AI models continue to get bigger, requiring larger compute clusters with exa-FLOPs (10^18 FLOPs) of computing. While large-scale models continue to unlock new capabilities, driving down the cost of training and serving these models is the key to sustaining the pace of this innovation.
Typically, the tensor operations (ops)1 are the most compute-intensive part of large artificial intelligence (AI) models. The recently announced Cloud TPU v5e can execute INT8 tensor ops up to 2x faster than the default BFLOAT16 tensor ops. Similarly, some NVIDIA GPUs can execute FLOAT8 or INT8 tensor ops up to 2x faster than BFLOAT16 tensor ops. In order to benefit from these capabilities, especially in production settings, comprehensive software support is needed.
This is where quantization comes into play. Quantization enables reduced (e.g. INT8) precision operations (i.e. tensor ops) and is one of the few effective methods for significantly increasing the efficiency of modern machine learning (ML) hardware. Quantized training reduces the hardware cost of training ML models.
Quantized training acceleration is hard
There are three families of model quantization algorithms:
- Post Training Quantization (PTQ)
- Quantization Aware Training (QAT)
- Quantized Training (QT)
PTQ is a process of turning weights from BFLOAT16 to INT8 (or other similar format). It has the advantage of not requiring access to training data or to the training hardware. However, because we train a different model than we actually serve, it often suffers from poor quality. PTQ also usually does not utilize accelerated INT8 tensor operations.
QAT improves on PTQ by introducing the quantization logic in the forward pass, before the training or before fine-tuning. It allows the training process to take into account quantization numerics and learn around it. This process makes it easy to obtain improved model quality. QAT also allows quantization of both tensor operation inputs and which enables the use of INT8 tensor acceleration on TPU v5e during inference. QAT training length remains unchanged.
QT takes quantization a step further. Not only is the forward pass quantized, but so is the backward pass (gradient backpropagation). This preserves all the benefits of QAT while also accelerating the training itself.
Even with the right algorithm, getting QT to work on real hardware in production can be hard due to software complexity and computational overheads of quantization. Up until now QT (including backpropagation quantization) was largely confined to research papers. However, the open-source AQT library hides the software complexity and algorithmic complexity, allowing any production model owner to benefit from QT, increasing the value of TPU v5e to users, and considerably simplifying QT research.
Introducing Accurate Quantized Training (AQT) library
We’re excited to introduce the open-source Accurate Quantization Training (AQT) library that provides the software support needed for easy tensor operation quantization in JAX.
The main goals of AQT library is to simultaneously provide:
- improved training performance in production
- improved model quality with no hand-tuning
- A simple and flexible API to simultaneously serve production and quantization research
For more information, consult AQT README.md.
AQT INT8-mode delivers improved hardware performance
AQT has allowed us to achieve remarkable speed improvements in large language model (LLM) training. Numbers below indicate BFLOAT16 / INT8 step time ratio measured on MaxText 16B and MLPerfTM 3.1 results:
- MaxText 16B training: 9,054 ms / 7,268 ms = 124%
- MLPerfTM 3.1 GPT-3 175B Training: 11,798ms / 8,431ms = 139%
Details of AQT configuration and MaxText model configuration can be found in the appendix. All runs used Google Cloud TPU v5e.
MaxText experiments were done before we implemented additional AQT optimization (local AQT) for MLPerfTM 3.1.
AQT delivers improved model quality
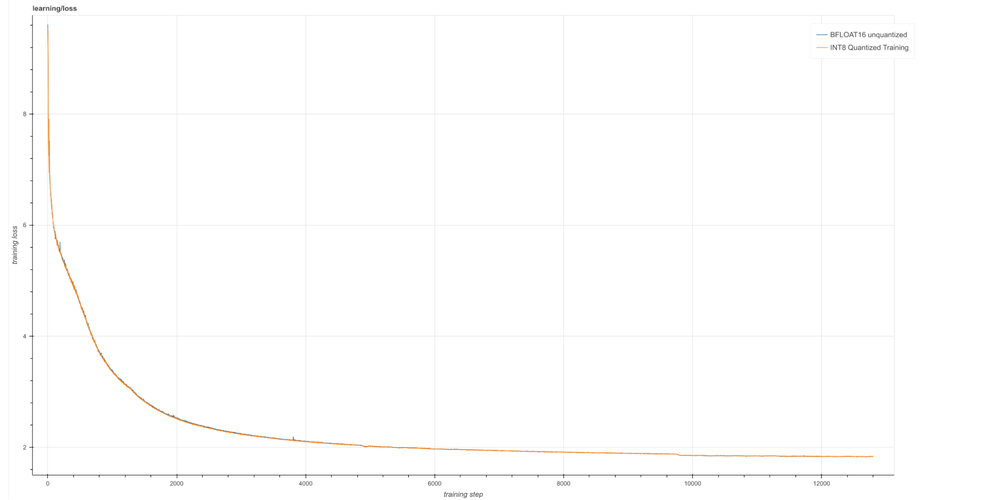
The quality difference between the AQT INT8 and BFLOAT16 models measured as training loss deterioration is almost indistinguishable even with a long training.
Measuring tiny model differences
To measure miniscule quantization-induced deterioration, one needs to remove other sources of noise from the training loss. We configured MaxText to train deterministically by controlling the randomness of model initialization and data generation. The variation in training loss caused by either of them is larger than the quantization-induced deterioration of the training loss.
Results
We measure quantization quality by quantization-induced loss of training loss, i.e., the difference between training loss in BF16 and INT8 models. The quantization-induced deterioration of training loss is 0.00133, which is less than 0.1% of the final training loss. The tradeoff of this relatively insignificant loss in return for a considerable amount of training performance boost validates the power of AQT and INT8 techniques compared to unquantized BFLOAT16 training.
The plot shows a log loss of quantized and unquantized 16B models (configuration details in the appendix).

The curves are overlapping, so let’s zoom-in. We can see that the model quality is indeed very similar:

To summarize the difference, we average the training loss over the last 500 steps:
1.8321251– BFLOAT16 model1.8334553– AQT INT8 model
What You Train Is What You Serve
Last but not least, with AQT, the quantized model’s forward pass is bit-exact-identical during training and serving. This sidesteps the conventional issue of quantization-induced training-serving bias that one typically gets from PTQ.
In all the experiments above, we quantized almost all tensor ops in the forward pass (7 out of 8 except one tensor op inside of the Transformer’s Attention module) and the corresponding tensor ops in the backward pass. Apart from training acceleration, the direct consequence is that the trained model is already quantized and therefore, it benefits from INT8 acceleration of the inference hardware.
AQT is JAX-universal and easy to use
Quantizing all JAX tensor operations requires only a quantized variant of the jax.lax.dot_general function. We modified JAX to allow the injection of alternative dot_general. Quantization Injection was adopted by Flax, Pax and other frameworks and by other quantization libraries such as NVIDIA’s FP8 Transformer Engine.
AQT’s main API is a function that creates quantized dot_general based on a configuration.
The simplified MLP block below was taken from a Flax Transformer model and shows how easy it is to quantize a model using AQT injection:
- code_block
- <ListValue: [StructValue([(‘code’, ‘class MlpBlock(nn.Module):rnrnrn @nn.compactrn def __call__(self, inputs):rn aqt_config = aqt_config.fully_quantized()rn dot_general = aqt.make_dot_general(self.aqt_config)rn x = inputsrn x = nn.Dense(dot_general=dot_general, features = inputs.shape[-1] * 4)(x)rn x = nn.relu(x)rn x = nn.Dense(dot_general=dot_general, features = inputs.shape[-1])(x)rn return x’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b040734c0>)])]>
AQT is flexible for both production and research applications
The example above uses a specific default configuration, but the config system is much more flexible.
config.DotGeneral can configure forward pass tensor op and the corresponding backward pass tensor op separately:
- code_block
- <ListValue: [StructValue([(‘code’, ‘@dataclasses.dataclassrnclass DotGeneral:rn “””Configuration of quantization of dot_general and its gradients.”””rn fwd: DotGeneralRawrn dlhs: DotGeneralRawrn drhs: DotGeneralRaw’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b040736a0>)])]>
In each config.DotGeneralRaw we can configure the quantization of each tensor separately and the hardware dtype to use (eg. jnp.bfloat16, jnp.float16, jnp.float8_e4m3fn, jnp.float8_e5m2, jnp.int8, jnp.int4):
- code_block
- <ListValue: [StructValue([(‘code’, ‘@dataclasses.dataclassrnclass DotGeneralRaw:rn “””Configuration of quantization of one dot_general without gradient.”””rn lhs: Tensor # left hand sidern rhs: Tensor # right hand sidern dg_in_dtype: Optional[DType]rn dg_accumulator_dtype: Optional[DType]’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b04073c10>)])]>
Inside config.Tensor we can configure the numerics used for each tensor, which include the number of bits, the calibration algorithm, stochastic rounding, and many other quantization parameters. At publication time, we are refactoring config.Tensor, so are not publishing the code today. To see its current state, refer to AQT README.md.
Quantization research. config.Tensor also allows quantization researchers to inject custom code to any part of the algorithm. This makes it easy to experiment with custom quantization algorithms without making large code modifications.
We applied older versions of AQT in several papers:
- Pareto-Optimal Quantized ResNet Is Mostly 4-bit
- PokeBNN: A Binary Pursuit of Lightweight Accuracy (Imagenet binarization).
- Binarized Neural Machine Translation (Transformer binarization).
Hardware research. AQT’s flexibility enables us to work with all the hardware vendors to ensure the best numerical recipes are available on their hardware in Jax even if their numerics are not public.
Conclusions and what’s next
AQT is the first library that accelerates training and inference using INT8 with negligible quality loss in production settings.
For more details, please see AQT README.md.
Acknowledgements
Rafi Witten, Matt Davidow, Marcello Maggioni and Tammo Spalink significantly contributed to this work.
Appendix: Model configuration
MaxText model configuration
- 16 billion parameters: 32 layers decoder-only transformer. 5120 embedding dimension.
This is the largest model that we could afford to do a full Chinchilla-length training. - C4 dataset
- Trained with 355 billion non-padding tokens (using “Chinchilla” scaling “#tokens = 20x #weights”)
- 4096 v5e TPUs
Quantization configuration
Definition: “INT8 quantized tensor op” means that tensor op takes both inputs as INT8 and accumulates in int32 or bf16. The details of a simplest variant of the math used in INT8-AQT are in the section towards the end of this post.
In the forward pass, we INT8-quantized all tensor ops in each Transformer layer except for one tensor op in each attention, which was more sensitive. We also quantized the model head — the “logits” layer.
For each tensor op in the forward pass there are two tensor ops in the backward pass, one computing the gradients for the previous layer (backprop spine) and one feeding the optimizer with a weight gradient.
For each tensor op quantized in the forward pass, we INT8-quantize one of the backprop tensor ops but we leave the other one using bf16 inputs.
For MLPerf experiments where we already had local AQT, we quantized both backprop tensor ops.
Appendix: AQT – How does it work internally?
You can run the code in this section in Google Colab. Even though we provide working code, this is not an AQT tutorial. This code illustrates what AQT is doing internally and one of the reasons why it achieves such good quality.
The code
In this section we:
- Show how to get quantization acceleration in JAX
- Explain what AQT INT8 is doing under the hood (using the simplest INT8 configuration)
- Run the code on a simple example
matmul_true_int8 takes true INT8 as inputs, and returns int32. This is how you get hardware acceleration of quantized matmul in JAX.
- code_block
- <ListValue: [StructValue([(‘code’, ‘import jax.numpy as jnprnrnrndef matmul_true_int8(lhs, rhs):rn assert lhs.dtype == jnp.int8rn assert rhs.dtype == jnp.int8rn result = jnp.matmul(lhs, rhs, preferred_element_type=jnp.int32)rn assert result.dtype == jnp.int32rn return result’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b04073550>)])]>
Let’s generate some random data:
- code_block
- <ListValue: [StructValue([(‘code’, ‘def gen_matrix(rows, columns):rn import numpy as nprn return np.random.normal(size=(rows, columns)).reshape((rows, columns))rnrnrnbatch_size = 3rnchannels_in = 4rnchannels_out = 5rnrnrna = gen_matrix(batch_size, channels_in) # Activationsrnw = gen_matrix(channels_in, channels_out) # Weights’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b040739d0>)])]>
This is how AQT works internally in the simplest configuration.
Even though we used names such as “batch” and “channels”, “w” and “a”, which are evocative of neural networks, the aqt_matmul_int8 algorithm is not DNN-specific:
- code_block
- <ListValue: [StructValue([(‘code’, ‘def aqt_matmul_int8(a, w):rn max_int8 = 127rn # This function is customizable and injectable, i.e:rn # users can inject custom quant code into AQT.rn def quant_int8(x):rn return jnp.clip(jnp.round(x), -max_int8, max_int8).astype(jnp.int8)rnrnrn # Calibration. Calibration function is also customizable and injectable.rn a_s = max_int8 / jnp.max(jnp.abs(a), axis=1, keepdims=True)rn w_s = max_int8 / jnp.max(jnp.abs(w), axis=0, keepdims=True)rn assert a_s.shape == (batch_size, 1) # shapes checked for illustrationrn assert w_s.shape == (1, channels_out)rnrnrn # int8 matmul with int32 accumulatorrn result = matmul_true_int8(quant_int8(a * a_s), quant_int8(w * w_s)) / (a_s * w_s)rn assert result.shape == (batch_size, channels_out)rnrnrn return result’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b04073c70>)])]>
Note that each example in a batch and each output channel have their own separate scale. This reduces the effect of outliers in “w” and “a” to just one row or column, making a tighter calibration and much better-quality quantization.
Let’s compare our aqt_matmul_int8 to float matmul:
- code_block
- <ListValue: [StructValue([(‘code’, ‘# Testrnprint(f”jnp.matmul(a, w):\n”, jnp.matmul(a, w))rnprint(f”aqt_matmul_int8(a, w):\n”, aqt_matmul_int8(a, w))’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b06d3b700>)])]>
The output is actually pretty close:
- code_block
- <ListValue: [StructValue([(‘code’, ‘jnp.matmul(a, w):rn [[ 1.5624856 -3.1478074 -1.5752552 -1.4495506 1.0090733 ]rn [ 0.29254508 7.1422215 5.727523 0.44506502 6.4406257 ]rn [ 1.2321283 6.8613167 2.9342046 3.6453876 -0.8610003 ]]rnaqt_matmul_int8(a, w):rn [[ 1.5674045 -3.162498 -1.5563929 -1.4555793 1.0295792 ]rn [ 0.29618874 7.1315236 5.713755 0.4294895 6.44319 ]rn [ 1.2380412 6.864083 2.9387994 3.6532555 -0.8485654 ]]’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e7b0a0ff430>)])]>
Analyzing this code provides insights on why AQT is so efficient. In particular, we calibrate AQT with per-example scales and per-output channel scales. This makes the quantization much tighter and suffers from less quantization noise. Importantly, it also reduces cross-machine communication in the case of distributed (collective) matmuls.
1. In this post, by “tensor op” we mean any form of matrix-multiplication, convolutions and higher-order analogues used in Transformers, e.g., jnp.einsum, flax.DenseGeneral, and other tensor ops in JAX. This excludes vector ops such as Relu or LayerNorm. At this time AQT quantizes only tensor ops.