
Turning Conversation Into Action (Palantir CSE #2)
Anchoring AI Agents Into the Enterprise

Editor’s Note: This is the second in a three-part blog series about Palantir’s AI-enabled Customer Service Engine.
Part 2: Implementation
In Part 1 of this three-part blog series, we explored the agentic architecture of the Customer Service Engine (CSE) through the lens of a customer deployment. In this part of our deep-dive series, we will examine how AI agents can be provided with an operational context within an enterprise. Palantir AIP is used to set up guard-railed access to data, custom-built tools, actions, and human feedback capture. These pillars enable the agents to drive end-to-end autonomous processes for customer experience. Lets dive into these.

Data Landscape
The agents operate in a data-rich environment of connected objects backed by source systems like SAP, Salesforce, other ERP systems, and data warehouses. These objects represent concepts such as Customers, Orders, Products, Queries, and more, all hydrated through data pipelines built in Palantir Foundry.

Agent Isolation and Independence
Each agent is built for a specific purpose and is configured to access specific views of the connected Ontology. During runtime, agents navigate different paths through the object landscape to read information. For example:
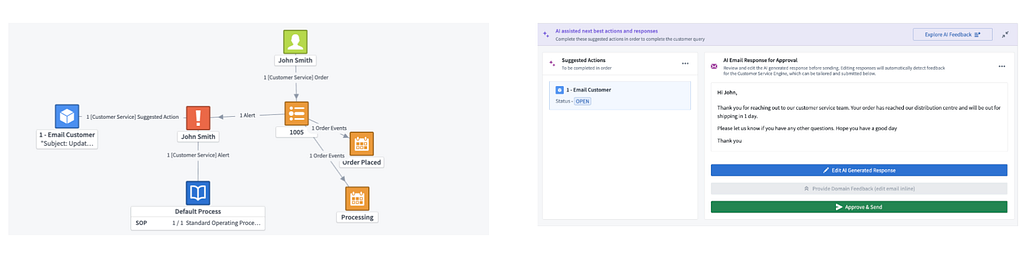
Deliver ETA Inquiry
Query: “When can I expect a delivery for my Order 1005? I want to make sure that I am at my house to receive the delivery.”
Data Points: Order status, customer details, shipping information, ETA model parameters.
Process: The classification agent identifies this query is meant for the order ETA Agent. The agent retrieves the PO number and determines the Order number (sourced from SAP). The order is linked to the customer. The agent invokes a machine learning ETA model with appropriate parameters at runtime, reviews the results, and hands them back to the master agent to create suggested actions. The communication agent drafts a written (email) response based on the suggested actions.
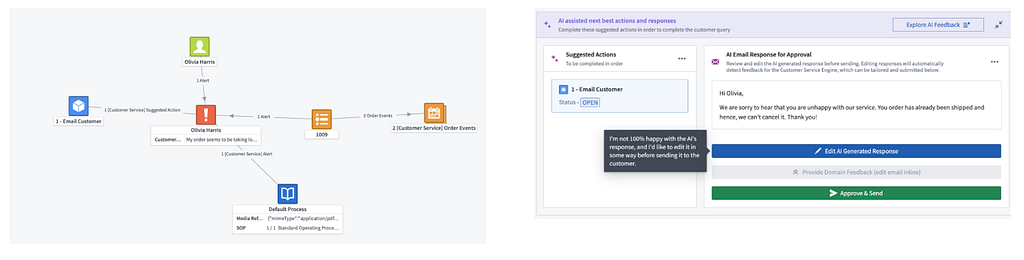
Order Cancellation Request
Query: “My order seems to be taking longer than expected. Can you please cancel it? PO 21100367.”
Data Points: Order status, customer details, cancellation SOP, product information.
Process: The query is classified and handed off to the order management agent. The agent accesses the order cancellation SOP to follow the cancellation process. By performing a similarity search on the text embedding of the SOP, the agent retrieves the relevant context. It reads the auto-resolved and linked order to the customer’s query from the Ontology. Returns the relevant response and actions to the communication agent to respond. In this case, no other action is required.
Actions
Our agents need to be able to drive operational changes within the enterprise. The ‘Actions’ Ontology primitive allows us to create custom behaviors and actions that our agents can execute with proper permissions. Palantir AIP allows Actions to drive in-platform changes like object edits, external changes such as calling APIs, and free-form code execution using Function on Objects.
We worked with the customer to understand their customer service resolution processes and built a portfolio of actions aligned with these processes. For example, an action to ‘modify delivery date’ would update the related Order object in the Ontology, the corresponding ERP record with the new requested delivery date, and notify the final-mile delivery partner to update their delivery schedules.
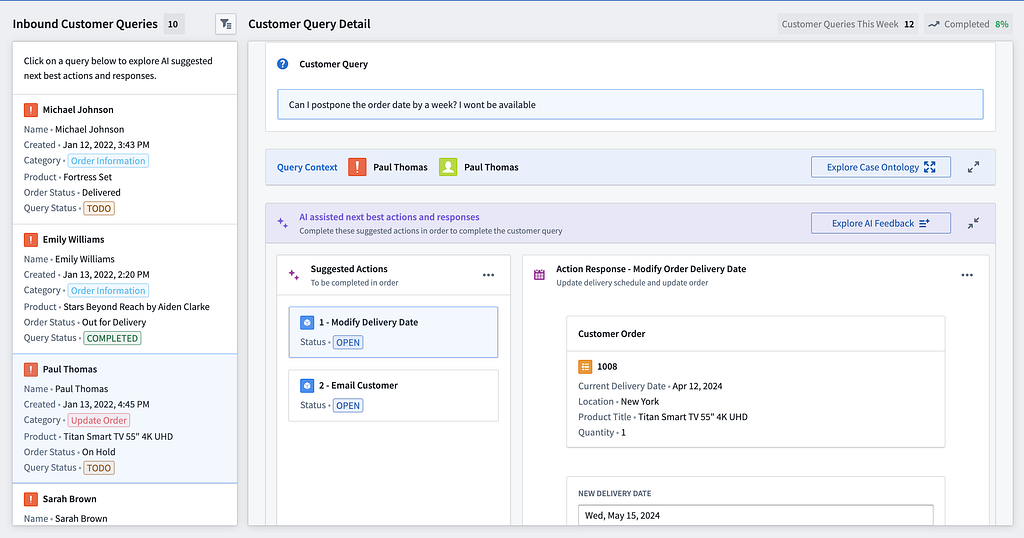
In some cases, a human operator is needed to take these actions and provide valuable feedback when the agent suggests an incorrect action. We built a customer service cockpit for these operators to interact with the agent outputs when the system is ‘unsure’ and requires human inputs.
Actions Suggestion Agent
To help agents choose the correct actions from the action registry in the context of a customer query, we used the customer organization’s standard operating procedures (SOPs). We semantically mapped and stored these SOPs in the Ontology for agents to retrieve and use effectively. Capturing SOP items in the Ontology not only enables semantic search but also key metadata like descriptions and usage scenarios, facilitating fast and accurate discovery, interpretation, and validation of relevant SOP items.
This enabled us to build another agent, the ‘Suggested Actions Agent’, to parse through the SOPs and dynamically generate the sequence of Actions required to resolve the customer query.
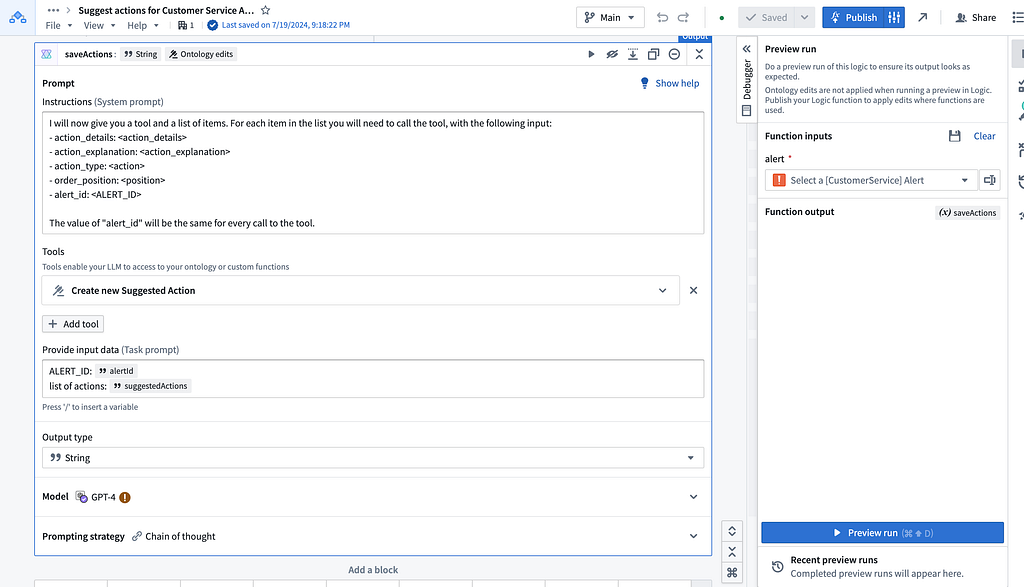
This serves as a sidekick for the Response Agent, guiding them through a structured process. Below is the core prompt for the Actions Suggestion Agent:

This prompt instructs the classification agent to invoke the correct agent and also specifies the output format, enabling deterministic API contracts downstream.
Each agent retrieves the SOPs and list of available actions using the Ontology APIs in a Function of Objects (FoO function), written in TypeScript below:

Each agent calls these functions to get the enabled actions and the SOPs, then returns the relevant actions to the master agent along with some text to indicate the response to send. The actions generated are saved in the master agent and link to the alerts.
Further Optimization: K-LLMs
For tasks requiring high precision, we provide agents with access to multiple LLMs instead of one, selecting the best response based on a consensus function. The benefits of this approach include:
- Accuracy: Decision-making is not governed by any one model or provider, mitigating potential bias.
- Confidence: When multiple models agree on a detected inconsistency, that can increase confidence in it being a true inconsistency, ahead of prioritizing it for action.
- No Model Lock-In: Leveraging the best models at any time, live or at scale in pipelines.
- No Friction: Model deployment is managed in-platform, allowing rapid addition of models and more flexibility in experimentation.
- Reduced Hallucinations: Having many LLMs work together reduces the probability of hallucinations trickling into responses drastically.
For example, in an ‘email generation’ task, which is critical to get right as it involves communication with the end-customer, we let the agent run with three different LLMs, selecting the most organic sounding output.

Human Validation and Feedback
An important factor in improving the overall system’s output quality is human feedback, so that the system can learn from subject matter experts. Difficult customer support requests are channeled to an operator UI, where SMEs can edit and approve the agent-suggested actions, generating rich human feedback.
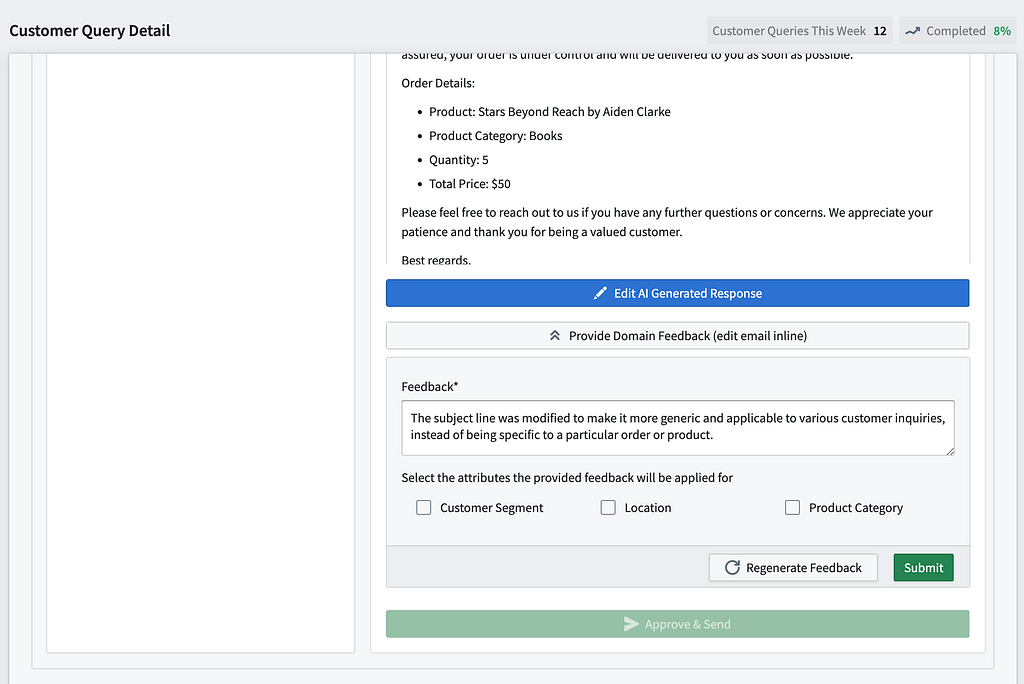
For example, in the above ‘send email’ action, editing the email inline triggers a function that captures the edit and automatically generates a feedback description based on the changes.
The ongoing collection of feedback repository is materialized as a feedback ‘object’ in the Ontology. The feedback object is not simply a binary correctness indicator; it contains all details pertaining to a prediction, including its lineage, why and how the prediction is wrong, and Customer and Product categories tied to that particular prediction. This feedback collection becomes powerful, as illustrated in the next section.


This function acts as a tool for agents during runtime and to extract relevant domain-specific feedback from the Ontology to help them solve queries.
Utilizing feedback at scale
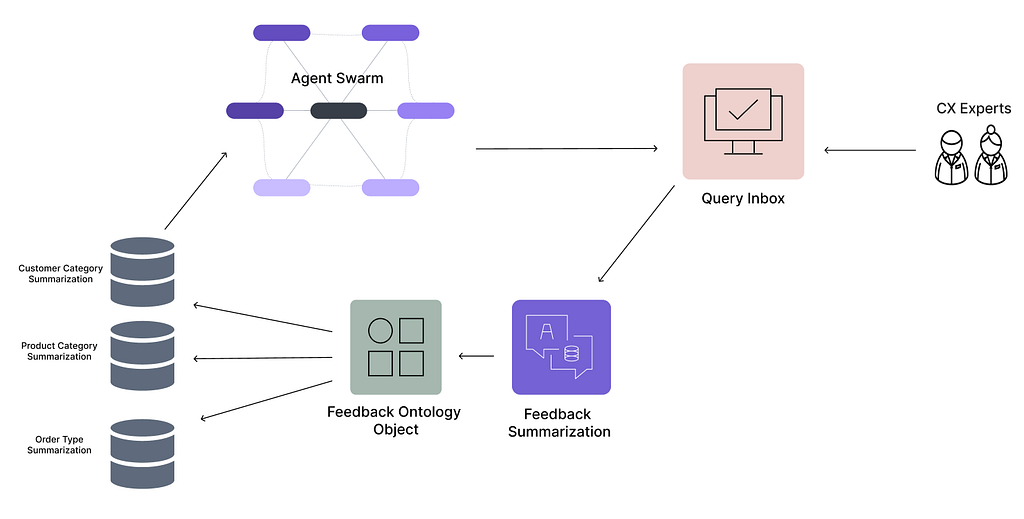
One of the key strengths of CSE is its ability to learn from its mistakes. The compounding nature of the Ontology and feedback means the system will improve and become more tailored to an organization without dedicated training. Incorrect flags and anomalies are not just corrected; they are captured and integrated back into the customers and products Ontology. To utilize feedback effectively at scale, we take the following approach:
- Custom prompts are automatically generated using prompt injection of feedback summaries for specific domains (product/customer segment/vendor).
- Feedback summaries are generated by using an LLM to summarize all feedback specific to a domain.
- These feedback summaries are updated and compounded weekly, with a bias to index on more recent inputs, as more feedback is generated by operators using the system. All feedback is editable and can be removed / changed.
- Prompt-engineering effectivity fails at scale, as no single prompt can solve every possible scenario across millions of inputs. However, giving agents access to contextually relevant and summarized feedback allows them to self-correct, solving this problem.
Next up: Running CSE in Prod
In this second part of our series, we explored how AI agents access organizational knowledge and processes. But this is not sufficient to operate our system in a production setting. Like any well-engineered system, the CSE needs production monitoring, strict evaluation criteria, AI model monitoring, and continuous improvement loops. In the next and final post of this series, we will discuss the considerations of deploying the CSE in production.
If you’re interested in transforming your customer experience ecosystem, reach out to us at customer-service-engine@palantir.com.
![]()
Turning Conversation Into Action was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.