Google DeepMind’s latest research at ICML 2023
Google DeepMind researchers are presenting more than 80 new papers at the 40th International Conference on Machine Learning (ICML 2023), taking place 23-29 July in Honolulu, Hawai’i.
Google DeepMind researchers are presenting more than 80 new papers at the 40th International Conference on Machine Learning (ICML 2023), taking place 23-29 July in Honolulu, Hawai’i.
We’re rolling out custom instructions to give you more control over how ChatGPT responds. Set your preferences, and ChatGPT will keep them in mind for all future conversations.
When businesses need industry-leading performance scalability and reliability for their SAP ERP landscape, they turn to IBM® Power® for their compute infrastructure. I can pull a list of benchmarks that highlight why over 4,500 customers run SAP HANA on Power—highest SAP-certified memory scalability, leadership in SAPS performance benchmarks, ranked most reliable among SAP-certified infrastructure platforms, …
Posted by Donald Martin, Jr., Technical Program Manager, Head of Societal Context Understanding Tools and Solutions (SCOUTS), Google Research AI-related products and technologies are constructed and deployed in a societal context: that is, a dynamic and complex collection of social, cultural, historical, political and economic circumstances. Because societal contexts by nature are dynamic, complex, non-linear, …
Read more “Using societal context knowledge to foster the responsible application of AI”
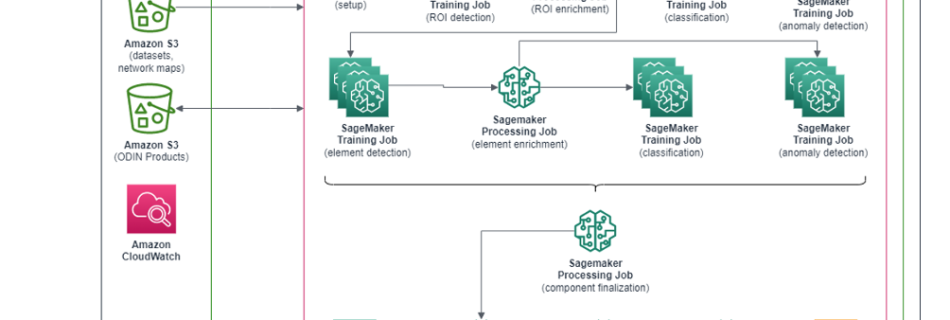
This is a guest post by Mario Namtao Shianti Larcher, Head of Computer Vision at Enel. Enel, which started as Italy’s national entity for electricity, is today a multinational company present in 32 countries and the first private network operator in the world with 74 million users. It is also recognized as the first renewables …
This blog post is part of the “All You Need to Know About Red Teaming” series by the IBM Security Randori team. The Randori platform combines attack surface management (ASM) and continuous automated red teaming (CART) to improve your security posture. “No battle plan survives contact with the enemy,” wrote military theorist, Helmuth von Moltke, …
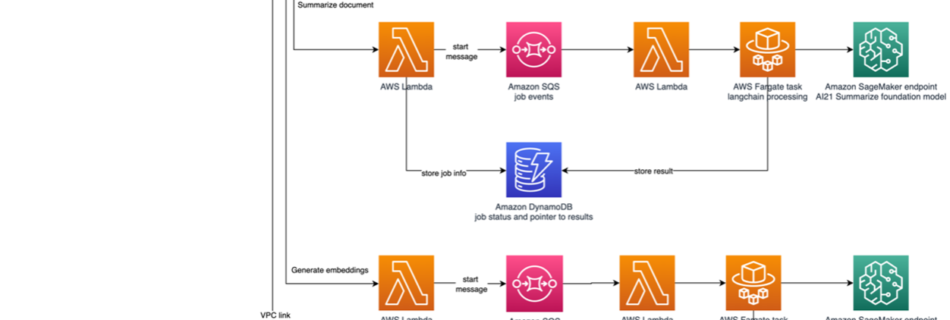
Large language models (LLMs) can be used to analyze complex documents and provide summaries and answers to questions. The post Domain-adaptation Fine-tuning of Foundation Models in Amazon SageMaker JumpStart on Financial data describes how to fine-tune an LLM using your own dataset. Once you have a solid LLM, you’ll want to expose that LLM to …
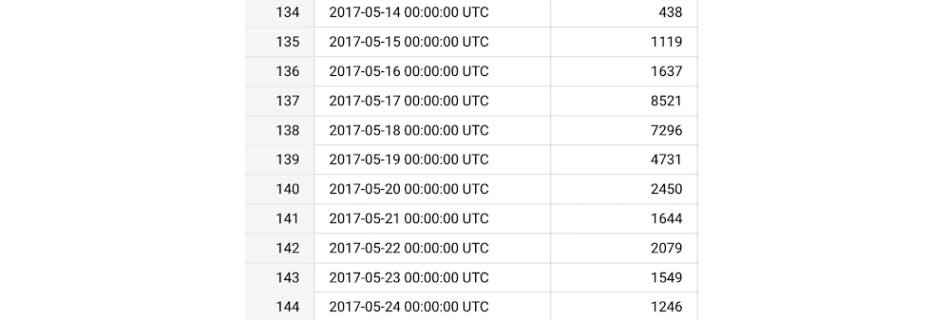
Time-series forecasting is one of the most important models across a variety of industries, such as retail, telecom, entertainment, manufacturing. It serves many use cases such as forecasting revenues, predicting inventory levels and many others. It’s no surprise that time series is one of the most popular models in BigQuery ML. Defining holidays is important …
Read more “How to use custom holidays for time-series forecasting in BigQuery ML”
A new $5+ million partnership aims to explore ways the development of artificial intelligence (AI) can support a thriving, innovative local news field, and ensure local news organizations shape the future of this emerging technology.