Behind the Scenes: Building a Robust Ads Event Processing Pipeline
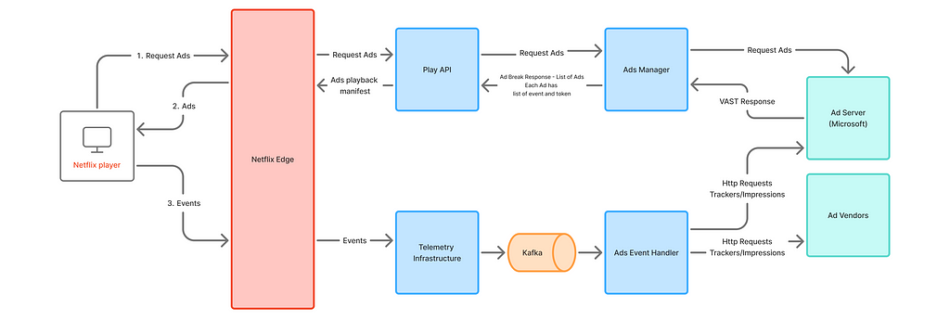
Kinesh Satiya Introduction In a digital advertising platform, a robust feedback system is essential for the lifecycle and success of an ad campaign. This system comprises of diverse sub-systems designed to monitor, measure, and optimize ad campaigns. At Netflix, we embarked on a journey to build a robust event processing platform that not only meets …
Read more “Behind the Scenes: Building a Robust Ads Event Processing Pipeline”