The AI landscape is being reshaped by the rise of generative models capable of synthesizing high-quality data, such as text, images, music, and videos. The course toward democratization of AI helped to further popularize generative AI following the open-source releases for such foundation model families as BERT, T5, GPT, CLIP and, most recently, Stable Diffusion. Hundreds of software as a service (SaaS) applications are being developed around these pre-trained models, which are either directly served to end-customers, or fine-tuned first on a per-customer basis to generate personal and unique content (such as avatars, stylized photo edits, video game assets, domain-specific text, and more). With the pace of technological innovation and proliferation of novel use cases for generative AI, upcoming AI-native SaaS providers and startups in the B2C segment need to prepare for scale from day one, and aim to shorten their time-to-market by reducing operational overhead as much as possible.
In this post, we review the technical requirements and application design considerations for fine-tuning and serving hyper-personalized AI models at scale on AWS. We propose an architecture based on the fully managed Amazon SageMaker training and serving features that enables SaaS providers to develop their applications faster, provide quality of service, and increase cost-effectiveness.
Solution scope and requirements
Let’s first define the scope for personalized generative AI SaaS applications:
- You don’t train foundation models yourself, but rather fine-tune the available pre-trained models on a per-user basis and serve these personalized models individually to each end-user. To learn more about large-scale multi-GPU training, refer to Train 175+ billion parameter NLP models with model parallel additions and Hugging Face on Amazon SageMaker and New performance improvements in Amazon SageMaker model parallel library.
- The models you use can be fine-tuned and served on a single GPU. That is, you have no need for distributed training nor serving. For more information about multi-GPU hosting, refer to How Mantium achieves low-latency GPT-J inference with DeepSpeed on Amazon SageMaker and Deploy BLOOM-176B and OPT-30B on Amazon SageMaker with large model inference Deep Learning Containers and DeepSpeed.
Next, let’s review the technical requirements and workflow for an application that supports fine-tuning and serving of potentially thousands of personalized models. The workflow generally consists of two parts:
- Generate a personalized model via lightweight fine-tuning of the base pre-trained model
- Host the personalized model for on-demand inference requests when the user returns
One of the considerations for the first part of the workflow is that we should be prepared for unpredictable and spiky user traffic. The peaks in usage could arise, for example, due to new foundation model releases or fresh SaaS feature rollouts. This will impose large intermittent GPU capacity needs, as well as a need for asynchronous fine-tuning job launches to absorb the traffic spike.
With respect to model hosting, as the market floods with AI-based SaaS applications, speed of service becomes a distinguishing factor. A snappy, smooth user experience could be impaired by infrastructure cold starts or high inference latency. Although inference latency requirements will depend on the use case and user expectations, in general this consideration leads to a preference for real-time model hosting on GPUs (as opposed to slower CPU-only hosting options). However, real-time GPU model hosting can quickly lead to high operational costs. Therefore, it’s vital for us to define a hosting strategy that will prevent costs from growing linearly with the number of deployed models (active users).
Solution architecture
Before we describe the proposed architecture, let’s discuss why SageMaker is a great fit for our application requirements by looking at some of its features.
First, SageMaker Training and Hosting APIs provide the productivity benefit of fully managed training jobs and model deployments, so that fast-moving teams can focus more time on product features and differentiation. Moreover, the launch-and-forget paradigm of SageMaker Training jobs perfectly suits the transient nature of the concurrent model fine-tuning jobs in the user onboarding phase. We discuss more considerations on concurrency in the next section.
Second, SageMaker supports unique GPU-enabled hosting options for deploying deep learning models at scale. For example, NVIDIA Triton Inference Server, a high-performance open-source inference software, was natively integrated into the SageMaker ecosystem in 2022. This was followed by the launch of GPU support for SageMaker multi-model endpoints, which provides a scalable, low-latency, and cost-effective way to deploy thousands of deep learning models behind a single endpoint.
Finally, when we get down to the infrastructure level, these features are backed by best-in-class compute options. For example, the G5 instance type, which is equipped with NVIDIA A10g GPUs (unique to AWS), offers a strong price-performance ratio, both for model training and hosting. It yields a lowest cost per FP32 FLOP (an important measure of how much compute power you get per dollar) across the GPU-instance palette on AWS, and greatly improves on the previous lowest cost GPU instance type (G4dn). For more information, refer to Achieve four times higher ML inference throughput at three times lower cost per inference with Amazon EC2 G5 instances for NLP and CV PyTorch models.
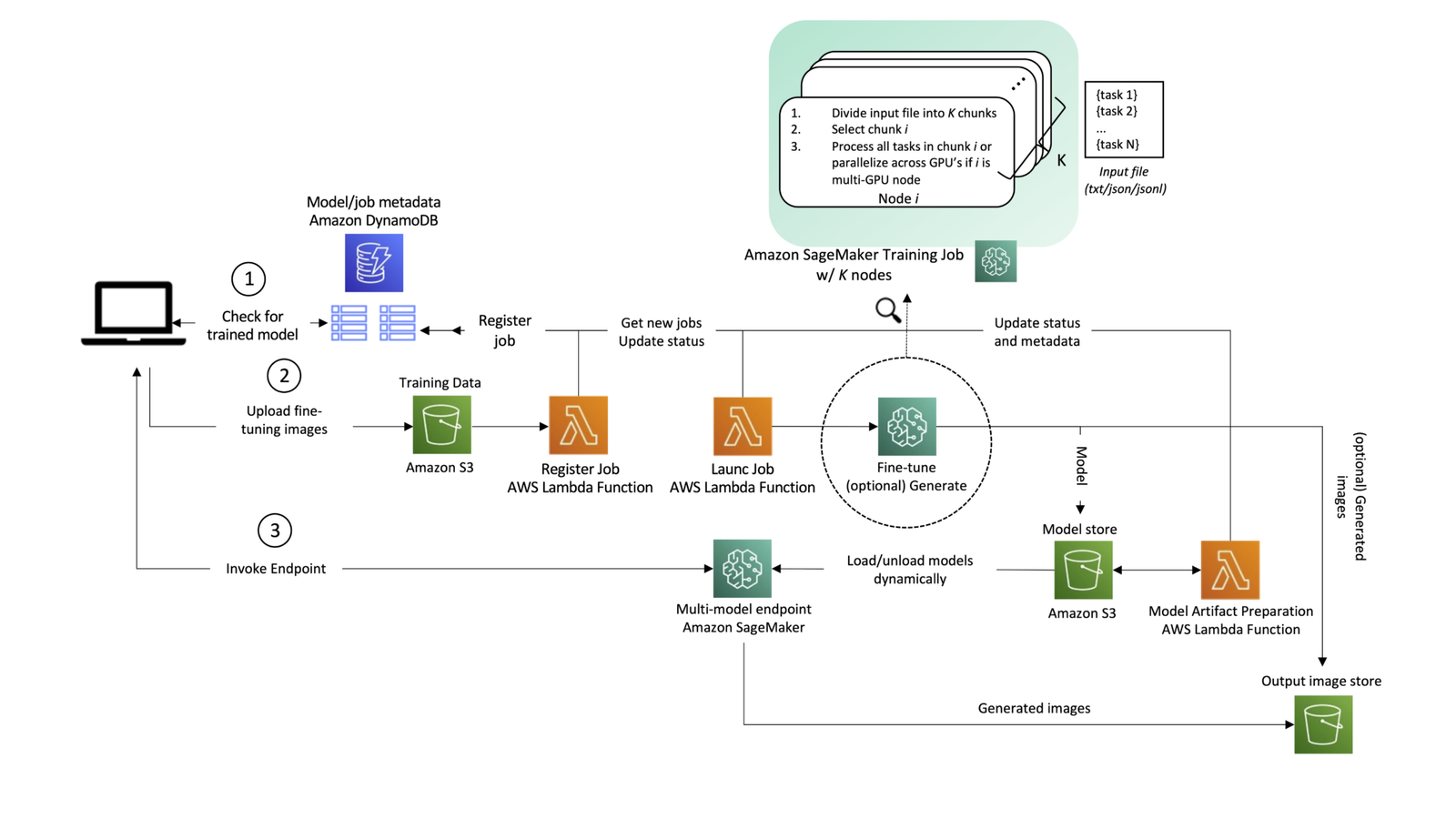
Although the following architecture generally applies to various generative AI use cases, let’s use text-to-image generation as an example. In this scenario, an image generation app will create one or multiple custom, fine-tuned models for each of its users, and those models will be available for real-time image generation on demand by the end-user. The solution workflow can then be divided into two major phases, as is evident from the architecture. The first phase (A) corresponds to the user onboarding process—this is when a model is fine-tuned for the new user. In the second phase (B), the fine-tuned model is used for on-demand inference.

Let’s go through the steps in the architecture in more detail, as numbered in the diagram.
1. Model status check
When a user interacts with the service, we first check if it’s a returning user that has already been onboarded to the service and has personalized models ready for serving. A single user might have more than one personalized model. The mapping between user and corresponding models is saved in Amazon DynamoDB, which serves as a fully managed, serverless, non-relational metadata store, which is easy to query, inexpensive, and scalable. At a minimum, we recommend having two tables:
- One to store the mapping between users and models. This includes the user ID and model artifact Amazon Simple Storage Service (Amazon S3) URI.
- Another to serve as a queue, storing the model creation requests and their completion status. This includes the user ID, model training job ID, and status, along with hyperparameters and metadata associated with training.
2. User onboarding and model fine-tuning.
If no model has been fine-tuned for the user before, the application uploads fine-tuning images to Amazon S3, triggering an AWS Lambda function to register a new job to a DynamoDB table.
Another Lambda function queries the table for a new job and launches it with SageMaker Training. It can be triggered for each record using Amazon DynamoDB Streams, or on a schedule using Amazon EventBridge (a pattern that is tried and tested by AWS customers, including internally at Amazon). Optionally, images or prompts can be passed for inference, and processed directly in the SageMaker Training job right after the model is trained. This can help shorten the time to deliver the first images back to the application. As images are generated, you can exploit the checkpoint sync mechanism in SageMaker to upload intermediate results to Amazon S3. Regarding job launch concurrency, the SageMaker CreateTrainingJob API supports a request rate of one per second, with larger burst rates available during high traffic periods. If you sustainably need to launch more than one fine-tuning task per second (TPS), you have the following controls and options:
- Use SageMaker Managed Warm Pools, which let you retain and reuse provisioned infrastructure after the completion of a training job to reduce cold start latency for repetitive workloads.
- Implement retries in your launch job Lambda function (shown in the architecture diagram).
- Ultimately, if the fine-tuning request rate will consistently be above 1 TPS, you can launch N fine-tunings in parallel with a single SageMaker Training job by requesting a job with
num_instances=K, and spreading the work over the different instances. An example of how you can achieve this is to pass a list of tasks to be run as an input file to the training job, and each instance processes a different task or chunk of this file, differentiated by the instance’s numerical identifier (found in resourceconfig.json). Keep in mind individual tasks shouldn’t differ greatly in training duration, so as to avoid the situation where a single task keeps the whole cluster up and running for longer than needed.
Finally, the fine-tuned model is saved, triggering a Lambda function that prepares the artifact for serving on a SageMaker multi-model endpoint. At this point, the user could be notified that training is complete and the model is ready for use. Refer to Managing backend requests and frontend notifications in serverless web apps for best practices on this.
3. On-demand serving of user requests
If a model has been previously fine-tuned for the user, the path is much simpler. The application invokes the multi-model endpoint, passing the payload and the user’s model ID. The selected model is dynamically loaded from Amazon S3 onto the endpoint instance’s disk and GPU memory (if it has not been recently used; for more information, refer to How multi-model endpoints work), and used for inference. The model output (personalized content) is finally returned to the application.
The request input and output should be saved to S3 for the user’s future reference. To avoid impacting request latency (the time measured from the moment a user makes a request until a response is returned), you can do this upload directly from the client application, or alternatively within your endpoint’s inference code.
This architecture provides the asynchrony and concurrency that were part of the solution requirements.
Conclusion
In this post, we walked through considerations to fine-tune and serve hyper-personalized AI models at scale, and proposed a flexible, cost-efficient solution on AWS using SageMaker.
We didn’t cover the use case of large model pre-training. For more information, refer to Distributed Training in Amazon SageMaker and Sharded Data Parallelism, as well as stories on how AWS customers have trained massive models on SageMaker, such as AI21 and Stability AI.
About the Authors
 João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
 Dr. Alexander Arzhanov is an AI/ML Specialist Solutions Architect based in Frankfurt, Germany. He helps AWS customers to design and deploy their ML solutions across EMEA region. Prior to joining AWS, Alexander was researching origins of heavy elements in our universe and grew passionate about ML after using it in his large-scale scientific calculations.
Dr. Alexander Arzhanov is an AI/ML Specialist Solutions Architect based in Frankfurt, Germany. He helps AWS customers to design and deploy their ML solutions across EMEA region. Prior to joining AWS, Alexander was researching origins of heavy elements in our universe and grew passionate about ML after using it in his large-scale scientific calculations.
 Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
 Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing (NLP), large language models (LLMs), and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing (NLP), large language models (LLMs), and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.