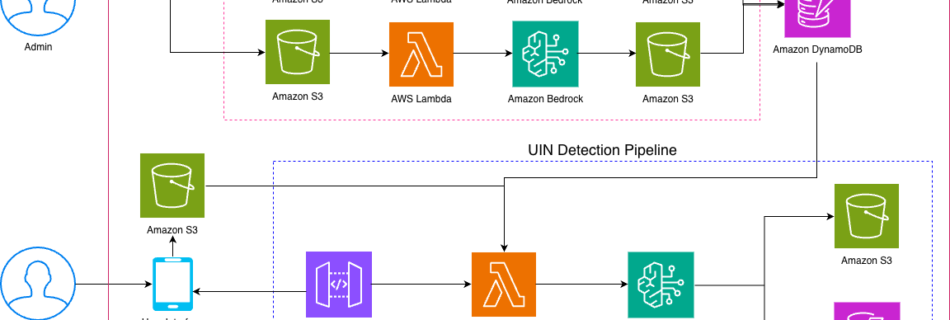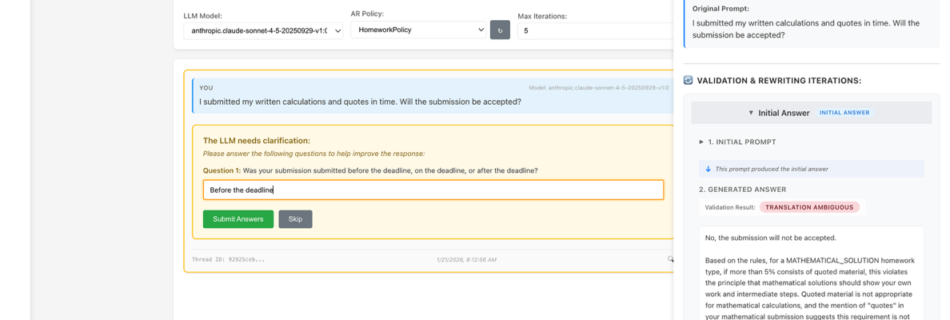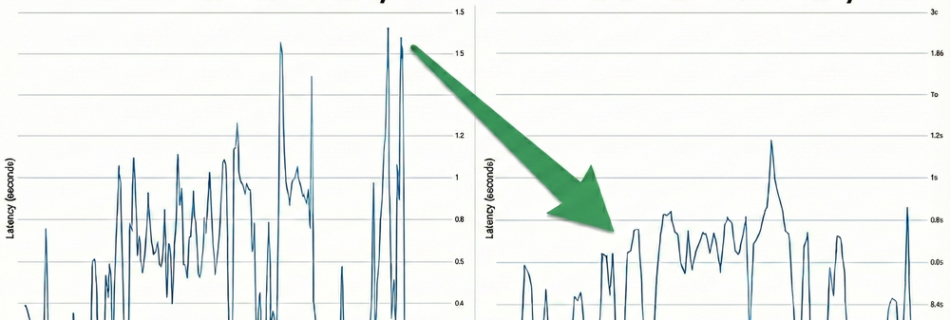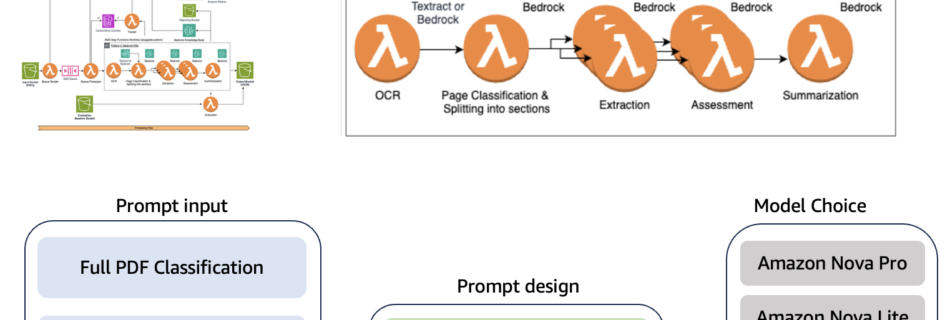
NVIDIA Nemotron 3 Nano 30B MoE model is now available in Amazon SageMaker JumpStart
Today we’re excited to announce that the NVIDIA Nemotron 3 Nano 30B model with 3B active parameters is now generally available in the Amazon SageMaker JumpStart model catalog. You can accelerate innovation and deliver tangible business value with Nemotron 3 Nano on Amazon Web Services (AWS) without having to manage model deployment complexities. You can …
Read more “NVIDIA Nemotron 3 Nano 30B MoE model is now available in Amazon SageMaker JumpStart”