Batch inference is a common pattern where prediction requests are batched together on input, a job runs to process those requests against a trained model, and the output includes batch prediction responses that can then be consumed by other applications or business functions. Running batch use cases in production environments requires a repeatable process for model retraining as well as batch inference. That process should also include monitoring that model to measure performance over time.
In this post, we show how to create repeatable pipelines for your batch use cases using Amazon SageMaker Pipelines, Amazon SageMaker model registry, SageMaker batch transform jobs, and Amazon SageMaker Model Monitor. This solution highlights the ability to use the fully managed features within SageMaker MLOps to reduce operational overhead through fully managed and integrated capabilities.
Solution overview
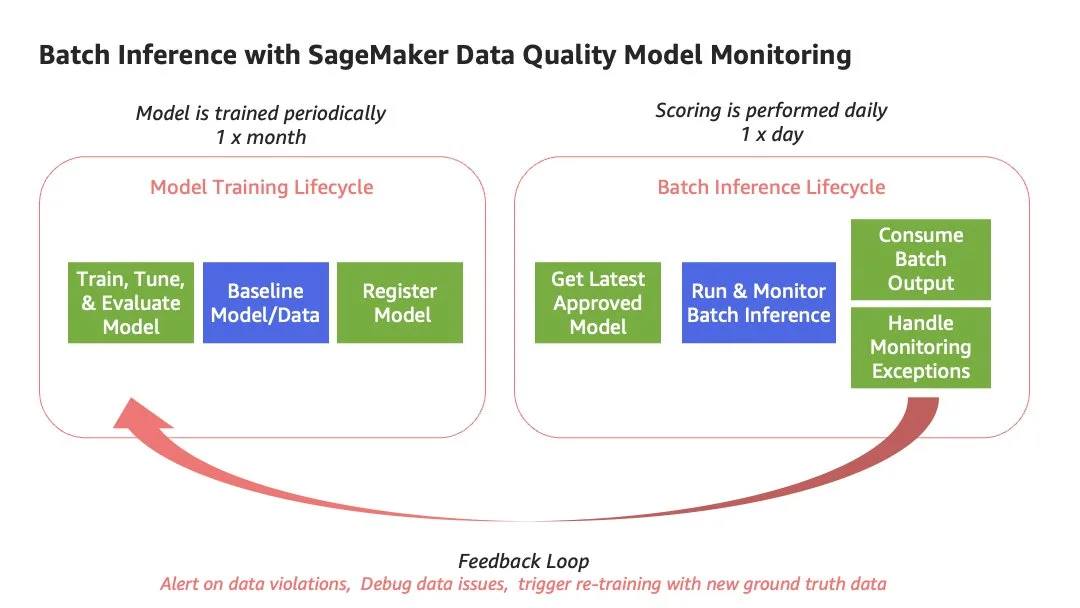
There are multiple scenarios for performing batch inference. In some cases, you may be retraining your model every time you run batch inference. Alternatively, you may be training your model less frequently than you are performing batch inference. In this post, we focus on the second scenario. For this example, let’s assume you have a model that is trained periodically, roughly one time per month. However, batch inference is performed against the latest model version on a daily basis. This is a common scenario, in which the model training lifecycle is different than the batch inference lifecycle.
The architecture supporting the introduced batch scenario contains two separate SageMaker pipelines, as shown in the following diagram.

We use the first pipeline to train the model and baseline the training data. We use the generated baseline for ongoing monitoring in the second pipeline. The first pipeline includes the steps needed to prepare data, train the model, and evaluate the performance of the model. If the model performs acceptably according to the evaluation criteria, the pipeline continues with a step to baseline the data using a built-in SageMaker Pipelines step. For the data drift Model Monitor type, the baselining step uses a SageMaker managed container image to generate statistics and constraints based on your training data. This baseline is then used to monitor for signals of data drift during batch inference. Finally, the first pipeline completes when a new model version is registered into the SageMaker model registry. At this point, the model can be approved automatically, or a secondary manual approval can be required based on a peer review of model performance and any other identified criteria.
In the second pipeline, the first step queries the model registry for the latest approved model version and runs the data monitoring job, which compares the data baseline generated from the first pipeline with the current input data. The final step in the pipeline is performing batch inference against the latest approved model.
The following diagram illustrates the solution architecture for each pipeline.

For our dataset, we use a synthetic dataset from a telecommunications mobile phone carrier. This sample dataset contains 5,000 records, where each record uses 21 attributes to describe the customer profile. The last attribute, Churn, is the attribute that we want the ML model to predict. The target attribute is binary, meaning the model predicts the output as one of two categories (True or False).
The following GitHub repo contains the code for demonstrating the steps performed in each pipeline. It contains three notebooks: to perform the initial setup, to create the model train and baseline pipeline, and create the batch inference and Model Monitor pipeline. The repository also includes additional Python source code with helper functions, used in the setup notebook, to set up required permissions.
Prerequisites
The following screenshot lists some permission policies that are required by the SageMaker execution role for the workflow. You can enable these permission policies through AWS Identity and Access Management (IAM) role permissions.

AmazonSageMaker-ExecutionPolicy-<...> is the execution role associated with the SageMaker user and has the necessary Amazon Simple Storage Service (Amazon S3) bucket policies. Custom_IAM_roles_policy and Custom_Lambda_policy are two custom policies created to support the required actions for the AWS Lambda function. To add the two custom policies, go to the appropriate role (associated with your SageMaker user) in IAM, click on Add permissions and then Create inline policy. Then, choose JSON inside Create policy, add the policy code for first custom policy and save the policy. Repeat the same for the second custom policy.
0.Setup.ipynb is a prerequisite notebook required before running notebooks 1 and 2. The code sets up the S3 paths for pipeline inputs, outputs, and model artifacts, and uploads scripts used within the pipeline steps. This notebook also uses one of the provided helper functions, create_lambda_role, to create a Lambda role that is used in notebook 2, 2.SageMakerPipeline-ModelMonitoring-DataQuality-BatchTransform.ipynb. See the following code:
After you’ve successfully completed all of the tasks in the setup notebook, you’re ready to build the first pipeline to train and baseline the model.
Pipeline 1: Train and baseline pipeline
In this section, we take a deep dive into the SageMaker pipeline used to train and baseline the model. The necessary steps and code are in the 1.SageMakerPipeline-BaselineData-Train.ipynb notebook. This pipeline takes the raw customer churn data as input, and then performs the steps required to prepare the data, train the model, evaluate the model, baseline the model, and register the model in the model registry.

To build a SageMaker pipeline, you configure the underlying job (such as SageMaker Processing), configure the pipeline steps to run the job, and then configure and run the pipeline. We complete the following steps:
- Configure the model build pipeline to prepare the data, train the model, and evaluate the model.
- Configure the baseline step for the data drift with Model Monitor.
- Configure steps to package the model and register the model version.
- Configure a conditional step to evaluate model performance.
Configure the model build pipeline
The model build pipeline is a three-step process:
- Prepare the data.
- Train the model.
- Evaluate the model.

To prepare the data, we configure a data processing step. This step runs a SageMaker Processing job, using the built-in ProcessingStep, to prepare the raw data on input for training and evaluation.
To train the model, we configure a training job step. This step runs a SageMaker Training job, using the built-in TrainingStep. For this use case, we perform binary classification using XGBoost. The output of this step is a model artifact, model.tar.gz, stored in Amazon S3.
The last step is responsible for evaluating model performance using the test holdout dataset. This step uses the built-in ProcessingStep with the provided code, evaluation.py, to evaluate performance metrics (accuracy, area under curve).
Configure the baseline step
To monitor the model and data, a baseline is required.

Monitoring for data drift requires a baseline of training data. The baseline step uses Pipelines’ built-in QualityCheckStep. This step automatically runs a SageMaker Processing job that uses the Model Monitor pre-built container image. We use this same container image for the baselining as well as the model monitoring; however, the parameters used during configuration of this step direct the appropriate behavior. In this case, we are baselining the data, so we need to ensure that the quality_check_config parameter is using DataQualityCheckConfig, which identifies the S3 input and output paths. We’re also setting register_new_baseline and skip_check to true. When these values are both set to true, it tells SageMaker to run this step as a baseline job and create a new baseline. To get a better understanding of the parameters that control the behavior of the SageMaker pre-built container image, refer to Baseline calculation, drift detection and lifecycle with ClarifyCheck and QualityCheck steps in Amazon SageMaker Model Building Pipelines.
See the following code:
This step generates two JSON files as output:
- statistics.json – Contains calculated statistics for each feature of the training dataset
- constraints.json – Suggests data constraints based on the statistics collected
These constraints can also be modified and are used to detect signals of drift during model monitoring.
Configure steps to package and register the model version
Next, we configure the steps to package for deployment and register the model in the model registry using two additional pipeline steps.

The package model step packages the model for use with the SageMaker batch transform deployment option. model.create() creates a model entity, which will be included in the custom metadata registered for this model version and later used in the second pipeline for batch inference and model monitoring. See the following code:
The register model step registers the model version and associated metadata to the SageMaker model registry. This includes model performance metrics as well as metadata for the data drift baseline, including the Amazon S3 locations of the statistics and constraints files produced through the baselining step. You’ll also notice the additional custom metadata noted customer_metadata_properties pulling the model entity information that will be used later in the inference pipeline. The ability to provide custom metadata within the model registry is a great way to incorporate additional metadata that should be collected that isn’t explicitly defined in native SageMaker parameters. See the following code:
Configure a conditional step to evaluate model performance
The conditional step, ConditionStep, compares model accuracy against an identified threshold and checks the quality of the trained model.

It reads the evaluation.json file and checks if the model accuracy, or whatever objective metric you are optimizing for, meets the criteria you’ve defined. In this case, the criteria is defined using one of the built-in conditions, ConditionGreaterThanOrEqualTo. If the condition is satisfied, the pipeline continues to baseline the data and perform subsequent steps in the pipeline. The pipeline stops if the condition is not met. Because the condition explicitly calls out the next steps in the pipeline, we have to ensure those steps are configured prior to configuring our conditional step. See the following code:
Define, create, and start the SageMaker pipeline
At this point, all the steps of the train and baseline pipeline are defined and configured. Now it’s time to define, create, and start the pipeline.

First, we define the pipeline, Pipeline(), providing a pipeline name and a list of steps previously configured to include in the pipeline. Next, we create the pipeline using training_pipeline.upsert(). Finally, we start the pipeline using training_pipeline.start(). See the following code:
When the pipeline starts running, you can visualize its status on Studio. The following diagram shows which steps from the pipeline process relate to the steps of the pipeline directed acyclic graph (DAG). After the train and baseline pipeline run successfully, it registers the trained model as part of the model group in the model registry. The pipeline is currently set up to register the model in a Pending state, which requires a manual approval. Optionally, you can configure the model registration step to automatically approve the model in the model registry. The second pipeline will pull the latest approved model from the registry for inference.

In Studio, you can choose any step to see its key metadata. As an example, the data quality check step (baseline step) within the pipeline DAG shows the S3 output locations of statistics.json and constraints.json in the Reports section. These are key files calculated from raw data used as a baseline.

After the pipeline has run, the baseline (statistics and constraints) for data quality monitoring can be inspected, as shown in the following screenshots.


Pipeline 2: Batch inference and Model Monitor pipeline
In this section, we dive into the second pipeline used for monitoring the new batch input data for signals of data drift and running batch inference using SageMaker Pipelines. The necessary steps and code are within 2.SageMakerPipeline-ModelMonitoring-DataQuality-BatchTransform.ipynb. This pipeline includes the following steps:
- A Lambda step to retrieve the latest approved model version and associated metadata from the model registry.
- A Model Monitor step to detect signals of data drift using the new input data and the baseline from Pipeline 1.
- A batch transform step to process the batch input data against the latest approved model.

Configure a Lambda Step
Before we start the model monitoring and batch transform job, we need to query the model registry to get the latest approved model that we will use for batch inference.

To do this, we use a Lambda step, which allows us to include custom logic within our pipeline. The lambda_getapproved_model.py Lambda function queries the SageMaker model registry for a specific model package group provided on input to identify the latest approved model version and return related metadata. The output includes metadata created from our first pipeline:
- Model package ARN
- Packaged model name
- S3 URI for statistics baseline
- S3 URI for constraints baseline
The output is then used as input in the next step in the pipeline, which performs batch monitoring and scoring using the latest approved model.
To create and run the Lambda function as part of the SageMaker pipeline, we need to add the function as a LambdaStep in the pipeline:
Configure the data monitor and batch transform steps
After we create the Lambda step to get the latest approved model, we can create the MonitorBatchTransformStep. This native step orchestrates and manages two child tasks that are run in succession. The first task includes the Model Monitor job that runs a Processing job using a built-in container image used to monitor the batch input data and compare it against the constraints from the previously generated baseline from Pipeline 1. In addition, this step kicks off the batch transform job, which processes the input data against the latest approved model in the model registry.

This batch deployment and data quality monitoring step takes the S3 URI of the batch prediction input data on input. This is parameterized to allow for each run of the pipeline to include a new input dataset. See the following code:
Next, we need to configure the transformer for the batch transform job that will process the batch prediction requests. In the following code, we pass in the model name that was pulled from the custom metadata of the model registry, along with other required parameters:
The data quality monitor accepts the S3 URI of the baseline statistics and constraints for the latest approved model version from the model registry to run the data quality monitoring job during the pipeline run. This job compares the batch prediction input data with the baseline data to identify any violations signaling potential data drift. See the following code:
Next, we use MonitorBatchTransformStep to run and monitor the transform job. This step runs a batch transform job using the transformer object we configured and monitors the data passed to the transformer before running the job.
Optionally, you can configure the step to fail if a violation to data quality is found by setting the fail_on_violation flag to False.
See the following code:
Define, create, and start the pipeline
After we define the LambdaStep and MonitorBatchTransformStep, we can create the SageMaker pipeline.

See the following code:
We can now use the upsert() method, which will create or update the SageMaker pipeline with the configuration we specified:
Although there are multiple ways to start a SageMaker pipeline, when the pipeline has been created, we can run the pipeline using the start() method.
Note that in order for the LambdaStep to successfully retrieve an approved model, the model that was registered as part of Pipeline 1 needs to have an Approved status. This can be done in Studio or using Boto3. Refer to Update the Approval Status of a Model for more information.

To run the SageMaker pipeline on a schedule or based on an event, refer to Schedule a Pipeline with Amazon EventBridge.
Review the Model Monitor reports
Model Monitor uses a SageMaker Processing job that runs the DataQuality check using the baseline statistics and constraints. The DataQuality Processing job emits a violations report to Amazon S3 and also emits log data to Amazon CloudWatch Logs under the log group for the corresponding Processing job. Sample code for querying Amazon CloudWatch logs is provided in the notebook.

We’ve now walked you through how to create the first pipeline for model training and baselining, as well as the second pipeline for performing batch inference and model monitoring. This allows you to automate both pipelines while incorporating the different lifecycles between training and inference.
To further mature this reference pattern, you can identify a strategy for feedback loops, providing awareness and visibility of potential signals of drift across key stakeholders. At a minimum, it’s recommended to automate exception handling by filtering logs and creating alarms. These alarms may need additional analysis by a data scientist, or you can implement additional automation supporting an automatic retraining strategy using new ground truth data by integrating the model training and baselining pipeline with Amazon EventBridge. For more information, refer to Amazon EventBridge Integration.

Clean up
After you run the baseline and batch monitoring pipelines, make sure to clean up any resources that won’t be utilized, either programmatically via the SageMaker console, or through Studio. In addition, delete the data in Amazon S3, and make sure to stop any Studio notebook instances to not incur any further charges.
Conclusion
In this post, you learned how to create a solution for a batch model that is trained less frequently than batch inference is performed against that trained model using SageMaker MLOps features, including Pipelines, the model registry, and Model Monitor. To expand this solution, you could incorporate this into a custom SageMaker project that also incorporates CI/CD and automated triggers using standardized MLOps templates. To dive deeper into the solution and code shown in this demo, check out the GitHub repo. Also, refer to Amazon SageMaker for MLOps for examples related to implementing MLOps practices with SageMaker.
About the Authors
 Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at Amazon Web Services (AWS). She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.
Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at Amazon Web Services (AWS). She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.
 Sovik Kumar Nath is an AI/ML solution architect with AWS. He has experience in designs and solutions for machine learning, business analytics within financial, operational, and marketing analytics; healthcare; supply chain; and IoT. Outside work, Sovik enjoys traveling and watching movies.
Sovik Kumar Nath is an AI/ML solution architect with AWS. He has experience in designs and solutions for machine learning, business analytics within financial, operational, and marketing analytics; healthcare; supply chain; and IoT. Outside work, Sovik enjoys traveling and watching movies.
 Marc Karp is a ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is a ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.