Anthropic Supply-Chain-Risk Designation Halted by Judge
A judge temporarily blocked the Trump administration’s designation, clearing the way for Anthropic to keep doing business without the label starting next week.
A judge temporarily blocked the Trump administration’s designation, clearing the way for Anthropic to keep doing business without the label starting next week.
OpenAI’s GPT models can often be fooled into declaring that “pseudo-literary” nonsense is great, a German researcher has found.
If only it works well with work flow. Nvidia have CUDA, AMD have ROCM, I don’t even know what Intel have aside from DirectX which everyone can use submitted by /u/SQRSimon [link] [comments]
My friend who is a developer once asked an LLM to generate documentation for a payment API.
We introduce exclusive self attention (XSA), a simple modification of self attention (SA) that improves Transformer’s sequence modeling performance. The key idea is to constrain attention to capture only information orthogonal to the token’s own value vector (thus excluding information of self position), encouraging better context modeling. Evaluated on the standard language modeling task, XSA …

Video content is now everywhere, from security surveillance and media production to social platforms and enterprise communications. However, extracting meaningful insights from large volumes of video remains a major challenge. Organizations need solutions that can understand not only what appears in a video, but also the context, narrative, and underlying meaning of the content. In …
Read more “Unlocking video insights at scale with Amazon Bedrock multimodal models”
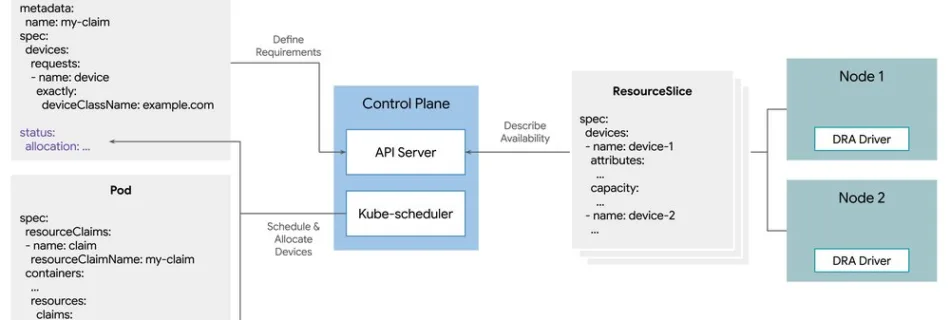
The explosion of large language models (LLMs) has increased demand for high-performance accelerators like GPUs and TPUs. As organizations scale their AI capabilities, the scarcity of compute resources is sometimes the primary bottleneck. Efficiently managing every GPU and TPU cycle is no longer just a recommendation — it’s an operational necessity. Kubernetes is becoming the …
Read more “DRA: A new era of Kubernetes device management with Dynamic Resource Allocation”
I tested more than 30 air fryers this past year. The Typhur Dome 2 is the one I recommend, and it’s uncommonly cheap right now.
To get the best out of AI, some users tell it to provide answers as if it were an expert. Others ask it to adopt a persona, such as a safety monitor, to guide its responses. However, this approach can sometimes hurt performance, according to a study available on the arXiv preprint server.
submitted by /u/Affectionate_Fee232 [link] [comments]