Let’s Build a RAG-Powered Research Paper Assistant
In the era of generative AI, people have relied on LLM products such as ChatGPT to help with tasks.
In the era of generative AI, people have relied on LLM products such as ChatGPT to help with tasks.
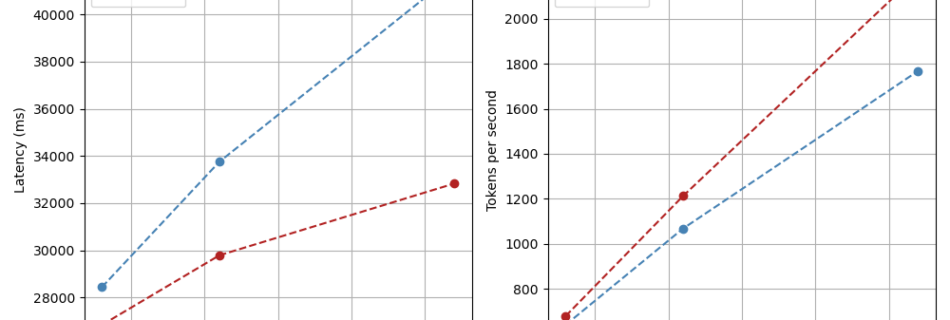
Today, we’re excited to announce the launch of Amazon SageMaker Large Model Inference (LMI) container v15, powered by vLLM 0.8.4 with support for the vLLM V1 engine. This version now supports the latest open-source models, such as Meta’s Llama 4 models Scout and Maverick, Google’s Gemma 3, Alibaba’s Qwen, Mistral AI, DeepSeek-R, and many more. …
Last year, Google Cloud and LangChain announced integrations that give generative AI developers access to a suite of LangChain Python packages. This allowed application developers to leverage Google Cloud’s database portfolio in their gen AI applications to drive the most value from their private data. Today, we are expanding language support for our integrations to …
Read more “Google Cloud Database and LangChain integrations now support Go, Java, and JavaScript”
Researchers from MIT, Yale, McGill University and others found that adapting the Sequential Monte Carlo algorithm can make AI-generated code better.Read More
The future of Elon Musk’s electric car company is murky. It may rest on Tesla’s forthcoming self-driving taxi service, which Musk says will launch this summer.
Researchers have developed a new robotic framework powered by artificial intelligence — called RHyME (Retrieval for Hybrid Imitation under Mismatched Execution) — that allows robots to learn tasks by watching a single how-to video.
Cornell University researchers have developed a new robotic framework powered by artificial intelligence—called RHyME (Retrieval for Hybrid Imitation under Mismatched Execution)—that allows robots to learn tasks by watching a single how-to video.
Discover the 7 traits of marketing teams leading in AI—plus a roadmap to help your team unlock its full potential.
Python is one of the most popular languages for machine learning, and it’s easy to see why.
This post is divided into seven parts; they are: – Core Text Generation Parameters – Experimenting with Temperature – Top-K and Top-P Sampling – Controlling Repetition – Greedy Decoding and Sampling – Parameters for Specific Applications – Beam Search and Multiple Sequences Generation Let’s pick the GPT-2 model as an example.