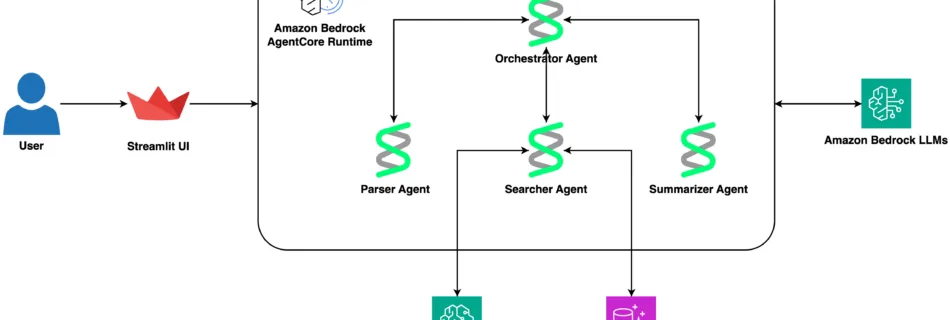
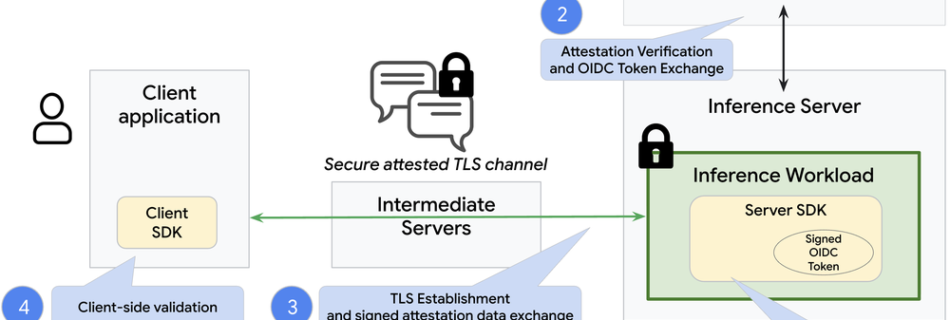
Clustering Unstructured Text with LLM Embeddings and HDBSCAN
The current era of Generative AI seems to primarily focus on chat interfaces and prompts, but the range of applications of large language models , or LLMs for short, is not limited to just that.