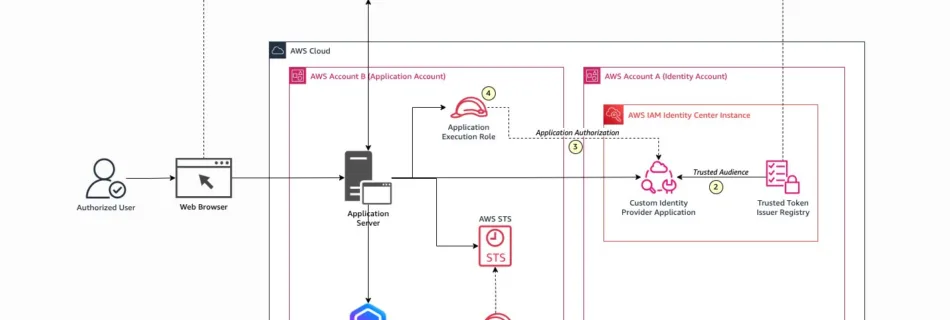
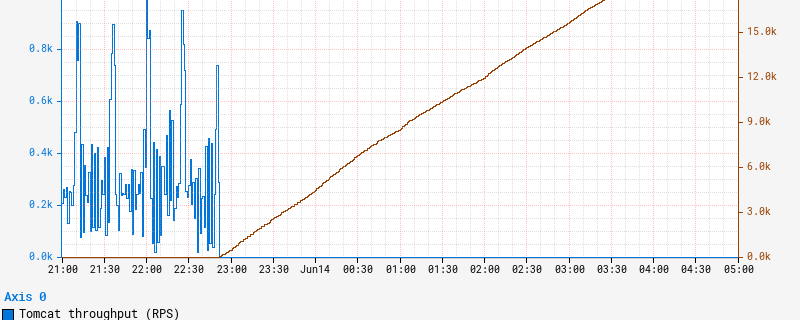
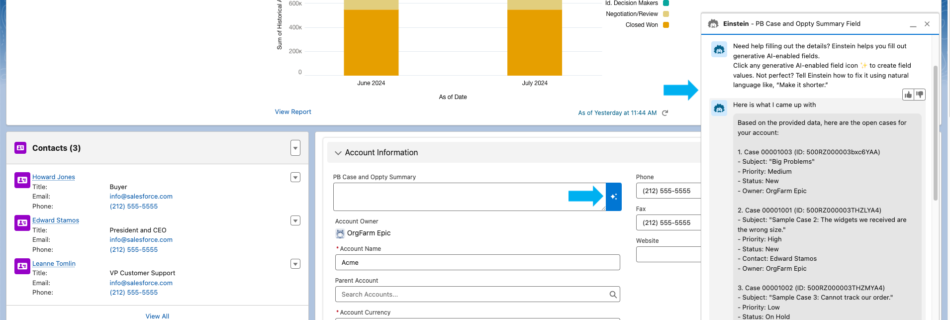
Unlocking Japanese LLMs with AWS Trainium: Innovators Showcase from the AWS LLM Development Support Program
Amazon Web Services (AWS) is committed to supporting the development of cutting-edge generative artificial intelligence (AI) technologies by companies and organizations across the globe. As part of this commitment, AWS Japan announced the AWS LLM Development Support Program (LLM Program), through which we’ve had the privilege of working alongside some of Japan’s most innovative teams. …