Made a bunch of pepes with SD. I like this one
submitted by /u/Call_Me_J [link] [comments]
submitted by /u/Call_Me_J [link] [comments]

Mother’s Day is rooted in the idea of showing appreciation. So it’s no wonder it has also become one of the most popular gifting holidays. According to the National Retail Federation or NRF, Mother’s Day spending has hit a record high. In 2023, consumers plan to spend an average of $274.02. The top three gift …
Read more “The Evolution of Gratitude in Mother’s Day Marketing”
Google previewed its new generative AI search experience today at Google I/O 2023. What do the changes mean for SEOs and content marketers?
This paper considers the learning of logical (Boolean) functions with focus on the generalization on the unseen (GOTU) setting, a strong case of out-of-distribution generalization. This is motivated by the fact that the rich combinatorial nature of data in certain reasoning tasks (e.g., arithmetic/logic) makes representative data sampling challenging, and learning successfully under GOTU gives …
Read more “Generalization on the Unseen, Logic Reasoning and Degree Curriculum”

Secure Data Sharing: Charting a course for the EU’s Digital Future The past several years have highlighted just how vital it has become for government and commercial companies alike to have access to a comprehensive and up-to-date data foundation to make well-informed decisions. From supporting with the distribution of PPE in the fight against COVID-19, to …
Read more “Secure Data Sharing: Charting a course for the EU’s digital future”
This week, we’re thrilled to bring together thousands of IBM clients, partners, business leaders and stakeholders at our annual Think® Conference being held in Orlando, Florida. For IBM, Think is all about how we support organizations in their digital transformation and help them compete in their markets via the use of technological innovation. There’s a …

Posted by Andrew Carroll, Product Lead, and Kishwar Shafin, Research Scientist, Genomics For decades, researchers worked together to assemble a complete copy of the molecular instructions for a human — a map of the human genome. The first draft was finished in 2000, but with several missing pieces. Even when a complete reference genome was …
Read more “Building better pangenomes to improve the equity of genomics”
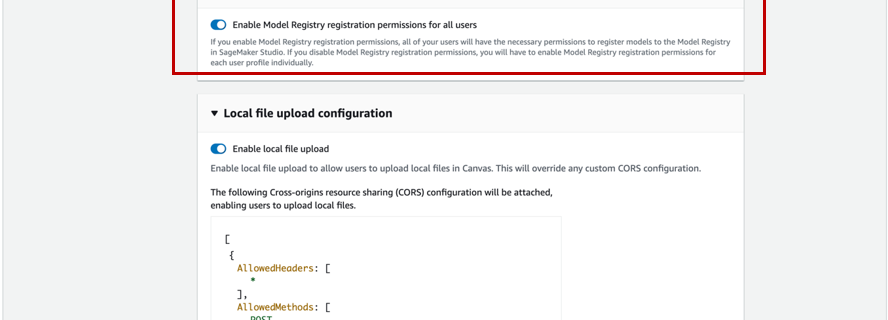
You can now register machine learning (ML) models built in Amazon SageMaker Canvas with a single click to the Amazon SageMaker Model Registry, enabling you to operationalize ML models in production. Canvas is a visual interface that enables business analysts to generate accurate ML predictions on their own—without requiring any ML experience or having to …
Over the past decade, artificial intelligence has evolved from experimental prototypes and early successes to mainstream enterprise use. And the recent advancements in generative AI have begun to change the way we create, connect, and collaborate. As Google CEO Sundar Pichai said in his keynote, every business and organization is thinking about how to drive …
Artificial intelligence is teaming with crowdsourcing to improve mRNA vaccines’ thermostability — the ability to avoid breaking down under heat stress — making distribution more accessible worldwide. In this episode of the NVIDIA AI Podcast, host Noah Kravitz interviews Bojan Tunguz, a physicist and senior system software engineer, and Johnny Israeli, senior manager of AI …
Read more “How AI and Crowdsourcing Can Advance mRNA Vaccine Distribution”