
From Prototype to Production (Engineering Responsible AI, #3)
Testing and Evaluating AI Systems with AIP Evals

Editor’s Note: This is the third post in a series on responsible AI.
Proof Over Promises: The Challenge of Making AI Work
While it’s relatively easy to create a prototype AI system using Generative AI, addressing your organization’s most pressing challenges with AI requires solutions that perform reliably in production. At Palantir, we go beyond mere proofs-of-concept; we are dedicated to delivering software that powers AI solutions that work consistently and effectively in real-world environments.
In our Engineering Responsible AI blog series, we explore the complexities of Generative AI models. These models often hallucinate, producing outputs that aren’t grounded in reality, and their inner workings lack transparency and explainability. Furthermore, even correct answers can vary based on minor changes to a model’s prompt or parameters. Despite these challenges, we know from experience that Generative AI holds significant promise for solving mission-critical problems — from inventory entity resolution to infection risk alerting — in real-world, operational settings. So, the crucial question for enterprises using Generative AI is: how can we transition our prototypes to production with confidence and speed?
We believe that rigorous Testing & Evaluation (T&E) of AI systems is essential for transitioning to production. That’s why we’ve partnered closely with our customers to develop the necessary tools within Palantir AIP to conduct robust T&E on Generative AI systems. These tools are designed to handle non-determinism, debug specific inputs, and iterate efficiently on prompts and other model parameters. Such capabilities empower organizations to make data-driven, iterative improvements to the AI systems built on our platform. In this and the next blog post in our Engineering Responsible AI series, we will dive into all things T&E and discuss the tools in AIP that can help transition an AI workflow from prototype to production.
T&E for Generative AI
T&E is more than a checkbox — it’s an essential process encompassing a variety of critical workflows. From computing aggregate performance metrics in a dashboard to understanding specific failures presented by model inputs, T&E is crucial for ensuring the reliability of AI systems. To ensure AI systems perform as expected and do not produce unforeseen or harmful outcomes, rigorous testing throughout the AI lifecycle is imperative. Robust T&E is not just about operational performance; it’s about building trust. When organizations trust their AI systems, they are empowered to scale AI use across their enterprise to tackle their most pressing challenges.
At Palantir, we have long underscored through our products, principles, and public policy positions that T&E is the cornerstone of building responsible, safe, and reliable AI systems. In AIP, we’ve specifically built new T&E capabilities to address the fact that T&E for Generative AI looks different than T&E for more “traditional” AI/ML problems, like classification, object detection, or regression. For example, in “traditional” AI/ML T&E, we often want to view aggregate evaluation results over a large evaluation dataset to understand how the model generalizes across diverse inputs. While this is also true for Generative AI, Generative AI provides AI developers a unique opportunity to take specific failures from test cases and more readily improve the AI system through prompt engineering, augmenting the model with data, and providing tools for handoffs.
This open-ended nature of iteration with Generative AI shares a lot in common with continuous improvement workflows in modern software engineering, such as using debuggers, version control, and integrated development environments. Similarly, the approach for T&E for Generative AI can draw from testing techniques in software engineering, bringing the same debugging and unit testing tools that engineers use to build reliable software systems to the AI developer. AIP provides these kinds of T&E capabilities with AIP Evals, which combines the best of the evaluation frameworks we expect from “traditional” AI/ML T&E with the iterative, empirical testing workflows we rely on in software engineering.
In the rest of this blog post, we dive into how AIP Evals brings the software engineering concept of “unit” testing into your AI T&E strategy. This enables you to iteratively improve Generative AI workflows written in AIP Logic and ensure that the AI solutions you deploy are trusted, reliable, and capable of driving transformative change. In the next blog post, we’ll build on this approach to T&E for Generative AI and cover more advanced strategies unique to the Generative AI context.
Unit Testing AI Systems in AIP Evals
Example Overview
To illustrate how T&E in AIP can help transition your prototypes to production, consider an example from our hypothetical manufacturing company, Titan Industries. At Titan Industries, the product quality team is responsible for handling product recalls. They receive daily defect reports, which might suggest that an entire product line needs to be recalled. Each product has a unique recall manual outlining the issues that could trigger a product-wide recall. Triaging these recalls is a manual and labor-intensive process. To streamline this workflow, we developed a function in AIP Logic’s no-code development environment (for building, testing, and releasing functions powered by LLMs). Let’s take a closer look.
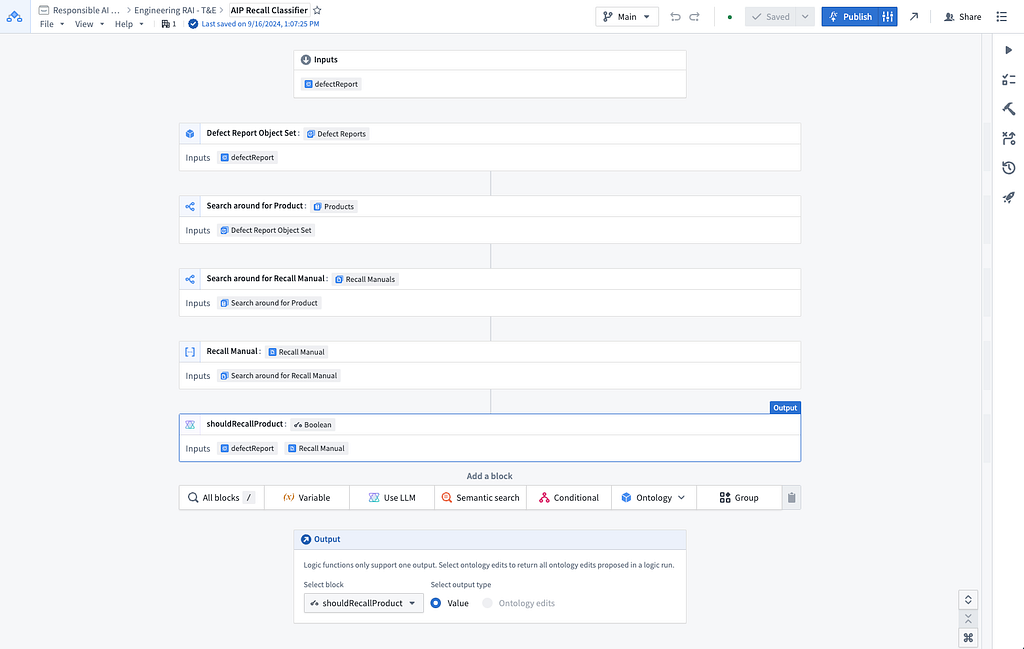
We can automate this recall process through an Ontology Augmented Generation workflow, built in AIP Logic. First, based on the defect report, we identify the relevant product and its corresponding recall manual. Next, we use an LLM to compare the defect report with the recall manual to determine if the defect meets the criteria for triggering a product-wide recall. The final output of the AIP Logic function is a true/false determination of whether a recall should be issued. This result can then be reviewed by a domain expert.
Within AIP Logic, we can run this automated recall recommendation system on various example objects to evaluate its effectiveness. For example, let’s test our function on a specific defect report in which a customer noted that the battery of their pulse oximeter drains too quickly.

As we described in our previous blog post, the Debugger in AIP Logic offers transparency into the execution of the LLM-backed function. In this specific case, the Logic Function processes the defect report about the battery, retrieves the linked pulse oximeter report from our Ontology, and finds the associated recall manual for pulse oximeters. It then passes the recall manual and defect report to the LLM for assessment.
The first question in the pulse oximeter recall manual is: “Is there a reported issue with oxygen saturation (SpO2) accuracy?” A recall would only be considered if this condition is met. Since the defect report does not mention any issues with oxygen saturation accuracy, the LLM correctly outputs false, indicating that a recall is not necessary for our pulse oximeters.
While this is promising, this is just one test case. We need a more comprehensive T&E strategy beyond spot-checking individual cases to ensure our solution will work reliably in production with a variety of inputs. To achieve this, we can use AIP Evals, which is conveniently accessible from the right-hand toolbar of AIP Logic.
Let’s walk through the main components of setting up a T&E strategy in AIP Evals.
Building a Test Bench
To evaluate our model, we first need to create a set of test cases. In AIP Evals, we can quickly write a few specific unit tests to set expectations for how the Logic function should operate. For example, we might include a unit test for a defect report with no content or one that does not mention any products in our product lines, ensuring it returns “false.” These tests help validate edge cases that should not trigger a recall.
To use more realistic test cases, we could leverage decisions from prior recalls so that we can directly compare our new LLM-backed function against the current manual process of determining whether a defect report should lead to a product recall. AIP Evals facilitates this with Object Set-backed Test Cases. Each Defect Report object in the Titan Industries Ontology has a “Should Recall” property, which is set at the end of the defect report review workflow to indicate whether the respective product needs to be recalled. In the current manual workflow, this property is set by an expert reviewing the defect report and following the recall manual. In the new workflow we’re building, this property will be set by the expert with assistance from the output of our AIP Logic function.
To assess how our AIP Logic function performs against historical defect reports, we can import a curated sample of defect deports with expert-labeled recall results to use as our test cases, as shown below:

By comparing the results from our AIP Logic function to the expert-labeled outcomes, we can gauge the accuracy and reliability of our new automated process, and make modifications to our AIP Logic function with confidence and speed.
Defining Evaluators
Once we have a set of test cases, the next step is to evaluate our AIP Logic function against these historical defect reports. Each historical Defect Report object contains a “Should Recall” field, which is set to true or false based on the decision of the product quality team regarding whether that defect warrants a recall.
When evaluating our AIP Logic function, the Defect Report object backing each test case will be used as input. The AIP Logic Function will output true or false, as previously defined. To determine if the output is correct, we compare it with the “Should Recall” property of the Defect Report object.
AIP Evals provides built-in logic for such comparisons, which we term “Evaluators.” While LLM workflows can produce a variety of possible outputs requiring context-specific evaluations, common patterns across workflows can often be tested using consistent methodologies. AIP Evals accelerates the creation of tailored evaluations for LLM-powered workflows by offering no-code evaluators for common comparisons, metrics, and scoring functions. In this scenario, we can select the “Exact Boolean Match” Evaluator to compare the output of the AIP Logic function with the ground truth from the “Should Recall” property of the Defect Report object.

In addition to its default evaluators, AIP Evals allows users to write custom evaluators. These can be no-code, Python, or TypeScript functions and can even employ another LLM to grade the output of the function under test. The capability to create custom evaluators offers a powerful means to establish a robust, context-specific evaluation strategy. For example, if the Logic function’s output included an “explanation” field, we could write an evaluator to test whether the explanation references the correct recall manual. Throughout this blog series, we will delve deeper into custom evaluators for fairness, bias, safety, and other facets of Responsible AI.
Understanding Evaluation Results
Once we’ve set up our test cases and Evaluator, we can proceed with running our evaluations. AIP Evals will run our function against each test case, compute metrics based on the function’s output and the chosen Evaluator, and display the results in an evaluation dashboard. This dashboard allows us to view both aggregate T&E results as well as the outcomes for individual cases. By analyzing these results, we can identify potential modifications to our AIP Logic function to improve its evaluation performance.

Using T&E Results to Improve your AI System
Testing your AI with AIP Evals provides insights into its effectiveness and trustworthiness in an operational setting. This is particularly important with Generative AI, where examining specific test case failures can guide targeted improvements to the prompt, parameters, or tools in AIP Logic. By comparing evaluation results across different versions of your AIP Logic function, you can iteratively improve performance and ensure that your changes do not cause unintended regressions in previously passing test cases. Let’s walk through an example of this iterative testing and refinement process using our product recall example.
We’ll begin with an examination of our current function’s performance on our evaluation suite. In AIP Evals, you can configure how many times to run each evaluator — in this case, we run each test case three times to account for the non-determinism in the LLM call in our AIP Logic function.
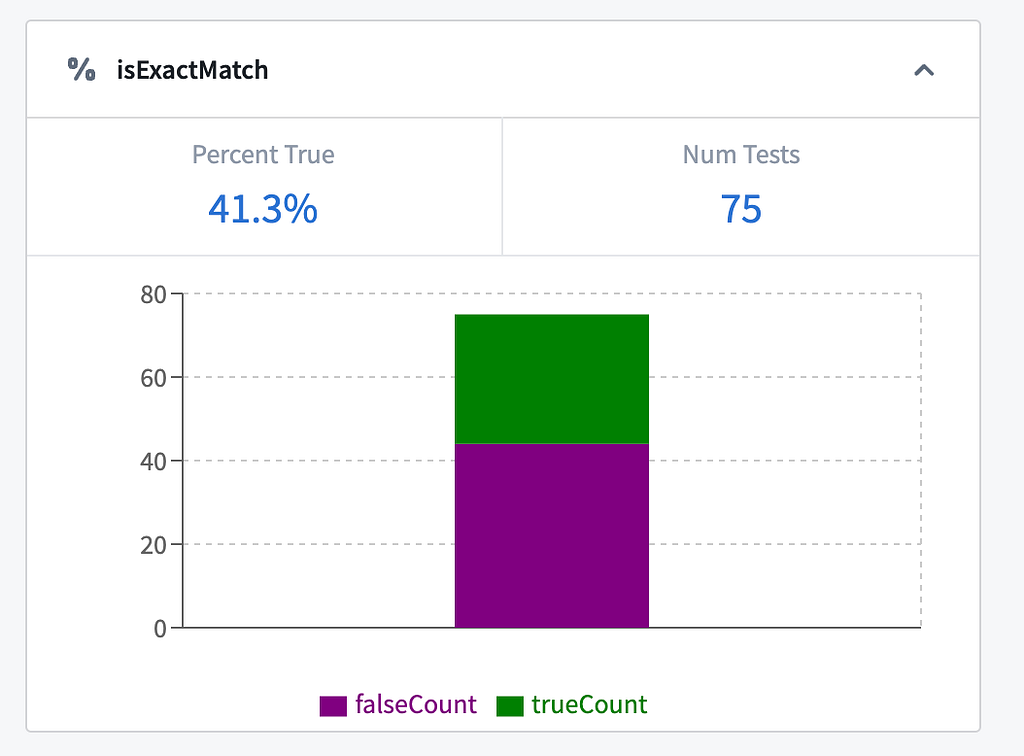
With an accuracy of 41.3% on the ground truth data, this AIP Logic function is clearly not production-ready. To identify areas for improvement, we can toggle over to the tests tab to review the failures.

We can select a test case to drill down into the inputs, intermediate outputs, and final response returned by the function. It appears that the LLM consistently fails to return the correct response because the manual directs the reader to consult an expert review outcome before proceeding with a recall, but the LLM is not provided with information about the expert review in the prompt.

Reviewing the recall manual retrieved for this product, we see that the final decision on a recall is always made via an expert review of the product, the defect report, and the recall manual instructions.

This makes sense; a human should be in the loop for these decisions, and the primary purpose of this Logic function is to determine whether an expert should review the defect report. The test case highlights a flaw in our prompt that wasn’t obvious during the initial prototype development and testing with a few example inputs. Currently, the prompt is a brief sentence asking the LLM to decide whether the product should be recalled:

To improve the prompt, we should add context indicating that we are seeking an output that determines whether all recall criteria are met and if the issue should be elevated to the expert review step. We can then verify its efficacy using our evaluation suite, allowing us to make this change with confidence.

After rerunning our evaluation suite against our test bench of historical product recalls, we can see a significant increase in accuracy, rising from 41.3% to 93.3% — more than doubling our previous performance!
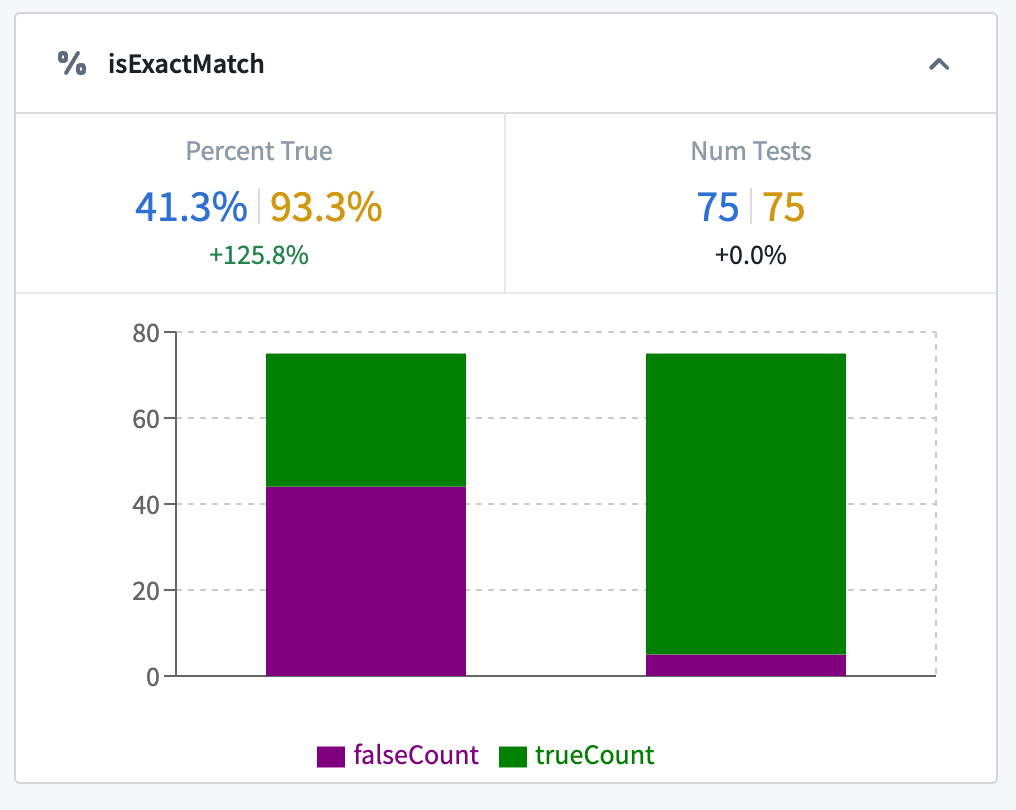
This significant performance jump is extremely exciting and validates that our prompt engineering efforts have enhanced the effectiveness of our AIP Logic function. By debugging specific test failures, we were able to identify a common cause of errors, implement a targeted fix, and assess the impact of our changes. However, since we haven’t yet achieved full accuracy on our curated test bench of historical examples, let’s dig into another type of failing test case to understand how we can further improve our function.
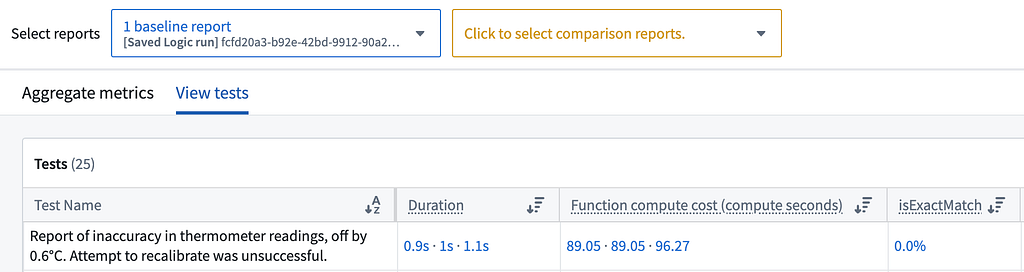
When examining the particular LLM run for that test case in AIP Evals, we can see that the recall manual includes a specific formula for determining whether an inaccuracy is severe enough to warrant a recall:
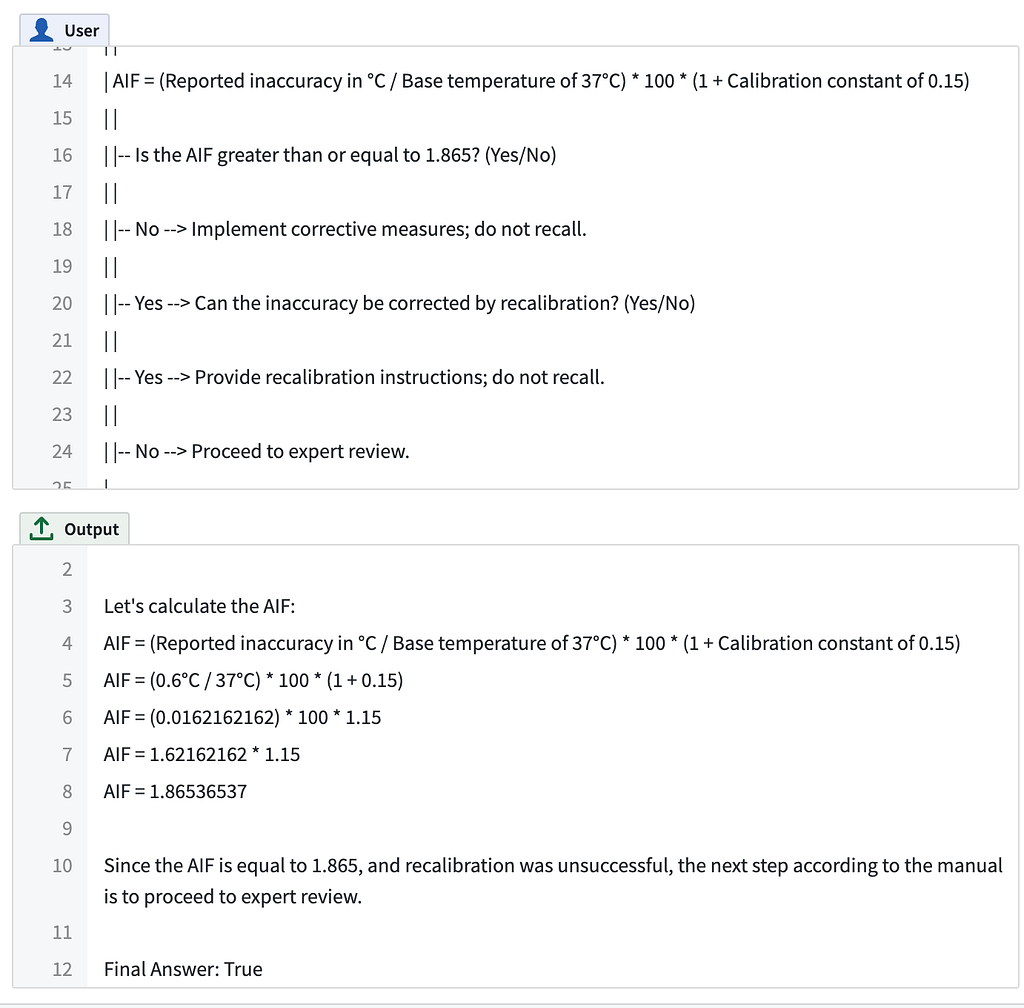
As we can see, the LLM uses this formula and arrives at a value greater than 1.865, leading it down the decision tree path that results in a recall, which is incorrect given the historical decision. After manually checking the LLM’s work, we calculate a value of 1.864, which is below the threshold for a recall — the correct answer.
While LLMs are powerful tools for text processing, they simply are not designed to handle complex math. However, we can still leverage their language processing strengths by allowing them to hand off complex calculations to a more appropriate tool. Let’s add the Calculator tool to our AIP Logic function and assess its impact on this test case’s performance.

After integrating the Calculator tool and rerunning our evaluation suite, we revisit the problematic test case and see that it is now passing!

AIP Evals enables you to iteratively and empirically improve your AI systems through “unit testing” style T&E, so that you can make changes with confidence. In our example, we could further improve our AI system by experimenting with new techniques — such as switching the base LLM, incorporating additional data from the Ontology, or implementing semantic search over historical defect report decisions — and then evaluating the impact using our established test cases. We could also expand our test bench by adding new cases, especially as new data is written back into the Ontology. With AIP Evals, the impact of any changes made to your AI system is measurable, allowing us to empirically validate improvements and confidently deploy to production.
Conclusion
AI has the potential to help organizations address some of their most pressing challenges. But building these AI solutions only matters if they can transition from experiments and R&D projects to actual production deployment. Testing and evaluation (T&E) is a crucial part of this story, and we’ve seen firsthand how the T&E capabilities in AIP have enabled our customers to scale their prototypes to production. By empirically evaluating AI systems, organizations can better understand how these systems will perform in real-world scenarios. Once deployed, continuous testing allows organizations to implement changes with confidence and speed. T&E establishes the foundation of trust necessary for deploying AI solutions at scale.
Stay tuned for future posts on T&E and other capabilities for Responsible AI in AIP. We will continue to explore how to build and deploy AI systems that enable you to effectively and responsibly solve the challenges that matter most to your organization.
Authors
Arnav Jagasia, Head of Software Engineering for Privacy & Responsible AI
Colton Rusch, Privacy & Civil Liberties Engineer
![]()
From Prototype to Production was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.