How to enable real time semantic search and RAG applications with Dataflow ML
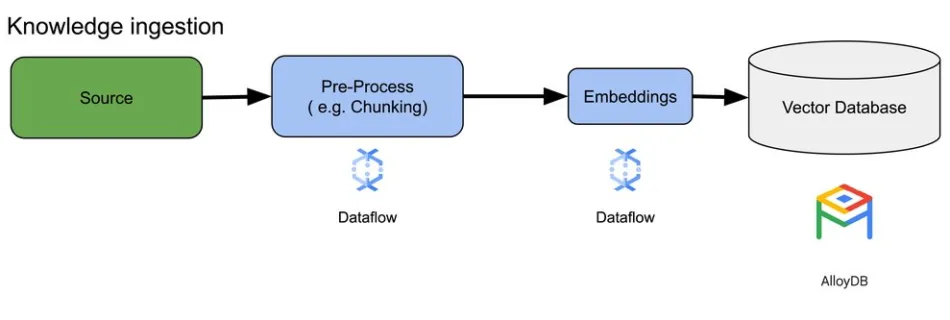
Embeddings are a cornerstone of modern semantic search and Retrieval Augmented Generation (RAG) applications. In short, they enable applications to understand and interact with information on a deeper, conceptual level. In this post, we’ll show you how to create and retrieve embeddings with a few lines of Dataflow ML code to enable both of these …
Read more “How to enable real time semantic search and RAG applications with Dataflow ML”