
Master data is a holistic view of your key business entities, providing a consistent set of identifiers and attributes that give context to the business data that matters most to your organization. It’s about ensuring that clean, accurate, curated data – the best available – is accessible throughout the company to manage operations and make critical business decisions. Having well-defined master data is essential to running your business operations.
Master data undergoes a far more enriched and refined process than other types of data captured across the organization. For instance, it’s not the same as the transactional data generated by applications. Instead, master data gives context to the transaction itself by providing the fundamental business objects – like the Customer, Product, Patient, or Supplier – on which the transactions are performed.
Without master data, enterprise applications are left with potentially inconsistent data living in disparate systems; with an unclear picture of whether multiple records are related. And without it, gaining essential business insight may be difficult, if not impossible, to attain: for example, “which customers generate the most revenue?” or “which suppliers do we do the most business with?”
Master data is a critical element of treating data as an enterprise asset and as a product.. A data product strategy requires that the data remain clean, integrated, and freshly updated with appropriate frequency. Without this additional preparation and enrichment, data becomes stale and incomplete, leading to inability to provide the necessary insights for timely business decisions. Data preparation, consolidation and enrichment should be a part of a data product strategy, since consolidating a complete set of external data sources will provide more complete and accurate insights for business decisions. This data preparation, consolidation and enrichment requires the right infrastructure, tools, and processes, otherwise it will be an additional burden on already thinly stretched data management teams. .
This is why it is necessary to adopt and implement a next-generation master data management platform that enables a data product strategy to be operationalized. This in turn enables the acquisition of trusted records to drive business outcomes.
The Challenge: A Single Source of Truth – The Unified “Golden” Record
Many companies have built or are working on rolling out data lakes, lake houses, data marts, or data warehouses to address data integration challenges. However, when multiple data sets from disparate sources are combined, there is a high likelihood of introducing problems , which Tamr and Google Cloud are partnering to address and alleviate:
Data duplication: same semantic/physical entity like customer with different keys
Inconsistency: same entity having partial and/or mismatching properties (like different phone numbers or addresses for the same customers)
Reduced insight accuracy: duplicates skew the analytic key figures (like total distinct customers are higher with duplicates than without them)
Timeliness impact: manual efforts to reach a consistent and rationalized core set of data entities used for application input and analytics cause significant delays in processing and ultimately, decision making
Solution
Tamr is the leader in data mastering and next-generation master data management, delivering data products that provide clean, consolidated, and curated data to help businesses stay ahead in a rapidly changing world. Organizations benefit from Tamr’s integrated, turn-key solution that combines machine learning with humans-in-the-loop, a low-code/no-code environment, and integrated data enrichment to streamline operations. The outcome is higher quality data; faster and with less manual work
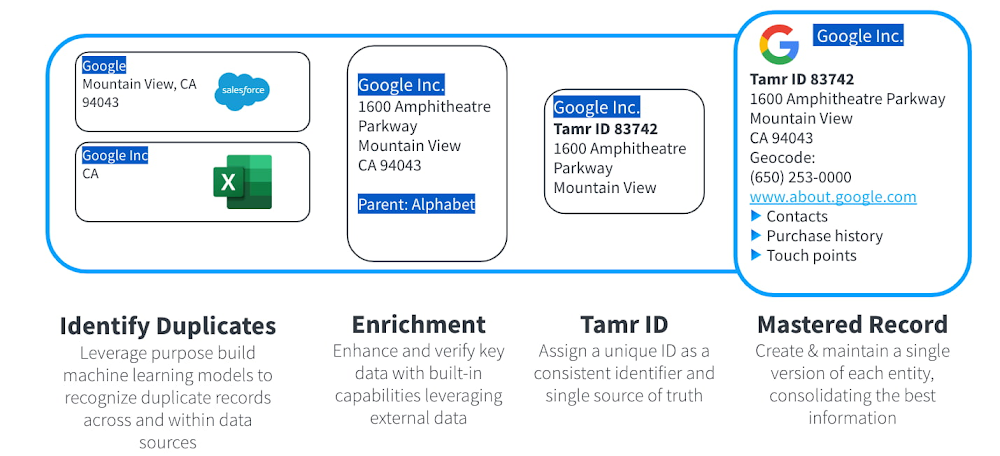
Tamr takes multiple source records, identifies duplicates, enriches data, assigns a unique ID, and provides a unified, mastered “golden record” while maintaining all source information for analysis and review. Once cleansed, data can be utilized in the downstream analytics and applications, enabling more informed decisions.
A successful data product strategy requires consistently cleaning and integrating data, a task that’s ideal for data mastering. machine-learning based capabilities in a data mastering platform can handle increases in data volume and variety, as well as data enrichment to ensure that the data stays fresh and accurate so it can be trusted by the business consumers.
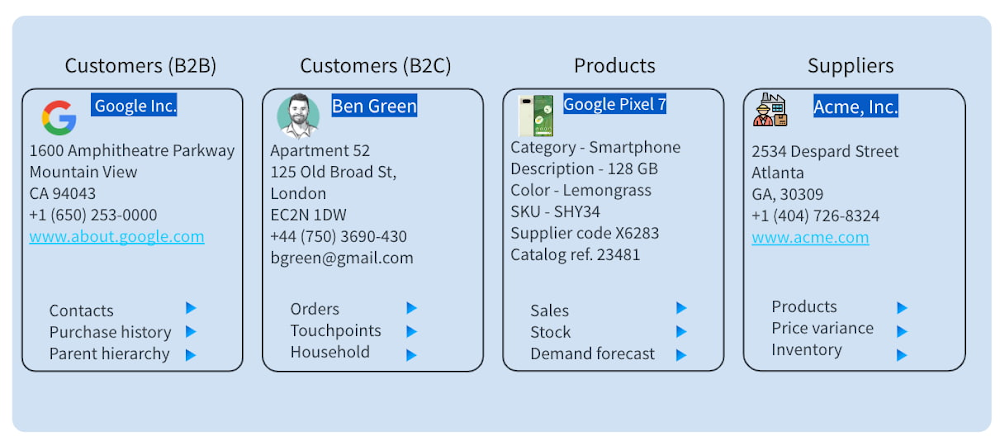
With accurate key entity data, companies can unlock the bigger picture of data insights. The term “key” signifies entities that are most important to an organization. For example, for healthcare organizations, this could mean patients and providers; for manufacturers, it could mean suppliers; for financial services firms, it could mean customers.
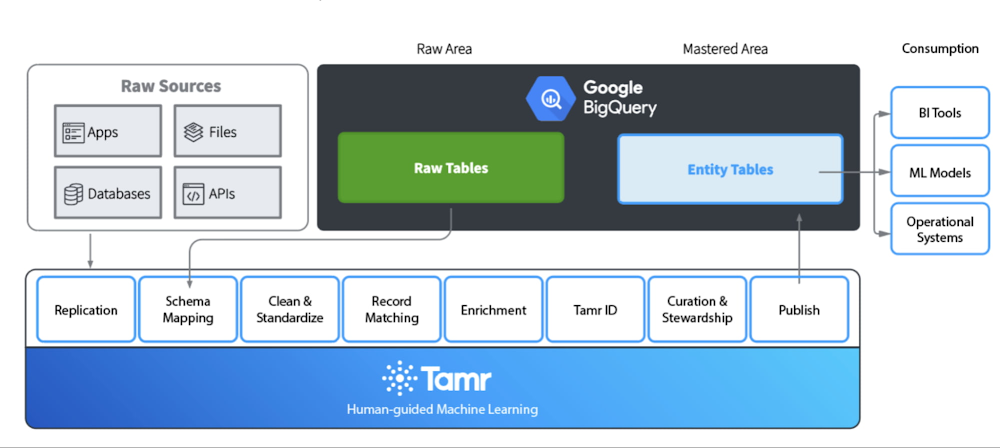
Below are examples of key business entities after they’ve been cleaned, enriched, and curated with Tamr:
Better Together: How Tamr leverages Google Cloud to differentiate their next-gen MDM
Tamr Mastering, a template-based SaaS MDM solution, is built on Google Cloud Platform technologies such as Cloud Dataproc, Cloud Bigtable and BigQuery, allowing customers to scale modern data pipelines with excellent performance while controlling costs.
The control plane (application layer) is built on Google Compute Engine (GCE) to leverage its scalability. The data plane utilizes a full suite of interconnected Google Cloud Platform services such as Google Dataproc for distributed processing, allowing for a flexible and sustainable way to bridge the gap between the analytics powers of distributed TensorFlow and the scaling capabilities of Hadoop in a managed offering. Google Cloud Storage is used for data movement/staging.
Google Cloud Run, which enables Tamr to deploy containers directly on top of Google’s scalable infrastructure, is used in the data enrichment process. This approach allows serverless deployments without the need to create a stateful cluster or manage infrastructure to be productive with container deployments. Google Bigtable is utilized for data-scale storage, allowing for high throughput and scalability for key/value data. Data that doesn’t fall into the key/value lookup schema is retrieved in batches or used for analytical purposes. Google BigQuery is the ideal storage for this type of data and storage of the golden copy of the data discussed earlier in this blog post. Additionally, Tamr chose BigQuery as their central data storage solution due to the ability of BigQuery to promote schema denormalization with the native support of nested and repeated fields to denormalize data storage and increase query performance.
On top of that, Tamr Mastering utilizes Cloud IAM for access control, authn/authz, configuration and observability. Deploying across the Google framework provides key advantages such as better performance due to higher bandwidth, lower management overhead, and autoscaling and resource adjustment, among other value drivers, all resulting in lower TCO.
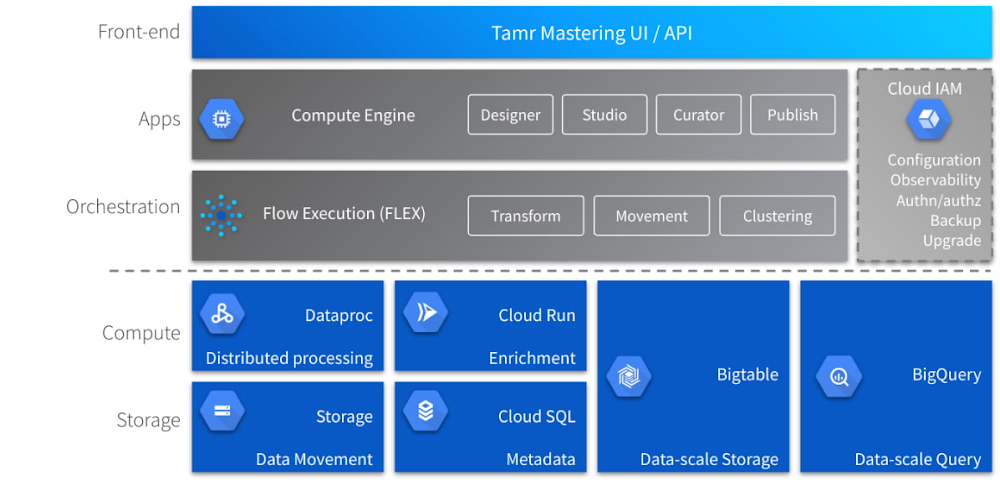
The architecture above illustrates the different layers of functionality. Starting from the top down with the front-end deployment to the core layers at the borrow of the diagram. To scale the overall MDM architecture depicted in the above diagram, efficiently, Tamr has partnered with Google Cloud to focus on three core capabilities:
Capability One: Machine learning optimized for scale and accuracy
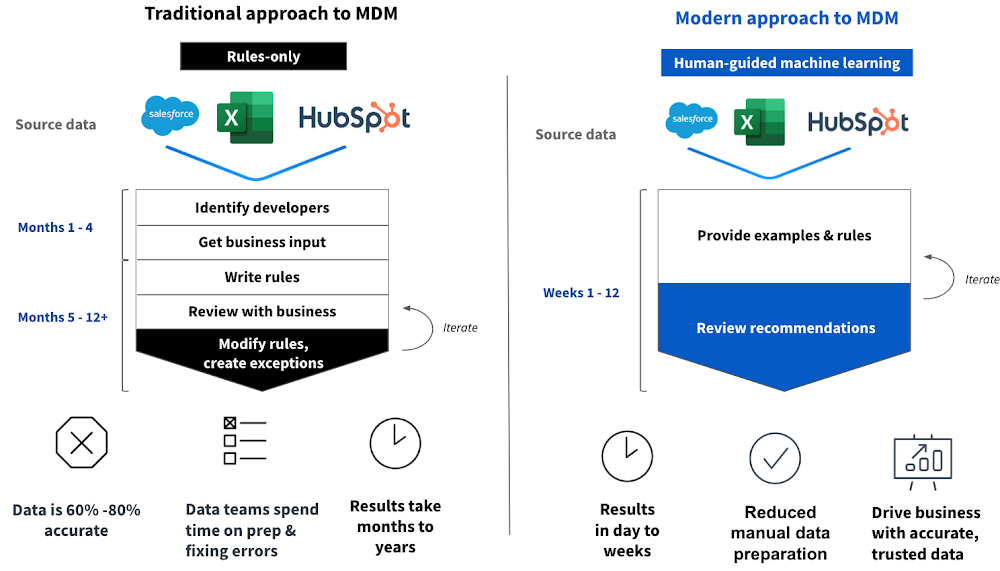
Traditionally, organizing and mastering data in most organizations’ legacy infrastructure has been done using a rules-based approach (if <condition> then <action>). Conventional rules-based systems can be effective on a small scale, relying on human-built logic implemented in the rules to generate master records. However, such rules fail to scale when tasked with connecting and reconciling large amounts of highly variable data.
Machine learning, on the other hand, becomes more efficient at matching records across datasets as more data is added. In fact, huge amounts of data (more than 1 million records across dozens of systems) provide more signal, so the machine learning models are able to identify patterns, matches, and relationships, accelerating years of human effort down to days. Google’s high performance per core on Compute Engine, high network throughput and lower provisioning times across both storage and compute are all differentiating factors in Tamr’s optimized machine learning architecture on Google Cloud.
Capability Two: Ensure there is sufficient human input
While machine learning is critical, so is keeping humans in the loop and letting them provide feedback. Engaging business users and subject matter experts is key to building trust in the data. A middle ground where machines take the lead and humans provide guidance and feedback to make the machine – and the results – better is the data mastering approach that delivers the best outcomes. Not only will human input improve machine learning models, but it will also foster tighter alignment between the data and business outcomes that require curated data.
Capability Three: Enrichment built in the workflow
As a final step in the process, data enrichment integrates internal data assets with external data to increase the value of these assets. It adds additional relevant or missing information so that the data is more complete – and thus more usable. Enriching data improves its quality, making it a more valuable asset to an organization. Combining data enrichment with data mastering means that not only are data sources automatically cleaned, they are also enhanced with valuable commercial information while avoiding the incredibly time-consuming and manual work that goes into consolidating or stitching internal data with external data.
Below is an example of how these three core-capabilities are incorporated into the Tamr MDM architecture:
Building the data foundation for connected customer experiences at P360
When a major pharmaceutical company approached P360 for help with a digital transformation project aimed at better reaching the medical providers they count as customers, P360 realized that building a solid data foundation with a modern master data management (MDM) solution was the first step.
“One of the customer’s challenges was master data management, which was the core component of rebuilding their data infrastructure. Everything revolves around data so not having a solid data infrastructure is a non-starter. Without it, you can’t compete, you can’t understand your customers and how they use your products,” said Anupam Nandwana, CEO of P360, a technology solutions provider for the pharmaceutical industry.
To develop that foundation of trusted data, P360 turned to Tamr Mastering. By using Tamr Mastering, the pharmaceutical company is quickly unifying internal and external data on millions of health care providers to create golden records that power downstream applications, including a new CRM system. Like other business-to-business companies, P360’s customer has diverse and expansive data from a variety of sources. From internal data like physician names and addresses to external data like prescription histories and claims information, this top pharmaceutical company has 150 data sources to master in order to get complete views of their customers. This includes records on 1 million healthcare providers (as well as 2 million provider addresses) and records on the more than 100,000 healthcare organizations.
“For the modern data platform, cloud is the only answer. To provide the scale, flexibility and speed that’s needed, it’s just not pragmatic to leverage other infrastructure. The cloud gives us the opportunity to do things faster. Completing this project in a short amount of time was a key criteria for success and that would have only been possible with the cloud. Using it was an easy decision,” Nandwana said.
With Tamr Mastering, P360 helped their customer master millions of provider records in weeks and create golden records containing unique customer IDs as a consistent identifier and single source of truth.
Conclusion
Google’s data cloud provides a complete platform for building data-driven applications like Tamr’s MDM solution on Google Cloud. Simplified data ingestion, processing, and storage to powerful analytics, AI, ML, and data sharing capabilities are integrated with the open, secure, and sustainable Google Cloud platform. With a diverse partner ecosystem, open-source tools, and APIs, Google Cloud can provide technology companies with a platform that provides the portability and differentiators they need to build their products and serve the next generation of customers.
Learn more about Tamr on Google Cloud.
Learn more about Google Cloud’s Built with BigQuery initiative.
We thank the Google Cloud team member who co-authored the blog: Christian Williams, Principal Architect, Cloud Partner Engineering