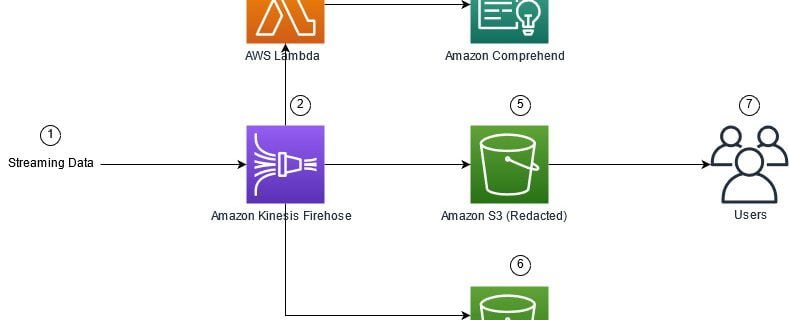
AI Esperanto: Large Language Models Read Data With NVIDIA Triton
Julien Salinas wears many hats. He’s an entrepreneur, software developer and, until lately, a volunteer fireman in his mountain village an hour’s drive from Grenoble, a tech hub in southeast France. He’s nurturing a two-year old startup, NLP Cloud, that’s already profitable, employs about a dozen people and serves customers around the globe. It’s one …
Read more “AI Esperanto: Large Language Models Read Data With NVIDIA Triton”