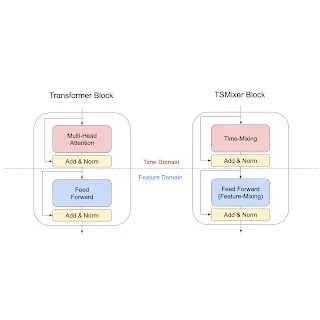
TSMixer: An all-MLP architecture for time series forecasting
Posted by Si-An Chen, Student Researcher, Cloud AI Team, and Chun-Liang Li, Research Scientist, Cloud AI Team Time series forecasting is critical to various real-world applications, from demand forecasting to pandemic spread prediction. In multivariate time series forecasting (forecasting multiple variants at the same time), one can split existing methods into two categories: univariate models …
Read more “TSMixer: An all-MLP architecture for time series forecasting”