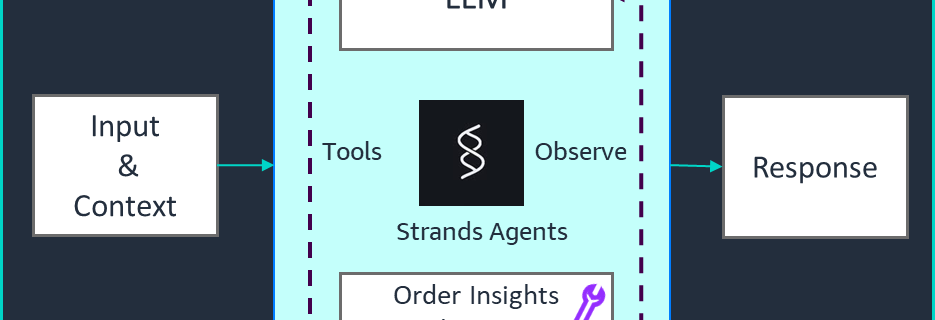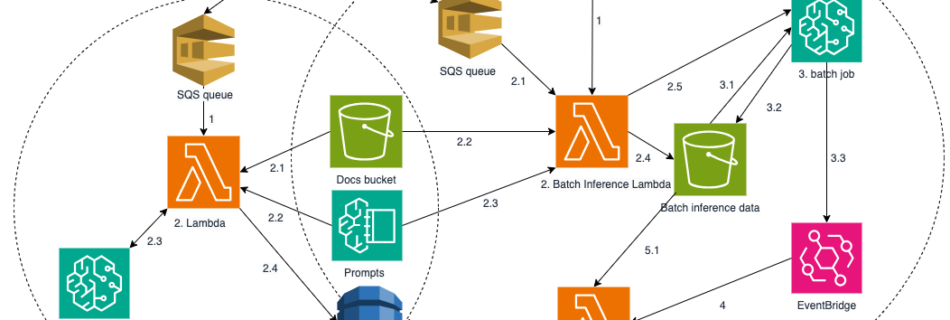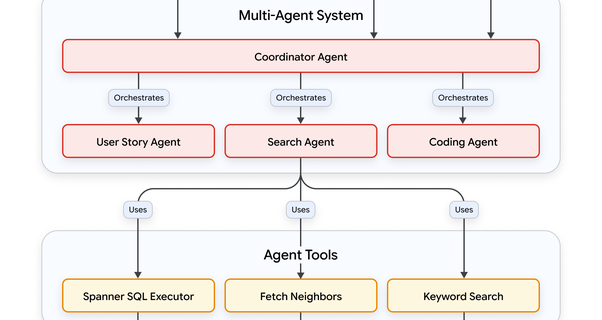
How Siemens “slices the elephant,” advancing agentic workflows for industrial software development
For technology companies like Siemens, software is the nervous system of factories, energy grids, and transportation networks worldwide. As a global leader in industrial AI, industrial software, and industrial automation, Siemens brings decades of domain expertise across factory and process automation, energy infrastructure, and intelligent transportation — expertise that no off-the-shelf AI solution can replicate. …