As one of the most innate and ubiquitous forms of expression, speech is a fundamental pillar of human interaction. It comes as no surprise, then, that Google Cloud’s Speech API has become a crucial tool for enterprise customers, launched to general availability (GA) over six years ago and, now, processing over 1 billion voice minutes each month.
With the Speech API, we’ve been pleased to serve thousands of customers and provide industry-leading speech recognition quality and cost-effective products across a range of industries. We want to constantly evolve our offerings and bring new benefits to organizations, which is why today, we’re excited to announce the GA release of our new Speech-to-Text v2 API.
Speech-to-Text v2 modernizes our API interface and introduces several new features. It also migrates all of our existing functionality, so you can use the same models and features that you were using in STT v1 or v1p1beta1 APIs. This new version of our API also allows us to take advantage of significant cost savings in our serving path, and as such we are reducing our base price, as well as adding pricing incentives for large workloads and those willing to accept longer turnaround times.
This new infrastructure also allows us to serve a wide variety of new types of models, including Chirp , our latest 2B-parameter large speech model. All of these are Generally Available to Google Cloud Platform customers and users starting today.
Let’s have a more thorough look though at the enhanced features of Speech-to-Text API V2 and illustrate how your business can benefit from our new capabilities:
Expanding Speech-to-Text features with V2 API
Since the official launch of Speech-to-Text API back in 2017, we’ve utilized Google’s global infrastructure to host and monitor our production-facing transcription models. This robust, well-connected network has been the backbone of our offering for all of our customers.
However, a unified view of our Speech-to-Text service has been a crucial request for our enterprise customers who need to satisfy data residency and compliance requirements, especially in regulated industries like banking and public sector. We listened carefully to this feedback, and starting today, our Speech-to-Text v2 API supports full regionalization, allowing our customers to invoke identical copies of all our transcription models in the Google Cloud Platform region of their choice.
In addition to giving users the flexibility to deploy in any region, we are adding a number of new features to help developers build on the API:
Recognizers: A user-defined named configuration that combines a model identifier, the language-locale of the audio to be transcribed, and the cloud region for the transcription model to run. Once-created, the recognizer can be referenced to every subsequent transcription request, eliminating the need for users to repeatedly define the same configuration parameters. This resourceful implementation of recognizers allows for greater flexibility in authentication and authorization, as users are not longer required to set up dedicated service accounts.
Cloud Logging: Requests performed using a recognizer object automatically support cloud logging by default. Since the recognizers are defined as named entities, customers can partition traffic based on the recognizer of interest or collectively.
Audio Format Auto-Detection: Instead of having our users analyze and manually define the audio configuration settings to pass in a transcription request, the new Speech-to-Text V2 API detects settings like encoding, sampling rate, and channel count, then automatically populates the request configuration parameters.
Increasing accuracy at Enterprise Scale with Chirp
As part of our continuous investment in foundational speech models, in March 2023 we released research results for our Universal Speech Mode (USM), a family of state-of-the-art speech models with 2B parameters and support for transcriptions of 300+ languages. In May 2023, at Google I/O, we announced Chirp in Private Preview, the latest version of the USM family, fine-tuned for our Cloud-specific use-cases.
Chirp is now GA through the Speech-to-Text v2 API. Following extensive testing and feedback from our customers, we are making the power of pre-trained large models accessible through a simple enterprise-grade API surface. Our early adopters have seen major strides in customer engagement, thanks to the market-leading accuracy and language coverage of the new model, and we cannot wait to see what opportunities our enterprise customers will unlock.
Introducing new pricing, tiers, and options
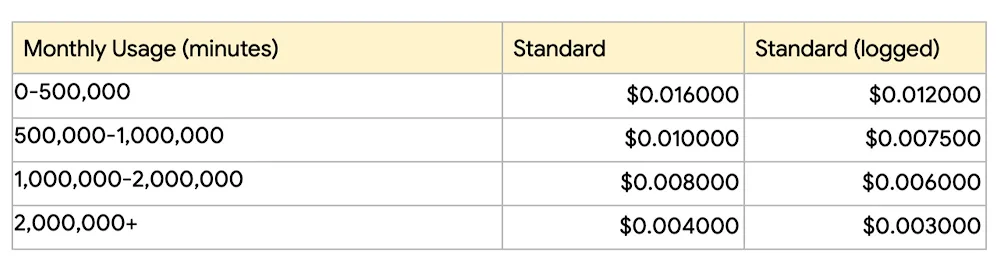
We have heard from customers that price can be just as important as quality for many workloads. That’s why the Speech-to-Text API v2 features totally new pricing. We have lowered the cost of real-time and batch transcription from $0.024 per minute to $0.016 per minute. Additionally, we know that pricing can be a concern for those that have very large transcription workloads. For that reason, we are also introducing standard volume tiers, allowing costs as low as $0.004 per minute. As always, additional discounts are available to those with even larger workloads.
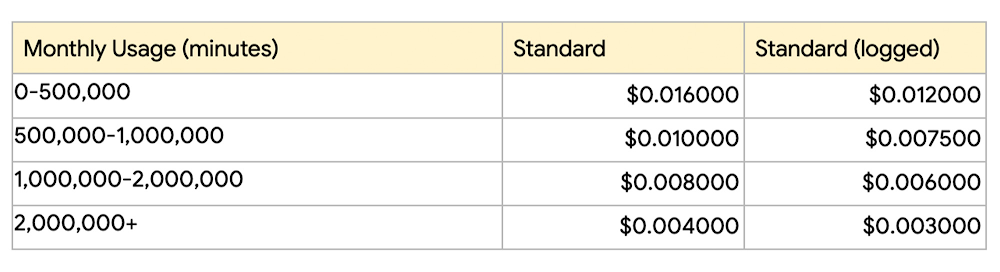
Staying true to our commitment on flexibility and choice in pricing, we noticed that even though the majority of our customers are interested in our models for real-time transcription scenarios, many are also interested in non-real time transcriptions for data at rest. With our new API v2 infrastructure, we can take greater advantage of capacity that goes unused at certain times. With our new Dynamic Batch pricing, we are passing this savings on to customers that are less latency sensitive. Aimed at users who can wait up to 24 hours for transcription results, Dynamic Batch is a new discounted pricing tier that offers 75% lower price per minute for transcription audio relative to our Standard tier.

For more information on Dynamic Batch and all our new STT v2 API pricing, check out our pricing page.
Learn more and start you Speech-to-Text journey
For more information to help get you started on your migration journey from V1 to V2, head over to the detailed documentation and try our walkthroughs to make the most of regionalization and recognizers.
If you are curious to learn more about how to use Chirp, you can get started by following our tutorial. You can also read more about how we built it in our research blog post.
We are very excited to bring all these improvements to our developer ecosystem and provide you with the tools to leverage the power of voice for your businesses, programs, and applications.