
Today, we are thrilled to announce many improvements for forecasters on Vertex AI. We are launching TimeSeries Dense Encoder (TiDE), a new forecasting model architecture with massive performance improvements. The new model architecture is one of the many improvements enabled by a new forecasting backend that leverages Vertex AI Pipelines and provides more transparency, more customizations, and fast training times on large datasets. The forecasting models now also use improved probabilistic inference. Like TiDE, this method was originally developed by a Google’s research team to improve performance for sparse data forecasting, a very challenging forecasting task, especially in retail demand forecasting.
The new model is available in public preview and you can use the new forecasting workflow today via the Vertex AI Pipelines Template Gallery.
Over the past decade, deep learning models have outperformed other methods in many forecasting tasks and have gained strong momentum in the industry. Google has been a major research contributor to the application of deep learning architectures in time series forecasting. Backed by this research, Vertex AI offers an easy to use end to end service for forecasting with deep learning models. Today, Vertex AI powers forecasting needs for many Google Cloud customers across a wide range of industries like fashion retail, grocery, consumer packaged goods, energy, finance, and electronics.
Despite the many advantages, deep learning architectures in forecasting have downsides. One of the common friction points is that these models require long and expensive training cycles, which can often run for many hours.
This is why we are excited to announce the availability of TiDE in Vertex AI. Powered by the latest advancements from Google research teams, this architecture provides 10x training throughput improvement without compromising on model accuracy.
TimeSeries Dense Encoder (TiDE) – a new model for faster training and predictions
A fully managed training pipeline with TiDE model training and feature engineering is now available in public preview.
Compared to state of art transformer model architectures, TiDE uses a simpler multi-layer perceptron architecture, which significantly improves training and prediction throughput. Yet, the new model still shows the same accuracy as transformer models for most forecasting tasks. In fact, in many long-horizon forecasting tasks, TiDE routinely outperforms any other models. In essence, TiDE lets Google Cloud customers save time and money creating forecasts while still benefiting from the state-of-the-art accuracy that Vertex AI models are known to provide.

TiDE model architecture for multi-step forecasting. More details in: Recent advances in deep long-horizon forecasting
Compared to the Vertex AI flagship deep learning forecasting model (Learn2Learn), the TiDE architecture provides a 10x training throughput improvement (and in some cases up to 25x). The prediction throughput is also improved substantially, ranging from 3x to 10x in common tasks. This upgrade allows completion of most training jobs in just a few hours. Because of this reduced training time, in many cases migrating to TiDE can lead to significant cost savings.
TiDE is already helping Hitachi Energy advance the world’s energy systems to be more sustainable, flexible and secure. According to Bret Toplyn, Director of Product Management at Hitachi Energy: “TiDE presented exciting results for Hitachi Energy’s research in energy predictions using machine learning. What five teams took weeks to deliver, TiDE generated in mere hours with the same or better accuracy. The algorithm delivers compelling innovations in data science. Hitachi Energy plans to leverage TiDE to continuously improve its algorithms to produce better prediction results faster.”
Another review, TiDE: Revolutionizing Long-Term Time Series Forecasting by Philippe Dagher, summarized these research advances: “TiDE’s breakthrough is not just in its performance metrics, though they are undeniably impressive. It is in the underlying philosophy that simpler models, when designed with care and understanding, can not only compete with but even surpass their more complex counterparts.”
New backend for improved efficiency, transparency, and performance
TiDE is only one of the dozen improvements enabled by a new service backend, which now uses Vertex AI Pipelines to offer improvements like more transparency, built-in scheduling, support for larger datasets, customizable hardware, optional architecture search, and much more.
These improvements have already helped some of the top retail brands all around the world. Shriman Tiwari, Chief Data Scientist at Groupe Casino said, “Groupe Casino found a perfect partner in Vertex AI for demand forecasting across its expanding portfolio of over 450 hyper market stores. We were able to develop highly accurate, location and product specific forecasting models and saw a 30% improvement in forecast accuracy, and 4x reduction in model training and experimentation time.”
Tiwari also highlighted how better forecasts directly impacted Groupe Casino’s business and customers, noting, “Forecasting with Vertex AI helped in optimizing the inventory planning and reducing perishable goods wastage to increase revenue. For Casino’s clients, an improved forecasting led to a visible reduction of missing products leading to an increase in customer shopping experience.”
Built on Vertex AI Pipelines for more transparency and customization
Vertex AI forecasting models are now offered as transparent pipeline templates in Vertex AI Pipelines, with the following features now automatically available to every forecasting user.

A sample DAG of a training pipeline for the TiDE forecasting model
- Transparent Execution and Visualization: Each forecasting training workflow now has a direct acyclic graph (DAG) exposing all steps performed by the service. This allows you to review and track the execution process, including details and artifacts of data pre-processing, feature engineering, architecture search, training, and ensembling in an interactive and intuitive interface.
- New Training Artifacts: Many steps of the training process now expose intermediate artifacts. It’s easy to review BigQuery tables to understand transformations performed during feature engineering, examine data splits, or check the results of each of the architecture search trials.
- Pipeline Versioning: Now you can get the latest updates from the Vertex AI Forecasting team without unexpected changes to your forecasting pipelines and easily roll back to previous pipeline versions if problems occur.
- Easy Scheduling: Automate model retraining based on a custom schedule with built-in scheduler.
- Detailed Logs: Get detailed logging and debugging information directly from the services used in the pipeline.
- Automatic Caching: Each pipeline task is cached by default, so if an issue occurs it is simple and cost effective to restart a training pipeline from the last successful step.
- Metadata Tracking: Use built-in integrations with Vertex AI ML Metadata and Experiments to automatically log each pipeline execution and register the model artifacts. Set up experiments with just a few lines of code and compare results between training runs.
For more information about these features see Vertex AI Pipelines documentation.
Support for larger datasets enables higher quality, easier to maintain models
Forecasting training datasets can now contain up to 1TB of data (~1 billion rows). This is a 10x improvement from the earlier limit of 100gb (~100m rows). Larger training datasets open up many possibilities in a lot of forecasting applications, including:
- More Granular Forecasts: Experiment with forecasting at a more granular level, for example by using daily granularity, instead of weekly.
- Fewer Models to Maintain: Consolidate multiple forecasting models into one to reduce monitoring and maintenance costs. For example, instead of maintaining an individual demand forecasting model per product category, use a single model for all products and use product category as a feature.
We are excited to offer larger datasets support at the same time we introduce the TiDE model with more efficient training. You can now use much more training data to improve your models and yet still complete the training jobs faster than before.
Bypass architecture search for more consistent models and faster training
By default the Vertex AI forecasting service performs a model architecture search on every training run to find the optimal (neural) network structure tailored for the forecasting task. From there, a model training run is performed to discover the weights for the model parameters for that architecture.
This state of art architecture search algorithm is one of the key reasons why Vertex AI forecasting models perform consistently well across multiple domains from retail, to finance, to energy forecasting.
While the architecture search improves the chances of arriving at the best performing model on every training run, it is very computationally expensive and can change how the model performs on the same or very similar training data. Architecture search can now be skipped to improve training time and ensure more consistent models:
- Faster Re-training: Bypassing architecture search saves re-training costs when only a small amount of new training data is added. For example if the original model was trained on 1000 days of historical data it is highly unlikely that a new architecture is needed to get the best performance on 1005 days of data (e.g. a few days after the initial training completed). A more cost-effective approach is to train with the same architecture, but use the new data to update the weights.
- More Consistent Models: Bypassing architecture search improves the consistency of model accuracy on retraining. For example, a new architecture often improves the model accuracy overall (i.e. for all time series in the training data), but changes the distribution of performance between the series. The accuracy on series X may decline, but because the accuracy on series Y has improved substantially more, the overall model accuracy has improved. Such shifts are often not welcome in production forecasting systems which expect consistent model accuracy on the same or similar training. If consistency is desired, skipping architecture search is advised.
Customize hardware for faster training and data processing
For many steps in the pipeline the hardware specifications can now be customized for best performance.
- Faster Training and Feature Transformations: You may find better hardware configurations for optimal trade-off between resource availability, training time and cost. For example, for larger datasets it may be beneficial to allocate more powerful machines to reduce the overall training time.
- Efficient Resource Use: Similarly, depending on your data you may find that certain less powerful machine configurations provide a comparable training time, but cost a lot less.

Customizing the hardware options in Verex AI forecasting pipeline
A new approach to probabilistic inference for better accuracy with sparse data
The probability distribution of the forecast can now be modeled to improve handling of noisy data and quantify uncertainty for business applications.
There are many use cases where accurate forecasting is very hard or impossible, for example short-cycle product demand, sparse data forecasting, burst demand forecasting, etc. In these cases, point predictions don’t provide enough information to make good business decisions, and the range of possible scenarios needs to be considered.
The benefits of probabilistic forecasting are best illustrated with this simple example. Consider a grocery store which on average sells 20 milk cartons and 20 energy drinks every day. Even though the average sales are the same, on any given day the demand for milk is consistently between 18 and 22 items, but demand for energy drinks fluctuates between 5 and 50 items. Forecasting demand for milk with a single number (point forecast) would be rather accurate, but doing the same for energy drinks would result in large errors on most days.
However, the forecaster can still make high quality decisions on energy drinks inventory levels by using probability distributions. Forecasting models in Vertex AI can show that the demand for energy drinks is 50% likely to be less than 20 items, 75% likely to be less than 25, and 95% likely to be less than 40. Now the decision can be made to allocate 25 items to the store inventory to make sure it’s well stocked for most days and another 15 items to the local distribution center. Such allocation enables risk management by balancing between the costs of understocking and overstocking products.
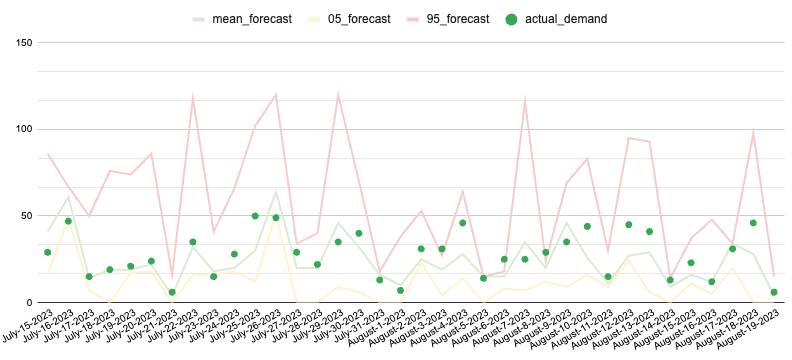
Using probabilistic outputs for the energy drinks forecast. The 05_forecast line shows the lower (5%) bound for the forecasting estimate and 95_forecast shows the higher (95%) bound. Many of the actual demand observations ended up above the mean forecast line (point forecast). Yet almost all of the points are below 95_forecast line.
Vertex AI forecasting models now support Probabilistic Inference – an improvement over the “pinball” quantile loss method used in Vertex AI forecasting models until now. Probabilistic inference is based on recent Google research and models the distribution of the prediction target explicitly, offering multiple advantages:
- Uncertainty Quantification: Includes quantiles of the predictive distribution, which describes the range of possible outcomes and expresses the confidence of the prediction. Unlike Pinball loss, quantiles are guaranteed to be ordered and accurately capture the likelihood of rare events.
- Sparsity Modeling: Explicitly models the likelihood of zero sales (ex. stockout) which often occurs in demand forecasting. This can significantly improve the accuracy of predictions for products with low volume (sparse) sales.
- Adaptive Learning: Places the greatest emphasis on learning where the model is the most confident, avoiding overfitting to noise in the data. This also places an even emphasis across scales of the target, enabling the model to make accurate predictions for both slow and fast selling items. Together, these can significantly reduce bias in forecasts.
- Automated Distribution Fit: Fits the predictive distribution using a number of candidate distributions which describe different types of processes, and weights according to the best fit for the use case, requiring no additional input from the user.
We are excited to see how improved probabilistic inference can positively impact your forecasting application. While improving forecasting accuracy may sometimes be very hard there are still tangible benefits which can be provided by using probabilistic inference.
- Improved Business Outcomes: Probabilistic outputs for forecasts help improve business decisions by allowing to quantify the tradeoffs between under forecasting and over forecasting. This is especially useful in inventory management where the costs of carrying excess inventory is often far less than the revenue loss and brand damage associated with out of stock events.
- Improved Forecast Explainability: Adding probabilistic outputs to forecast predictions can also improve explainability. The forecasts at different quantiles provide a range of possible outcomes such as the likelihood of low sales vs. high sales when product is trending. This is not something that can be derived from a single point prediction. A wide range between forecasted quantiles can show business users that the model may not have enough information for an accurate point prediction.
Getting started
We are thrilled to welcome these updates to forecasting models in Vertex AI. To learn more about using Vertex AI for forecasting, please contact your Field Sales Representative, or try it yourself by following these resources:
- Time Series Dense Encoder pipeline in Template Gallery
- Vertex AI Public Documentation for Forecasting Workflow
- Vertex AI Public Colab Notebook for Forecasting Workflow
- Recent advances in deep long-horizon forecasting – research team’s blog post with details about the TiDE Architecture.