Amazon SageMaker Serverless Inference allows you to serve model inference requests in real time without having to explicitly provision compute instances or configure scaling policies to handle traffic variations. You can let AWS handle the undifferentiated heavy lifting of managing the underlying infrastructure and save costs in the process. A Serverless Inference endpoint spins up the relevant infrastructure, including the compute, storage, and network, to stage your container and model for on-demand inference. You can simply select the amount of memory to allocate and the number of max concurrent invocations to have a production-ready endpoint to service inference requests.
With on-demand serverless endpoints, if your endpoint doesn’t receive traffic for a while and then suddenly receives new requests, it can take some time for your endpoint to spin up the compute resources to process the requests. This is called a cold start. A cold start can also occur if your concurrent requests exceed the current concurrent request usage. With provisioned concurrency on Serverless Inference, you can mitigate cold starts and get predictable performance characteristics for their workloads. You can add provisioned concurrency to your serverless endpoints, and for the predefined amount of provisioned concurrency, Amazon SageMaker will keep the endpoints warm and ready to respond to requests instantaneously. In addition, you can now use Application Auto Scaling with provisioned concurrency to address inference traffic dynamically based on target metrics or a schedule.
In this post, we discuss what provisioned concurrency and Application Auto Scaling are, how to use them, and some best practices and guidance for your inference workloads.
Provisioned concurrency with Application Auto Scaling
With provisioned concurrency on Serverless Inference endpoints, SageMaker manages the infrastructure that can serve multiple concurrent requests without incurring cold starts. SageMaker uses the value specified in your endpoint configuration file called ProvisionedConcurrency, which is used when you create or update an endpoint. The serverless endpoint enables provisioned concurrency, and you can expect that SageMaker will serve the number of requests you have set without a cold start. See the following code:
By understanding your workloads and knowing how many cold starts you want to mitigate, you can set this to a preferred value.
Serverless Inference with provisioned concurrency also supports Application Auto Scaling, which allows you to optimize costs based on your traffic profile or schedule to dynamically set the amount of provisioned concurrency. This can be set in a scaling policy, which can be applied to an endpoint.
To specify the metrics and target values for a scaling policy, you can configure a target-tracking scaling policy. Define the scaling policy as a JSON block in a text file. You can then use that text file when invoking the AWS Command Line Interface (AWS CLI) or the Application Auto Scaling API. To define a target-tracking scaling policy for a serverless endpoint, use the SageMakerVariantProvisionedConcurrencyUtilization predefined metric:
To specify a scaling policy based on a schedule (for example, every day at 12:15 PM UTC), you can modify the scaling policy as well. If the current capacity is below the value specified for MinCapacity, Application Auto Scaling scales out to the value specified by MinCapacity. The following code is an example of how to set this via the AWS CLI:
With Application Auto Scaling, you can ensure that your workloads can mitigate cold starts, meet business objectives, and optimize cost in the process.
You can monitor your endpoints and provisioned concurrency specific metrics using Amazon CloudWatch. There are four metrics to focus on that are specific to provisioned concurrency:
- ServerlessProvisionedConcurrencyExecutions – The number of concurrent runs handled by the endpoint
- ServerlessProvisionedConcurrencyUtilization – The number of concurrent runs divided by the allocated provisioned concurrency
- ServerlessProvisionedConcurrencyInvocations – The number of
InvokeEndpointrequests handled by the provisioned concurrency - ServerlessProvisionedConcurrencySpilloverInvocations – The number of InvokeEndpoint requests not handled provisioned concurrency, which is handled by on-demand Serverless Inference
By monitoring and making decisions based on these metrics, you can tune their configuration with cost and performance in mind and optimize your SageMaker Serverless Inference endpoint.
For SageMaker Serverless Inference, you can choose either a SageMaker-provided container or bring your own. SageMaker provides containers for its built-in algorithms and prebuilt Docker images for some of the most common machine learning (ML) frameworks, such as Apache MXNet, TensorFlow, PyTorch, and Chainer. For a list of available SageMaker images, see Available Deep Learning Containers Images. If you’re bringing your own container, you must modify it to work with SageMaker. For more information about bringing your own container, see Adapting Your Own Inference Container.
Notebook example
Creating a serverless endpoint with provisioned concurrency is a very similar process to creating an on-demand serverless endpoint. For this example, we use a model using the SageMaker built-in XGBoost algorithm. We work with the Boto3 Python SDK to create three SageMaker inference entities:
- SageMaker model – Create a SageMaker model that packages your model artifacts for deployment on SageMaker using the CreateModel You can also complete this step via AWS CloudFormation using the AWS::SageMaker::Model resource.
- SageMaker endpoint configuration – Create an endpoint configuration using the CreateEndpointConfig API and the new configuration ServerlessConfig options or by selecting the serverless option on the SageMaker console. You can also complete this step via AWS CloudFormation using the AWS::SageMaker::EndpointConfig You must specify the memory size, which, at a minimum, should be as big as your runtime model object, and the maximum concurrency, which represents the max concurrent invocations for a single endpoint. For our endpoint with provisioned concurrency enabled, we specify that parameter in the endpoint configuration step, taking into account that the value must be greater than 0 and less than or equal to max concurrency.
- SageMaker endpoint – Finally, using the endpoint configuration that you created in the previous step, create your endpoint using either the SageMaker console or programmatically using the CreateEndpoint You can also complete this step via AWS CloudFormation using the AWS::SageMaker::Endpoint resource.
In this post, we don’t cover the training and SageMaker model creation; you can find all these steps in the complete notebook. We focus primarily on how you can specify provisioned concurrency in the endpoint configuration and compare performance metrics for an on-demand serverless endpoint with a provisioned concurrency enabled serverless endpoint.
Configure a SageMaker endpoint
In the endpoint configuration, you can specify the serverless configuration options. For Serverless Inference, there are two inputs required, and they can be configured to meet your use case:
- MaxConcurrency – This can be set from 1–200
- Memory Size – This can be the following values: 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB, or 6144 MB
For this example, we create two endpoint configurations: one on-demand serverless endpoint and one provisioned concurrency enabled serverless endpoint. You can see an example of both configurations in the following code:
With SageMaker Serverless Inference with a provisioned concurrency endpoint, you also need to set the following, which is reflected in the preceding code:
- ProvisionedConcurrency – This value can be set from 1 to the value of your
MaxConcurrency
Create SageMaker on-demand and provisioned concurrency endpoints
We use our two different endpoint configurations to create two endpoints: an on-demand serverless endpoint with no provisioned concurrency enabled and a serverless endpoint with provisioned concurrency enabled. See the following code:
Compare invocation and performance
Next, we can invoke both endpoints with the same payload:
When timing both cells for the first request, we immediately notice a drastic improvement in end-to-end latency in the provisioned concurrency enabled serverless endpoint. To validate this, we can send five requests to each endpoint with 10-minute intervals between each request. With the 10-minute gap, we can ensure that the on-demand endpoint is cold. Therefore, we can successfully evaluate cold start performance comparison between the on-demand and provisioned concurrency serverless endpoints. See the following code:
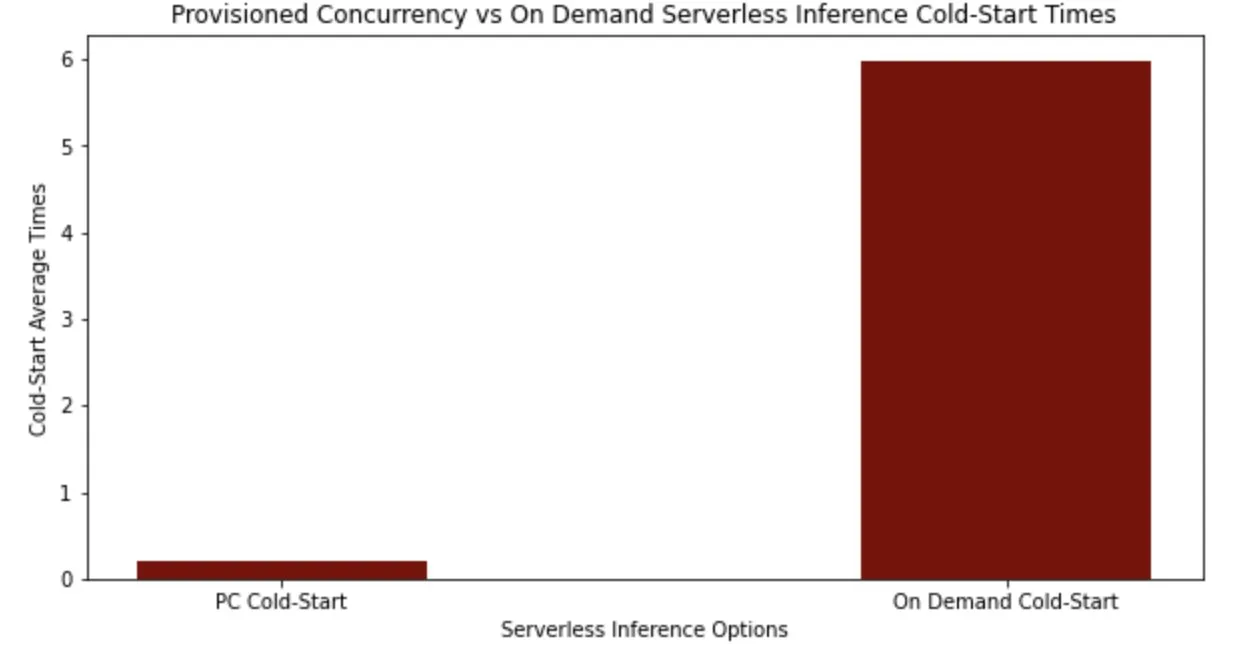
We can then plot these average end-to-end latency values across five requests and see that the average cold start for provisioned concurrency was approximately 200 milliseconds end to end as opposed to nearly 6 seconds with the on-demand serverless endpoint.

When to use Serverless Inference with provisioned concurrency
Provisioned concurrency is a cost-effective solution for low throughput and spiky workloads requiring low latency guarantees. Provisioned concurrency will be suitable for use cases when the throughput is low, and you want to reduce costs compared with instance-based while still having predictable performance or for workloads with predictable traffic bursts with low latency requirements. For example, a chatbot application run by a tax filing software company typically sees high demand during the last week of March from 10:00 AM to 5:00 PM because it’s close to the tax filing deadline. You can choose on-demand Serverless Inference for the remaining part of the year to serve requests from end-users, but for the last week of March, you can add provisioned concurrency to handle the spike in demand. As a result, you can reduce costs during idle time while still meeting your performance goals.
On the other hand, if your inference workload is steady, has high throughput (enough traffic to keep the instances saturated and busy), has a predictable traffic pattern, and requires ultra-low latency, or it includes large or complex models that require GPUs, Serverless Inference isn’t the right option for you, and you should deploy on real-time inference. Synchronous use cases with burst behavior that don’t require performance guarantees are more suitable for using on-demand Serverless Inference. The traffic patterns and the right hosting option (serverless or real-time inference) are depicted in the following figures:
- Real-time inference endpoint – Traffic is mostly steady with predictable peaks. The high throughput is enough to keep the instances behind the auto scaling group busy and saturated. This will allow you to efficiently use the existing compute and be cost-effective along with providing ultra-low latency guarantees. For the predictable peaks, you can choose to use the scheduled auto scaling policy in SageMaker for real-time inference endpoints. Read more about the best practices for selecting the right auto scaling policy at Optimize your machine learning deployments with auto scaling on Amazon SageMaker.

- On-demand Serverless Inference – This option is suitable for traffic with unpredictable peaks, but the ML application is tolerant to cold start latencies. To help determine whether a serverless endpoint is the right deployment option from a cost and performance perspective, use the SageMaker Serverless Inference benchmarking toolkit, which tests different endpoint configurations and compares the most optimal one against a comparable real-time hosting instance.

- Serverless Inference with provisioned concurrency – This option is suitable for the traffic pattern with predictable peaks but is otherwise low or intermittent. This option provides you additional low latency guarantees for ML applications that can’t tolerate cold start latencies.

Use the following factors to determine which hosting option (real time over on-demand Serverless Inference over Serverless Inference with provisioned concurrency) is right for your ML workloads:
- Throughput – This represents requests per second or any other metrics that represent the rate of incoming requests to the inference endpoint. We define the high throughput in the following diagram as any throughput that is enough to keep the instances behind the auto scaling group busy and saturated to get the most out of your compute.
- Traffic pattern – This represents the type of traffic, including traffic with predictable or unpredictable spikes. If the spikes are unpredictable but the ML application needs low-latency guarantees, Serverless Inference with provisioned concurrency might be cost-effective if it’s a low throughput application.
- Response time – If the ML application needs low-latency guarantees, use Serverless Inference with provisioned concurrency for low throughput applications with unpredictable traffic spikes. If the application can tolerate cold start latencies and has low throughput with unpredictable traffic spikes, use on-demand Serverless Inference.
- Cost – Consider the total cost of ownership, including infrastructure costs (compute, storage, networking), operational costs (operating, managing, and maintaining the infrastructure), and security and compliance costs.
The following figure illustrates this decision tree.

Best practices
With Serverless Inference with provisioned concurrency, you should still adhere to best practices for workloads that don’t use provisioned concurrency:
- Avoid installing packages and other operations during container startup and ensure containers are already in their desired state to minimize cold start time when being provisioned and invoked while staying under the 10 GB maximum supported container size. To monitor how long your cold start time is, you can use the CloudWatch metric
OverheadLatencyto monitor your serverless endpoint. This metric tracks the time it takes to launch new compute resources for your endpoint. - Set the
MemorySizeInMBvalue to be large enough to meet your needs as well as increase performance. Larger values will also devote more compute resources. At some point, a larger value will have diminishing returns. - Set the
MaxConcurrencyto accommodate the peaks of traffic while considering the resulting cost. - We recommend creating only one worker in the container and only loading one copy of the model. This is unlike real-time endpoints, where some SageMaker containers may create a worker for each vCPU to process inference requests and load the model in each worker.
- Use Application Auto Scaling to automate your provisioned concurrency setting based on target metrics or schedule. By doing so, you can have finer-grained, automated control of the amount of the provisioned concurrency used with your SageMaker serverless endpoint.
In addition, with the ability to configure ProvisionedConcurrency, you should set this value to the integer representing how many cold starts you would like to avoid when requests come in a short time frame after a period of inactivity. Using the metrics in CloudWatch can help you tune this value to be optimal based on preferences.
Pricing
As with on-demand Serverless Inference, when provisioned concurrency is enabled, you pay for the compute capacity used to process inference requests, billed by the millisecond, and the amount of data processed. You also pay for provisioned concurrency usage based on the memory configured, duration provisioned, and amount of concurrency enabled.
Pricing can be broken down into two components: provisioned concurrency charges and inference duration charges. For more details, refer to Amazon SageMaker Pricing.
Conclusion
SageMaker Serverless Inference with provisioned concurrency provides a very powerful capability for workloads when cold starts need to be mitigated and managed. With this capability, you can better balance cost and performance characteristics while providing a better experience to your end-users. We encourage you to consider whether provisioned concurrency with Application Auto Scaling is a good fit for your workloads, and we look forward to your feedback in the comments!
Stay tuned for follow-up posts where we will provide more insight into the benefits, best practices, and cost comparisons using Serverless Inference with provisioned concurrency.
About the Authors
 James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends.You can find him on LinkedIn.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
 Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
 Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Sr Ai/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on SageMaker. Prior to this role he has worked as Machine Learning Engineer building and hosting models. Outside of work he enjoys playing tennis and biking on mountain trails.
 Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
 Shruti Sharma is a Sr. Software Development Engineer in AWS SageMaker team. Her current work focuses on helping developers efficiently host machine learning models on Amazon SageMaker. In her spare time she enjoys traveling, skiing and playing chess. You can find her on LinkedIn.
Shruti Sharma is a Sr. Software Development Engineer in AWS SageMaker team. Her current work focuses on helping developers efficiently host machine learning models on Amazon SageMaker. In her spare time she enjoys traveling, skiing and playing chess. You can find her on LinkedIn.
 Hao Zhu is a Software Development with Amazon Web Services. In his spare time he loves to hit the slopes and ski. He also enjoys exploring new places, trying different foods, experiencing different cultures and is always up for a new adventure.
Hao Zhu is a Software Development with Amazon Web Services. In his spare time he loves to hit the slopes and ski. He also enjoys exploring new places, trying different foods, experiencing different cultures and is always up for a new adventure.