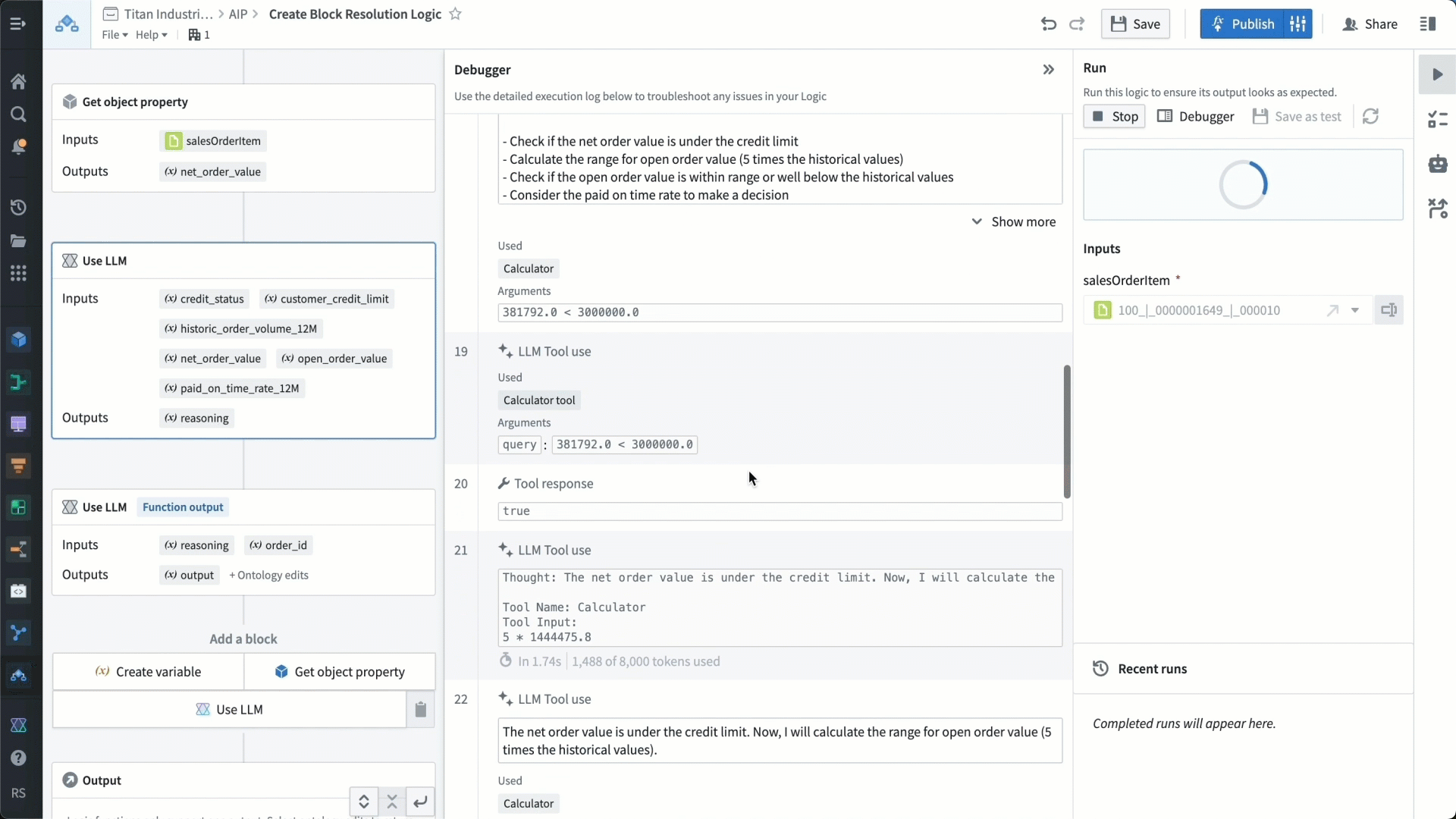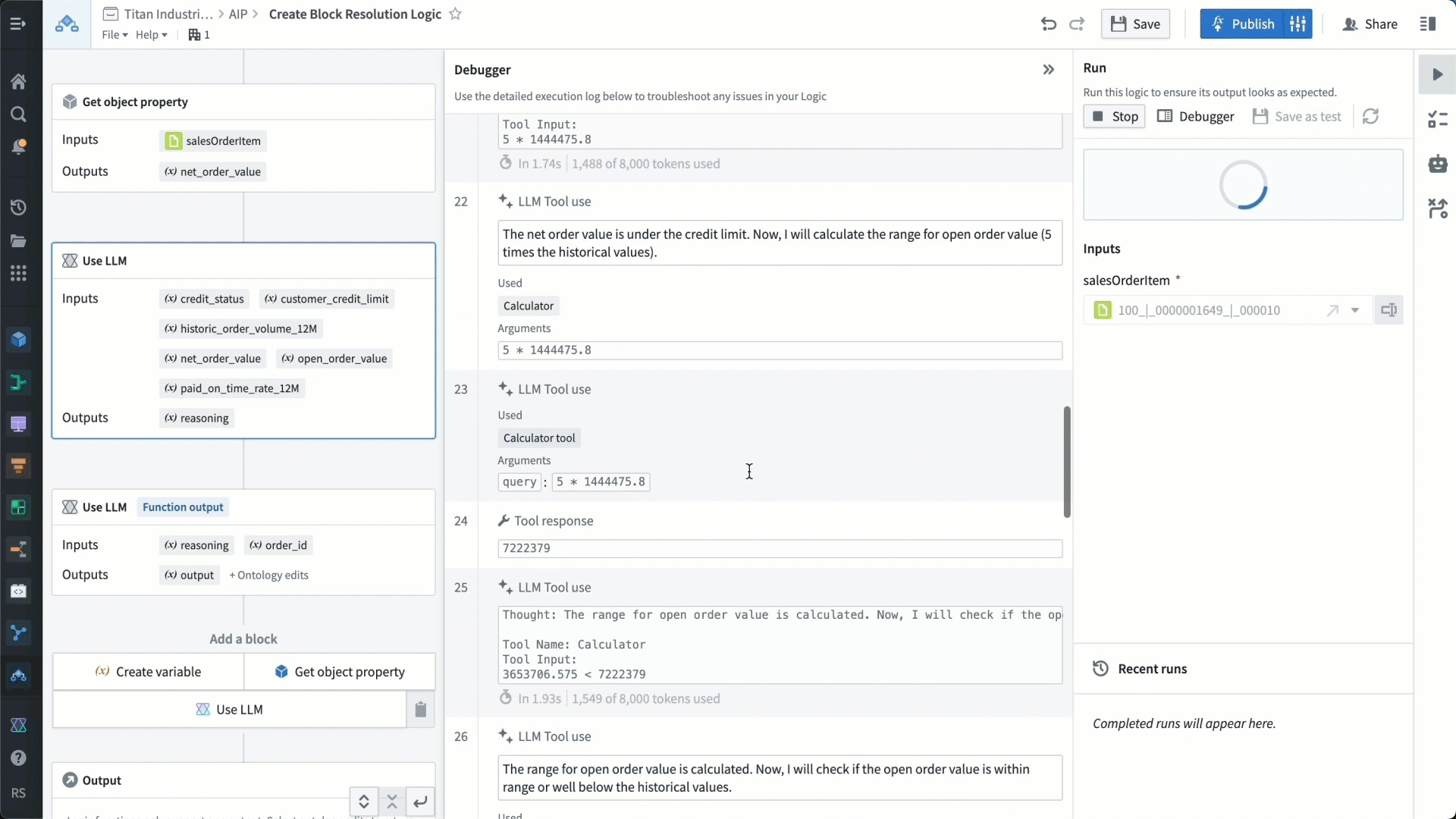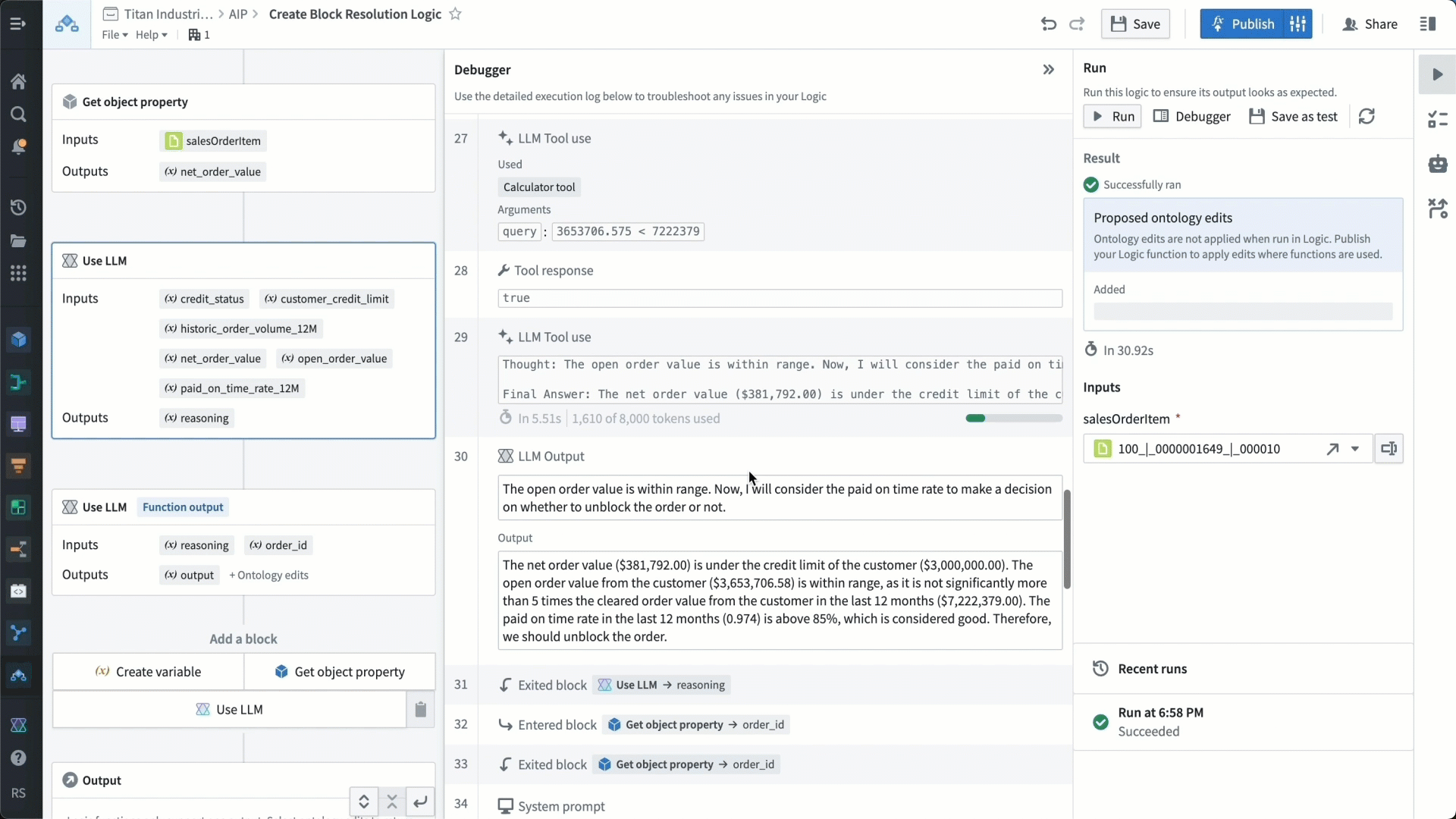
Once the LLM has arrived at a recommendation, we want it to provide its reasoning for a certain conclusion, which we store in a variable so that we can refer to it later — we want to make sure that both this decision and the reasoning behind it are stored in Titan’s ontology.
We’re able to test our function with the debugger to make sure it’s working as expected. The debugger shows us how the LLM is understanding all the different instructions, and we can verify that it is acting on these instructions in the way we want it to.
Now we want to incorporate this into an application that our business users can deploy, which we can again do in Workshop.
We now have an application that, for a given credit block, provides a recommendation for resolution — either maintaining or deactivating the credit block — and the reasoning behind this recommendation. Operational users can now make informed, data-driven decisions in minutes.
Orchestrate Process Decisions with Automate

Now that we’ve built this end-to-end, AI-powered process mining workflow, there are ways to further bolster efficiency — without sacrificing safety. We can configure trigger-based automations, which will invoke the LLM-backed functionality as new data flows into the platform; we could also set these automations to run on a schedule (e.g., every few minutes) if we prefer to maintain or deactivate credit blocks on a periodic basis. In addition, we can leverage AIP’s full range of health frameworks and granular security capabilities to enable robust collaboration as we further evolve the core workflow.
Conclusion
If you want to learn more about how AIP can work for your enterprise, sign up for an AIP Bootcamp today. You’ll get hands-on experience with AIP and build production-ready workflows in a matter of days (or even hours).
Until next time!
Ruben
![]()
Building with Palantir AIP: AI-Powered Process Mining was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.