New generative AI tools open the doors of music creation
Our latest AI music technologies are now available in MusicFX DJ, Music AI Sandbox and YouTube Shorts
Our latest AI music technologies are now available in MusicFX DJ, Music AI Sandbox and YouTube Shorts
Pretraining robust vision or multimodal foundation models (e.g., CLIP) relies on large-scale datasets that may be noisy, potentially misaligned, and have long-tail distributions. Previous works have shown promising results in augmenting datasets by generating synthetic samples. However, they only support domain-specific ad hoc use cases (e.g., either image or text only, but not both), and …
Read more “CtrlSynth: Controllable Image-Text Synthesis for Data-Efficient Multimodal Learning”
This post is cowritten with Greg Benson, Aaron Kesler and David Dellsperger from SnapLogic. The landscape of enterprise application development is undergoing a seismic shift with the advent of generative AI. SnapLogic, a leader in generative integration and automation, has introduced the industry’s first low-code generative AI development platform, Agent Creator, designed to democratize AI …
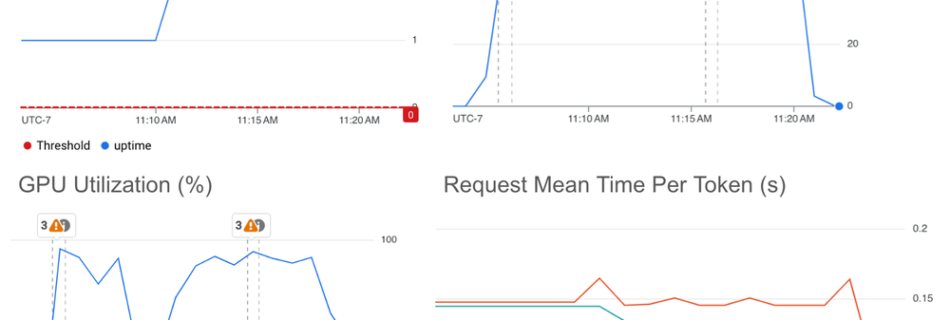
While LLM models deliver immense value for an increasing number of use cases, running LLM inference workloads can be costly. If you’re taking advantage of the latest open models and infrastructure, autoscaling can help you optimize your costs — ensuring you’re meeting customer demand while only paying for the AI accelerators you need. As a …
Read more “Save on GPUs: Smarter autoscaling for your GKE inferencing workloads”
To stay competitive, businesses across industries use foundation models (FMs) to transform their applications. Although FMs offer impressive out-of-the-box capabilities, achieving a true competitive edge often requires deep model customization through pre-training or fine-tuning. However, these approaches demand advanced AI expertise, high performance compute, fast storage access and can be prohibitively expensive for many organizations. …
Read more “Generative AI foundation model training on Amazon SageMaker”
At Google Cloud, we’ve taken an open approach in building our Vertex AI platform — to provide the most powerful AI tools available along with unparalleled choice and flexibility. That’s why Vertex AI delivers access to over 160 models — including first-party, open-source, and third-party models — so you can build solutions specifically tailored to …
Read more “Announcing Anthropic’s upgraded Claude 3.5 Sonnet on Vertex AI”
The growing demand for personalized and private on-device applications highlights the importance of source-free unsupervised domain adaptation (SFDA) methods, especially for time-series data, where individual differences produce large domain shifts. As sensor-embedded mobile devices become ubiquitous, optimizing SFDA methods for parameter utilization and data-sample efficiency in time-series contexts becomes crucial. Personalization in time series is …
Read more “Efficient Source-Free Time-Series Adaptation via Parameter Subspace Disentanglement”

From Prototype to Production (Engineering Responsible AI, #3) Testing and Evaluating AI Systems with AIP Evals Editor’s Note: This is the third post in a series on responsible AI. Proof Over Promises: The Challenge of Making AI Work While it’s relatively easy to create a prototype AI system using Generative AI, addressing your organization’s most pressing challenges with …
Today, we’re pleased to announce the general availability (GA) of Amazon Bedrock Custom Model Import. This feature empowers customers to import and use their customized models alongside existing foundation models (FMs) through a single, unified API. Whether leveraging fine-tuned models like Meta Llama, Mistral Mixtral, and IBM Granite, or developing proprietary models based on popular …
Read more “Amazon Bedrock Custom Model Import now generally available”
*Equal Contributors Current multimodal and multitask foundation models like 4M or UnifiedIO show promising results, but in practice their out-of-the-box abilities to accept diverse inputs and perform diverse tasks are limited by the (usually rather small) number of modalities and tasks they are trained on. In this paper, we significantly expand upon the capabilities of …
Read more “4M-21: An Any-to-Any Vision Model for Tens of Tasks and Modalities”