
In this post, we discuss a machine learning (ML) solution for complex image searches using Amazon Kendra and Amazon Rekognition. Specifically, we use the example of architecture diagrams for complex images due to their incorporation of numerous different visual icons and text.
With the internet, searching and obtaining an image has never been easier. Most of the time, you can accurately locate your desired images, such as searching for your next holiday getaway destination. Simple searches are often successful, because they’re not associated with many characteristics. Beyond the desired image characteristics, the search criteria typically doesn’t require significant details to locate the required result. For example, if a user tried to search for a specific type of blue bottle, results of many different types of blue bottles will be displayed. However, the desired blue bottle may not be easily found due to generic search terms.
Interpreting search context also contributes to simplification of results. When users have a desired image in mind, they try to frame this into a text-based search query. Understanding the nuances between search queries for similar topics is important to provide relevant results and minimize the effort required from the user to manually sort through results. For example, the search query “Dog owner plays fetch” seeks to return image results showing a dog owner playing a game of fetch with a dog. However, the actual results generated may instead focus on a dog fetching an object without displaying an owner’s involvement. Users may have to manually filter out unsuitable image results when dealing with complex searches.
To address the problems associated with complex searches, this post describes in detail how you can achieve a search engine that is capable of searching for complex images by integrating Amazon Kendra and Amazon Rekognition. Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos.
What images can be too complex to be searchable? One example is architecture diagrams, which can be associated with many search criteria depending on the use case complexity and number of technical services required, which results in significant manual search effort for the user. For example, if users want to find an architecture solution for the use case of customer verification, they will typically use a search query similar to “Architecture diagrams for customer verification.” However, generic search queries would span a wide range of services and across different content creation dates. Users would need to manually select suitable architectural candidates based on specific services and consider the relevance of the architecture design choices according to the content creation date and query date.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution.

For users who are not familiar with the service offerings that are provided on the cloud platform, they may provide different generic ways and descriptions when searching for such a diagram. The following are some examples of how it could be searched:
- “Orchestrate ETL workflow”
- “How to automate bulk data processing”
- “Methods to create a pipeline for transforming data”
Solution overview
We walk you through the following steps to implement the solution:
- Train an Amazon Rekognition Custom Labels model to recognize symbols in architecture diagrams.
- Incorporate Amazon Rekognition text detection to validate architecture diagram symbols.
- Use Amazon Rekognition inside a web crawler to build a repository for searching
- Use Amazon Kendra to search the repository.
To easily provide users with a large repository of relevant results, the solution should provide an automated way of searching through trusted sources. Using architecture diagrams as an example, the solution needs to search through reference links and technical documents for architecture diagrams and identify the services present. Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user.
Considering the objective of how relevant diagrams should be searched, the image search solution needs to fulfil three criteria:
- Enable simple keyword search
- Interpret search queries based on use cases that users provide
- Sort and order search results
Keyword search is simply searching for “Amazon Rekognition” and being shown architecture diagrams on how the service is used in different use cases. Alternatively, the search terms can be linked indirectly to the diagram through use cases and industry verticals that may be associated with the architecture. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions. Sorting and ordering of search results based on attributes such as creation date would ensure the architecture diagrams are still relevant in spite of service updates and releases. The following figure shows the architecture diagram to the image search solution.
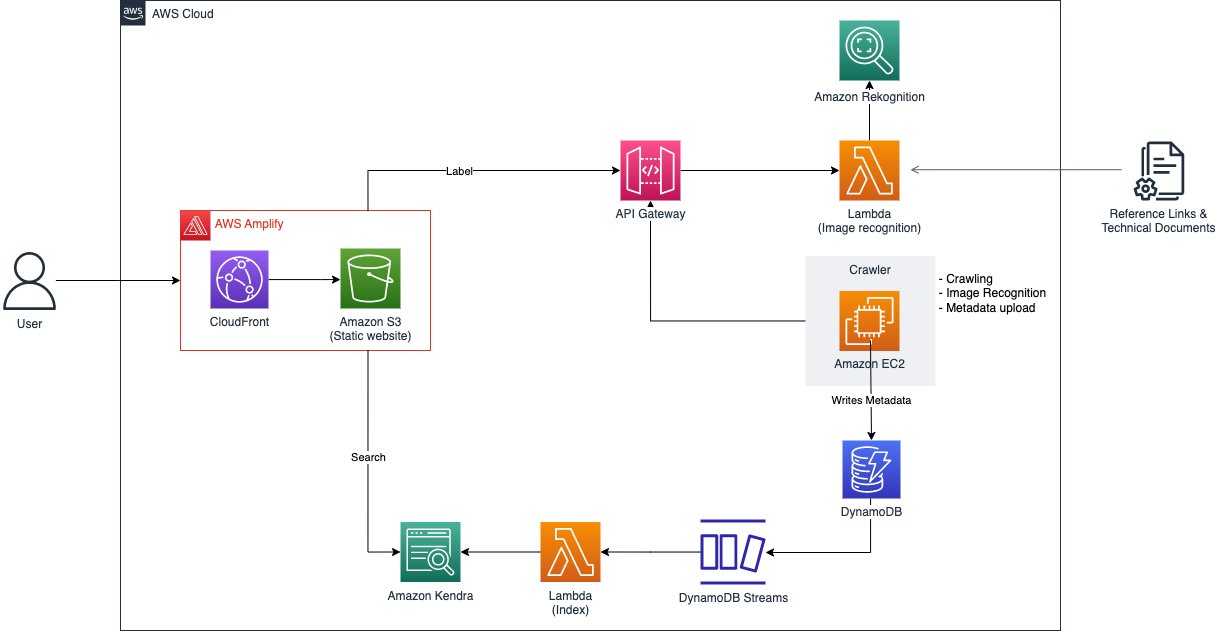
As illustrated in the preceding diagram and in the solution overview, there are two main aspects of the solution. The first aspect is performed by Amazon Rekognition, which can identify objects, people, text, scenes, and activities from images or videos. It consists of pre-trained models that can be applied to analyze images and videos at scale. With its custom labels feature, Amazon Rekognition allows you to tailor the ML service to your specific business needs by labeling images collated from sourcing through architecture diagrams in trusted reference links and technical documents. By uploading a small set of training images, Amazon Rekognition automatically loads and inspects the training data, selects the right ML algorithms, trains a model, and provides model performance metrics. Therefore, users without ML expertise can enjoy the benefits of a custom labels model through an API call, because a significant amount of overhead is reduced. The solution applies Amazon Rekognition Custom Labels to detect AWS service logos on architecture diagrams to allow the architecture diagrams to be searchable with service names. After modeling, detected services of each architecture diagram image and its metadata, like URL origin and image title, are indexed for future search purposes and stored in Amazon DynamoDB, a fully managed, serverless, key-value NoSQL database designed to run high-performance applications.
The second aspect is supported by Amazon Kendra, an intelligent enterprise search service powered by ML that allows you to search across different content repositories. With Amazon Kendra, you can search for results, such as images or documents, that have been indexed. These results can also be stored across different repositories because the search service employs built-in connectors. Keywords, phrases, and descriptions could be used for searching, which allows you to accurately search for diagrams that are related to a particular use case. Therefore, you can easily build an intelligent search service with minimal development costs.
With an understanding of the problem and solution, the subsequent sections dive into how to automate data sourcing through the crawling of architecture diagrams from credible sources. Following this, we walk through the process of generating a custom label ML model with a fully managed service. Lastly, we cover the data ingestion by an intelligent search service, powered by ML.
Create an Amazon Rekognition model with custom labels
Before obtaining any architecture diagrams, we need a tool to evaluate if an image can be identified as an architecture diagram. Amazon Rekognition Custom Labels provides a streamlined process to create an image recognition model that identifies objects and scenes in images that are specific to a business need. In this case, we use Amazon Rekognition Custom Labels to identify AWS service icons, then the images are indexed with the services for a more relevant search using Amazon Kendra. This model doesn’t differentiate whether a picture is an architecture diagram or not; it simply identifies service icons, if any. As such, there may be instances where images that aren’t architecture diagrams end up in the search results. However, such results are minimal.
The following figure shows the steps that this solution takes to create an Amazon Rekognition Custom Labels model.

This process involves uploading the datasets, generating a manifest file that references the uploaded datasets, followed by uploading this manifest file into Amazon Rekognition. A Python script is used to aid in the process of uploading the datasets and generating the manifest file. Upon successfully generating the manifest file, it’s then uploaded into Amazon Rekognition to begin the model training process. For details on the Python script and how to run it, refer to the GitHub repo.
To train the model, in the Amazon Rekognition project, choose Train model, select the project you want to train, then add any relevant tags and choose Train model. For instructions on starting an Amazon Rekognition Custom Labels project, refer to the available video tutorials. The model may take up to 8 hours to train with this dataset.
When the training is complete, you may choose the trained model to view the evaluation results. For more details on the different metrics such as precision, recall, and F1, refer to Metrics for evaluation your model. To use the model, navigate to the Use Model tab, leave the number of inference units at 1, and start the model. Then we can use an AWS Lambda function to send images to the model in base64, and the model returns a list of labels and confidence scores.
Upon successfully training an Amazon Rekognition model with Amazon Rekognition Custom Labels, we can use it to identify service icons in the architecture diagrams that have been crawled. To increase the accuracy of identifying services in the architecture diagram, we use another Amazon Rekognition feature called text detection. To use this feature, we pass in the same picture in base64, and Amazon Rekognition returns the list of text identified in the picture. In the following figures, we compare the original image and what it looks like after the services in the image are identified. The first figure shows the original image.

The following figure shows the original image with detected services.

To ensure scalability, we use a Lambda function, which will be exposed through an API endpoint created using Amazon API Gateway. Lambda is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. Using a Lambda function eliminates a common concern about scaling up when large volumes of requests are made to the API endpoint. Lambda automatically runs the function for the specific API call, which stops when the invocation is complete, thereby reducing cost incurred to the user. Because the request would be directed to the Amazon Rekognition endpoint, having only the Lambda function being scalable is not sufficient. In order for the Amazon Rekognition endpoint to be scalable, you can increase the inference unit of the endpoint. For more details on configuring the inference unit, refer to Inference units.
The following is a code snippet of the Lambda function for the image recognition process:
After creating the Lambda function, we can proceed to expose it as an API using API Gateway. For instructions on creating an API with Lambda proxy integration, refer to Tutorial: Build a Hello World REST API with Lambda proxy integration.
Crawl the architecture diagrams
In order for the search feature to work feasibly, we need a repository of architecture diagrams. However, these diagrams must originate from credible sources such as AWS Blog and AWS Prescriptive Guidance. Establishing credibility of data sources ensures the underlying implementation and purpose of the use cases are accurate and well vetted. The next step is to set up a crawler that can help gather many architecture diagrams to feed into our repository. We created a web crawler to extract architecture diagrams and information such as a description of the implementation from the relevant sources. There are multiple ways that you could achieve building such a mechanism; for this example, we use a program that runs on Amazon Elastic Compute Cloud (Amazon EC2). The program first obtains links to blog posts from an AWS Blog API. The response returned from the API contains information of the post such as title, URL, date, and the links to images found in the post.
The following is a code snippet of the JavaScript function for the web crawling process:
With this mechanism, we can easily crawl hundreds and thousands of images from different blogs. However, we need a filter that only accepts images that contain content of an architecture diagram, which in our case are icons of AWS services, to filter out images that are not architecture diagrams.
This is the purpose of our Amazon Rekognition model. The diagrams go through the image recognition process, which identifies service icons and determines if it could be considered as a valid architecture diagram.
The following is a code snippet of the function that sends images to the Amazon Rekognition model:
After passing the image recognition check, the results returned from the Amazon Rekognition model and the information relevant to it are bundled into their own metadata. The metadata is then stored in a DynamoDB table where the record would be used to ingest into Amazon Kendra.
The following is a code snippet of the function that stores the metadata of the diagram in DynamoDB:
Ingest metadata into Amazon Kendra
After the architecture diagrams go through the image recognition process and the metadata is stored in DynamoDB, we need a way for the diagrams to be searchable while referencing the content in the metadata. The approach to this is to have a search engine that can be integrated with the application and can handle a large amount of search queries. Therefore, we use Amazon Kendra, an intelligent enterprise search service.
We use Amazon Kendra as the interactive component of the solution is because of its powerful search capabilities, particularly with the use of natural language. This adds an additional layer of simplicity when users are searching for diagrams that are closest to what they’re looking for. Amazon Kendra offers a number of data sources connectors for ingesting and connecting contents. This solution uses a custom connector to ingest architecture diagrams’ information from DynamoDB. To configure a data source to an Amazon Kendra index, you can use an existing index or create a new index.
The diagrams crawled then have to be ingested into the Amazon Kendra index that has been created. The following figure shows the flow of how the diagrams are indexed.

First, the diagrams inserted into DynamoDB create a Put event via Amazon DynamoDB Streams. The event triggers the Lambda function that acts as a custom data source for Amazon Kendra and loads the diagrams into the index. For instructions on creating a DynamoDB Streams trigger for a Lambda function, refer to Tutorial: Using AWS Lambda with Amazon DynamoDB Streams
After we integrate the Lambda function with DynamoDB, we need to ingest the records of the diagrams sent to the function into the Amazon Kendra index. The index accepts data from various types of sources, and ingesting items into the index from the Lambda function means that it has to use the custom data source configuration. For instructions on creating a custom data source for your index, refer to Custom data source connector.
The following is a code snippet of the Lambda function for how a diagram could be indexed in a custom manner:
The important factor that enables diagrams to be searchable is the Blob key in a document. This is what Amazon Kendra looks into when users provide their search input. In this example code, the Blob key contains a summarized version of the use case of the diagram concatenated with the information detected from the image recognition process. This allows users to search for architecture diagrams based on use cases such as “Fraud Detection” or by service names like “Amazon Kendra.”
To illustrate an example of what the Blob key looks like, the following snippet references the initial ETL diagram that we introduced earlier in this post. It contains a description of the diagram that was obtained when it was crawled, as well as the services that were identified by the Amazon Rekognition model.
Search with Amazon Kendra
After we put all the components together, the results of an example search of “real time analytics” look like the following screenshot.

By searching for this use case, it produces different architecture diagrams. Users are provided with these different methods of the specific workload that they’re trying to implement.
Clean up
Complete the steps in this section to clean up the resources you created as part of this post:
- Delete the API:
- On the API Gateway console, select the API to be deleted.
- On the Actions menu, choose Delete.
- Choose Delete to confirm.
- Delete the DynamoDB table:
- On the DynamoDB console, choose Tables in the navigation pane.
- Select the table you created and choose Delete.
- Enter delete when prompted for confirmation.
- Choose Delete table to confirm.
- Delete the Amazon Kendra index:
- On the Amazon Kendra console, choose Indexes in the navigation pane.
- Select the index you created and choose Delete
- Enter a reason when prompted for confirmation.
- Choose Delete to confirm.
- Delete the Amazon Rekognition project:
- On the Amazon Rekognition console, choose Use Custom Labels in the navigation pane, then choose Projects.
- Select the project you created and choose Delete.
- Enter Delete when prompted for confirmation.
- Choose Delete associated datasets and models to confirm.
- Delete the Lambda function:
- On the Lambda console, select the function to be deleted.
- On the Actions menu, choose Delete.
- Enter Delete when prompted for confirmation.
- Choose Delete to confirm.
Summary
In this post, we showed an example of how you can intelligently search information from images. This includes the process of training an Amazon Rekognition ML model that acts as a filter for images, the automation of image crawling, which ensures credibility and efficiency, and querying for diagrams by attaching a custom data source that enables a more flexible manner to index items. To dive deeper into the implementation of the codes, refer to the GitHub repo.
Now that you understand how to deliver the backbone of a centralized search repository for complex searches, try creating your own image search engine. For more information on the core features, refer to Getting started with Amazon Rekognition Custom Labels, Moderating content, and the Amazon Kendra Developer Guide. If you’re new to Amazon Rekognition Custom Labels, try it out using our Free Tier, which lasts 3 months and includes 10 free training hours per month and 4 free inference hours per month.
About the Authors
 Ryan See is a Solutions Architect at AWS. Based in Singapore, he works with customers to build solutions to solve their business problems as well as tailor a technical vision to help run more scalable and efficient workloads in the cloud.
Ryan See is a Solutions Architect at AWS. Based in Singapore, he works with customers to build solutions to solve their business problems as well as tailor a technical vision to help run more scalable and efficient workloads in the cloud.
 James Ong Jia Xiang is a Customer Solutions Manager at AWS. He specializes in the Migration Acceleration Program (MAP) where he helps customers and partners successfully implement large-scale migration programs to AWS. Based in Singapore, he also focuses on driving modernization and enterprise transformation initiatives across APJ through scalable mechanisms. For leisure, he enjoys nature activities like trekking and surfing.
James Ong Jia Xiang is a Customer Solutions Manager at AWS. He specializes in the Migration Acceleration Program (MAP) where he helps customers and partners successfully implement large-scale migration programs to AWS. Based in Singapore, he also focuses on driving modernization and enterprise transformation initiatives across APJ through scalable mechanisms. For leisure, he enjoys nature activities like trekking and surfing.
 Hang Duong is a Solutions Architect at AWS. Based in Hanoi, Vietnam, she focuses on driving cloud adoption across her country by providing highly available, secure, and scalable cloud solutions for her customers. Additionally, she enjoys building and is involved in various prototyping projects. She is also passionate about the field of machine learning.
Hang Duong is a Solutions Architect at AWS. Based in Hanoi, Vietnam, she focuses on driving cloud adoption across her country by providing highly available, secure, and scalable cloud solutions for her customers. Additionally, she enjoys building and is involved in various prototyping projects. She is also passionate about the field of machine learning.
 Trinh Vo is a Solutions Architect at AWS, based in Ho Chi Minh City, Vietnam. She focuses on working with customers across different industries and partners in Vietnam to craft architectures and demonstrations of the AWS platform that work backward from the customer’s business needs and accelerate the adoption of appropriate AWS technology. She enjoys caving and trekking for leisure.
Trinh Vo is a Solutions Architect at AWS, based in Ho Chi Minh City, Vietnam. She focuses on working with customers across different industries and partners in Vietnam to craft architectures and demonstrations of the AWS platform that work backward from the customer’s business needs and accelerate the adoption of appropriate AWS technology. She enjoys caving and trekking for leisure.
 Wai Kin Tham is a Cloud Architect at AWS. Based in Singapore, his day job involves helping customers migrate to the cloud and modernize their technology stack in the cloud. In his free time, he attends Muay Thai and Brazilian Jiu Jitsu classes.
Wai Kin Tham is a Cloud Architect at AWS. Based in Singapore, his day job involves helping customers migrate to the cloud and modernize their technology stack in the cloud. In his free time, he attends Muay Thai and Brazilian Jiu Jitsu classes.