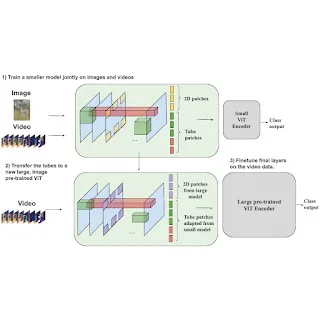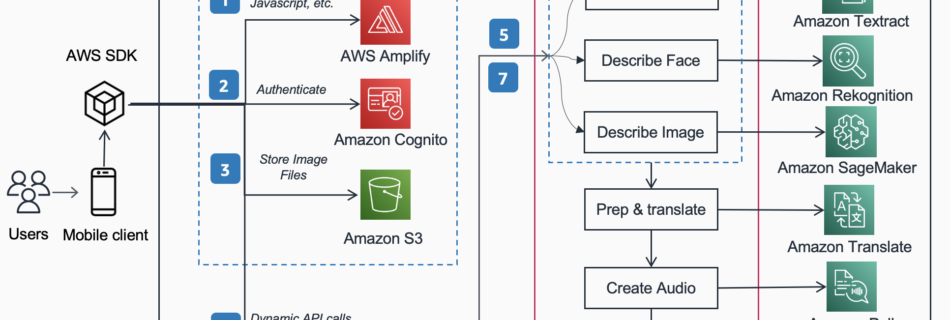
Introducing an image-to-speech Generative AI application using Amazon SageMaker and Hugging Face
Vision loss comes in various forms. For some, it’s from birth, for others, it’s a slow descent over time which comes with many expiration dates: The day you can’t see pictures, recognize yourself, or loved ones faces or even read your mail. In our previous blogpost Enable the Visually Impaired to Hear Documents using Amazon …