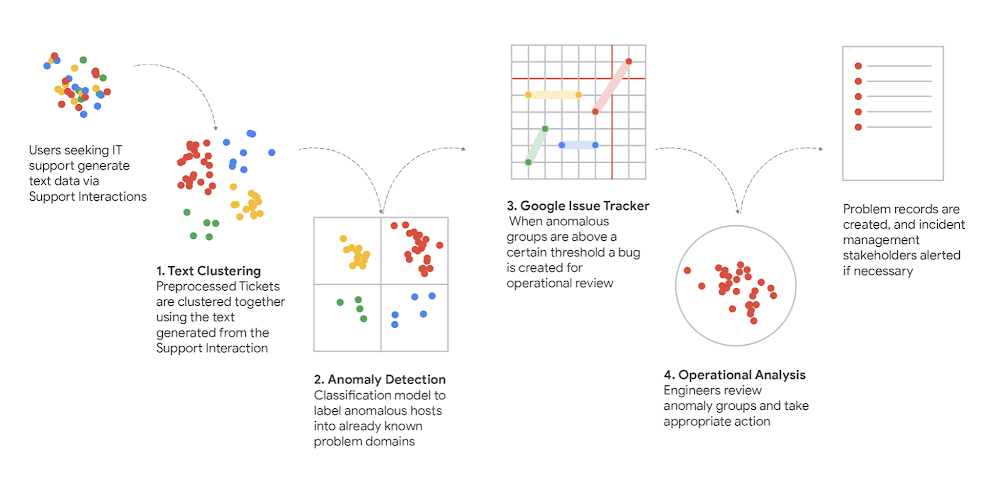
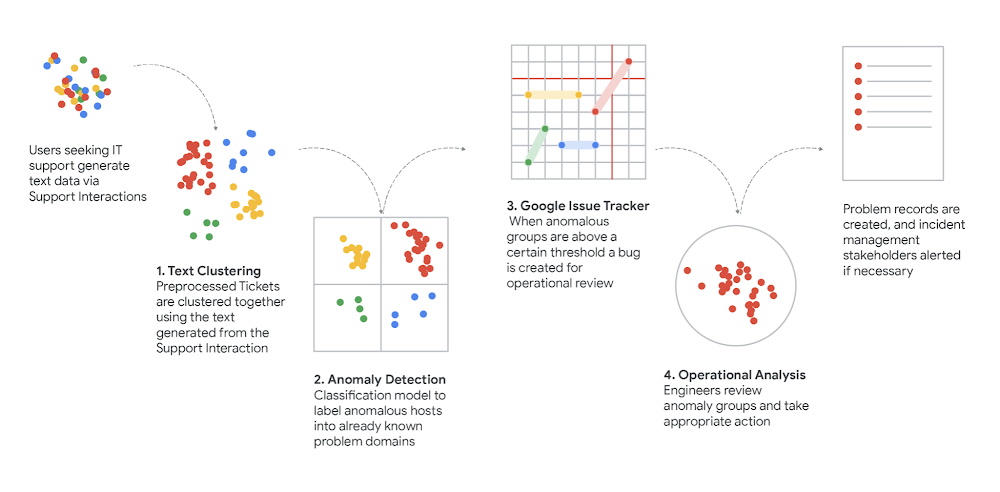
Getting into the details
We wrote previously about how we used clustering to connect requests for support (in text form) to the best tech support articles so we could answer questions faster and more efficiently. In a constantly changing environment (and in a very oddball couple of years) we wanted to make sure we’re focused on preserving our people’s productivity by isolating, understanding and responding to new support trends as fast as we can.
Now we’d like to get into a bit more detail about how we did all that and what went on behind the scenes of our process:
Extraction
Google’s historical support ticket data and metadata are stored in BigQuery, as are the analysis results we generate from that data. We read and write that content using the BigQuery API. However, much of these tickets contain information that is not useful to the ML pipeline and should not be included in the preprocessing and text modeling phases. For example, boilerplate generated from our case management tools must be stripped out using regex and other technologies in order to isolate the IT interaction between the tech and users.
Furthermore, once all boilerplate has been removed, we use part-of-speech tagging to isolate only the nouns within the interaction, since nouns themselves proved to be the best features for modeling an interaction and differentiating a topic. Any one interaction could have 100+ nouns depending on the complexity. Using these nouns, we take one more step and use stemming and lemmatization to remove any suffix that may be placed on the noun (e.g., “computers” becomes “computer”). This allows for any modification of the root words to be modeled as the same feature and reduces noise in our clustering results.
Once each interaction is transformed into a set of nouns (and unique identifier), we can then move on to more advanced preprocessing techniques.
Text Modeling
To cluster the ticket set, it must first be converted into a robust feature space. The core technology underlying our featurization process is TensorFlow transformers, which can be invoked using the TFX API. TensorFlow parses and annotates the tickets’ natural-language contents and these annotations, once normalized and filtered, form a sparse feature space. The Cloud Data Loss Prevention (DLP) API redacts several categories of sensitive information — e.g., person names — from the tickets’ contents, which both mitigates privacy leakage and prunes low-relevance tokens from the feature space.
Although clustering can be performed against a sparse space, it is typically more effective if the space is densified to prune excessive dimensionality. We accomplish this using the term frequency-inverse document frequency (TF-IDF) statistical technique with a predefined maximum feature count – we also investigated more heavy-duty densification strategies using trained embedding models, but found that the quality improvements over TF-IDF were marginal for our use case, at the cost of a substantial reduction in human interpretability.
Clustering
The generated ticket feature set is partitioned into clusters using ClustOn. As this is an unsupervised learning problem, we arrived at the clustering process’s hyper-parameterization values via experimentation and human expert analysis. The trained parameters produced by the algorithm are persisted between subsequent runs of the pipeline in order to maintain consistent cluster IDs; this allows later operational systems to directly track and evaluate a cluster’s evolution over real time.
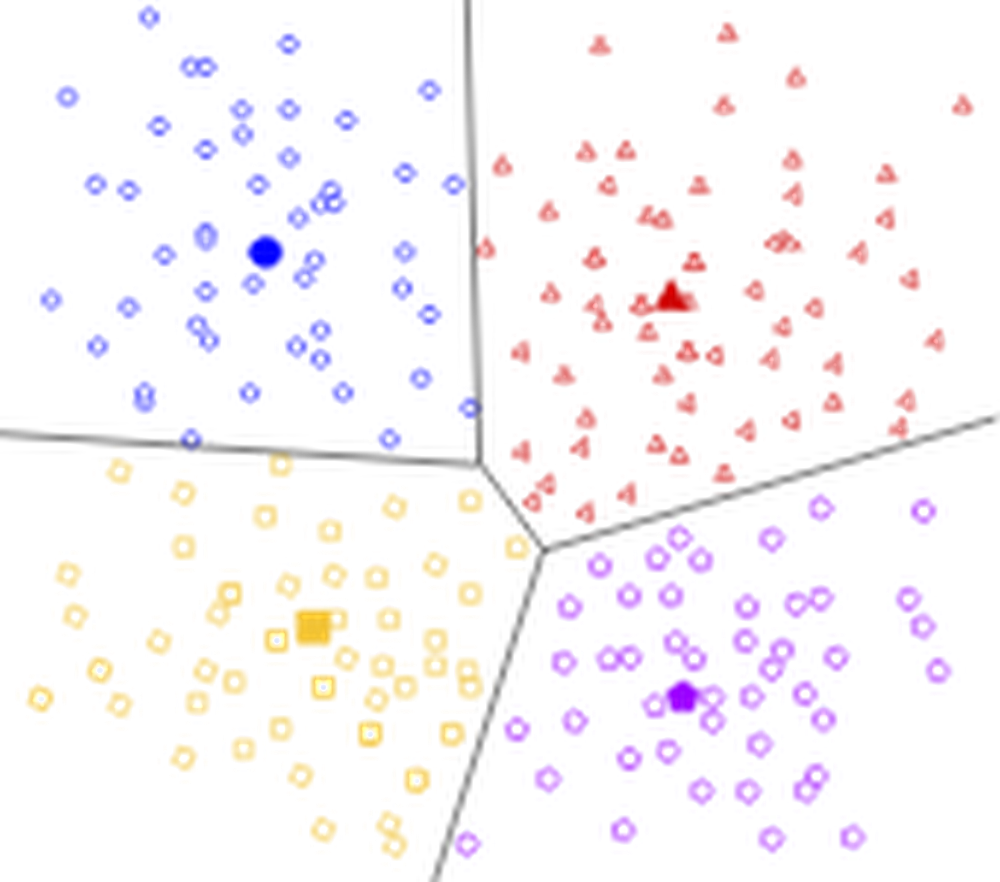
The resulting cluster set is sanity-checked by some basic heuristic measures, such a silhouette score, and then rejoined with the initial ticket data for analysis. Moreover, for privacy purposes, each cluster whose ticket cohort size falls below a predefined threshold is omitted from the data set; this ensures that cluster metadata in the output, such as feature data used to characterize the cluster, cannot be traced with high confidence back to individual tickets.
Scoring & Anomaly Detection
Once a cluster has been identified, we need a way to automatically estimate how likely it is that the cluster has recently undergone a state change which might indicate an incipient event, as opposed to remaining in a steady state. “Anomalous” clusters — i.e. those which exhibit a sufficiently high likelihood of an event — can be flagged for later operational investigation, while the rest can be disregarded.
Modeling a cluster’s behavior over time is done by distributing its tickets into a histogram according to their time of creation — using 24-hour buckets, reflecting the daily business cycle — and fitting a zero-inflated Poisson regression to the bucket counts using statsmodel1. However, our goal is not just to characterize a cluster’s state, but to detect a discrete change in that state. This is accomplished by developing two models of the same cluster: one of its long-term behavior, and the other of its short-term behavior. The distinction between “long-term” and “short-term” can be as simple as partitioning the histogram’s buckets at some age threshold. But we chose a slightly more nuanced approach: both models are fitted to the entire histogram, but under two different weighting schemata; both decay exponentially by age, but at different rates, so that recent buckets are weighted relatively more heavily in the short-term model than the long-term one.
Both models are “optimized,” in that each achieves the maximum log-likelihood in its respective context. But if the long-term model is evaluated in the short-term context instead, its log-likelihood will show some amount of loss relative to the maximum achieved by the short-term model in the same context. This loss reflects the degree to which the long-term model fails to accurately predict the cluster’s short-term behavior — in other words, the degree to which the cluster’s short-term behavior deviates from the expectation established by its short-term behavior — and thus we refer to it as the deviation score. This score serves as our key measure of anomaly; if it surpasses a defined threshold, the cluster is deemed anomalous.
Operationalize
Using the IssueTracker API, bugs are auto-generated each time an anomalous cluster is detected. These bugs contain some summary of the tokens found within the cluster itself as well as a parameterized link to the DataStudio dashboard. These dashboards show the size of the cluster over time, the deviation score and the underlying tickets.
These bugs are picked up by Techstop operations engineers and investigated to determine the root causes, allowing for quicker boots on the ground for any outages that may be occurring, as well as a more harmonious flow of data between support operations and change and incident management teams.
Staying within the IssueTracker product, operations engineers create Problem Records in a separate queue detailing the problem, stakeholders and any solution content. These problem records are shared widely with frontline operations to help address any ongoing issues or outages.
However, the secret sauce does not stop there. Techstop then uses Google’s Cloud AutoML engine to train a supervised model to classify any incoming support requests against known Problem Records (IssueTracker bugs). This model acts as a service for two critical functions:
The model is called by our Chrome extension (see this handy guide) to recommend Problem Records to frontline techs based on the current ongoing chat. For a company like Google that has a global IT team, this recommendation engine allows for coverage and visibility of issues in near real time
The model answers the “how big” question: Many stakeholders want to know how big the problem was, how many end users did this problem affect and so on. By training an AutoML model we can now give good estimators about impact and more importantly we can measure impact of project work that addresses these problems.
Resampling & User Journey Mapping
Going beyond incident response, we then semi-automatically extracts user journeys from these trends by sampling each cluster to discover the proportion of user intents. These intents are then used to map user pitfalls and generate a sense of topic for each emerging cluster.
Since operations are constrained by tech evaluation time, a solution to limit the number of reviews necessary that each agent would need to inspect, while still maintaining the accuracy of analysis, was derived.
User intents are defined as user “Goals” an employee may have when engaging with IT support. For example, “I want my cell phone to boot” or “I lost access to an internal tool” are good examples. Therefore, we propose a two-step procedure (to be applied for each cluster).
First, we sample chats until the probability that we discover a new intent is small (say <5% or whatever number we want). We can evaluate this probability at each step through the Good-Turing method.
A simple Good-Turing estimate of this probability can be found as E(1) / N, where N is the number of sampled chats so far and E(1) is approximately the number of intents that have only been seen once so far. This number should be lightly smoothed for better accuracy; it’s easy to implement this smoothing on our own2 or call a library.Once we have finished, we take the intents that we consider representative (say there are k of them) and create one additional category for “other intents.” Then, we estimate the sample size for multinomial estimation (with k+1 categories) that we still need to reach, given composition accuracy (say, that each intent fraction is within e.g., 0.1 or 0.2 of the actual fraction). To do so, we consider Thompson’s procedure3, but take advantage of the data collected so far to be used as a plugin estimate for the possible values of the parameters, plus we should also consider a grid of parameter values within a confidence interval of the current plugin estimate, to be sufficiently conservative. The procedure is described on page 43 in this article, steps (1) and (2). The procedure is easy to implement and under our current setup, it will be a few lines of code.
The procedure gives us the target sample size. If we have already reached this sample size in step 1, we are done. Otherwise, we sample a few more chats to reach this sample size.
This work along with the AutoML model allows Google to understand not only the problem impact size, but also key information about user experiences and where the CUJ users are struggling the most. In many cases a problem record will contain multiple CUJs (user intents) with separate personas and root causes.
Helping the business
Once we can make good estimators for different user goals we can work with domain experts to map clear user journeys, i.e., we can now use the data that this pipeline has generated to construct a user journey in a bottoms-up approach. This same amount of work, sifting through data, aggregating similar cases and estimating proportions of user goals would take an entire team of engineers and case scrubbers. With this ML solution we can now get the same (if not better) results with much lower operational costs.
These user journeys then can be fed to internal dashboards for key decision makers to understand the health of their products and service areas. It allows for automated incident management and acts as a safeguard against unplanned changes or user-affecting changes that did not go through the proper change management processes.
Furthermore, it is critical for problem management and other core functions within our IT service. By having a small team of operational engineers reviewing the output of this ML pipeline, we can create healthy problem records and keep track of our team’s top user issues.
How do I do this too?
Want to make your own system for insights into your support pipeline? Here’s a recipe to follow that will help you build all the parts you need
Load your data into BigQuery – Cloud BigQuery
Vectorize it with TF-IDF – TensorFlow Vectorizer
Perform clustering – TensorFlow Clustering
Score Clusters – Statsmodels Poisson Regression
Automate with Dataflow – Cloud DataFlow
Operationalize – IssueTracker API
1. When modeling a cluster, that cluster’s histogram serves as the regression’s endogenous variable. Additionally, the analogous histogram of the entire ticket set, across all clusters, serves as an exogenous variable. The latter histogram captures the overall ebb and flow in ticket generation rates due to cluster-agnostic business cycles (e.g. rates tend to be higher on weekdays than weekends), and its inclusion mitigates the impact of such cycles on each cluster’s individual model.
2. Gale, William A., and Geoffrey Sampson. “Good‐turing frequency estimation without tears.” Journal of quantitative linguistics 2.3 (1995): 217-237.
3. Thompson, Steven K. “Sample size for estimating multinomial proportions.” The American Statistician 41.1 (1987): 42-46.