

There is such a thing as too much data — when it becomes too overwhelming to properly figure out how to use it. Keeping track and making sense of what data your organization has, where it came from, who owns it, and how they can use it, alongside a myriad of other questions, can be a daunting task for every organization. The problems associated with these are no longer ‘nice-to-haves’ — advancing data protection regulation means that organizations around the world are expected to not only know what data points they collect and hold, but even more critically, where all of the sensitive data about their customers is.
Among the core lessons we’ve learned when enabling customers to grow their data ecosystems over time is that as operating systems scale, they start requiring the right tools to help sort through it — and often need something to bring order to what can be a chaotic environment. Palantir Foundry — our operating system for the modern enterprise — is designed to handle the very pain points associated with this scaling. As user numbers, data volume, and associated complexities all grow — data management and organization are key to enabling success.
We believe that organizations should invest in data catalogs to create an inventory of all data on a platform. This serves as a landing place to store, collect, search, surface, and analyze information available across the platform. Data catalogs provide the capability to search across all of these characteristics and help users find and appropriately use the data that they need, while simultaneously empowering data owners and administrators to tag critical information for users on how that data should be used. At Palantir, we invest in tools to provide transparency about data that is critical to enforcing data governance on the platform.
Why are data catalogs useful?
No two data catalogs are the same, but all data catalogs are designed to help bring order to ways of work. They centralize information and processes in a single ‘go-to’ resource, which can be further used to help standardize processes for better user management, instead of data and operations being bottlenecked by a centralized administrator manually quarterbacking information. Some of the reasons data catalogs are useful across an organization include:
- Information Capture — Catalogs can funnel users into one place to uniformly capture information about data both intended for the platform and update details on data already on the platform. For some organizations, before data can be ingested, preliminary information about it must be submitted and then approved before it can be brought into the platform. Other times, it is managed alongside the data being uploaded. Either way, data owners and administrators should see data catalogs as an opportunity to set up standard operating procedures (SOPs) to capture context about data before it is uploaded or shared.
- Data Inventory — Once populated, data catalogs can then become a repository of information about the data on the platform. This not only helps users know what data already exists across the organization, but also serves as a quick go-to resource to help them find the data they are looking for.
- Metadata Management — Beyond just what data is available, data catalogs can also extend to become the central source for providing further context about the data (e.g., data profiles, data quality concerns, metadata, and more). You can also read more about the importance of metadata management for data protection and trust in data.
- Data Handling Context — This includes tracking which datasets include personally identifiable information (PII), the status of approvals for data prior to it being used, data handling requirements, and appropriate use of the data. By storing this alongside the data itself, it’s much more transparent for users to know how to appropriately leverage what is available.
- Search and Discovery — Data catalogs can search across fields, including specific columns or descriptions across data. This enables users to more easily discover data and improves walk-up usability of the data (with the appropriate permissions).
What kind of information is important to capture?
The first step to a data catalog is knowing what data to collect and whether it can either be automated and detected or manually submitted. The reality is that this will likely evolve over time based on factors like the regulatory needs and internal processes — so a flexible data model is key.
We’ll take the general example of using a data catalog to first capture information about proposed data sources for approval by a data governance or administrator prior to the data being ingested, then serving as the inventory as the data lands and is prepared in the platform. Below are common questions we typically see as necessary content to capture about data to both understand the data, but also have context on how data should be handled and used:

How it works in Palantir Foundry
Using Foundry, organizations can leverage existing applications and templates to set up a data catalog for all data not only within Foundry, but also across their organization. For purposes of this blog post, we’ll focus just on data cataloging within Foundry, but it is easily extensible to tracking data in other systems. We’ll walk through what this often looks like for many of our clients in the platform:
Information Capture
The first step to any data catalog is capturing the relevant data and information about it. This can be done in various ways. Most commonly, we see this done with a form capturing data as part of the data approval process. This allows platform administrators and governance leads to centralize their review of any data requests and proposals prior to the data being brought and transferred onto the platform. This is where basic information, rationale, and purposes can be captured from requestors for review. As noted above, this questionnaire is designed to be flexible in order to capture new requirements and questions as the platform evolves.
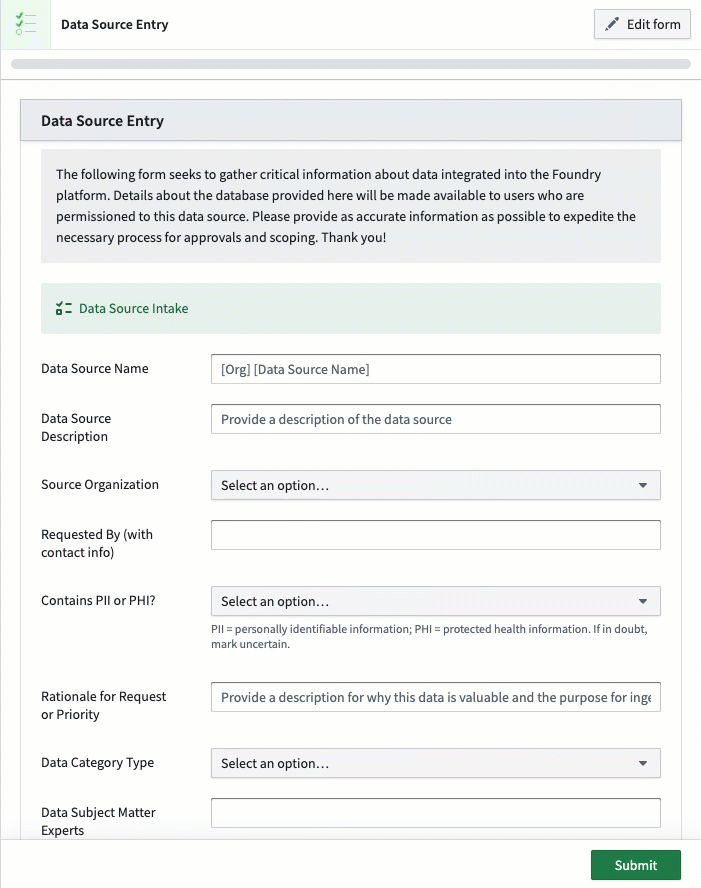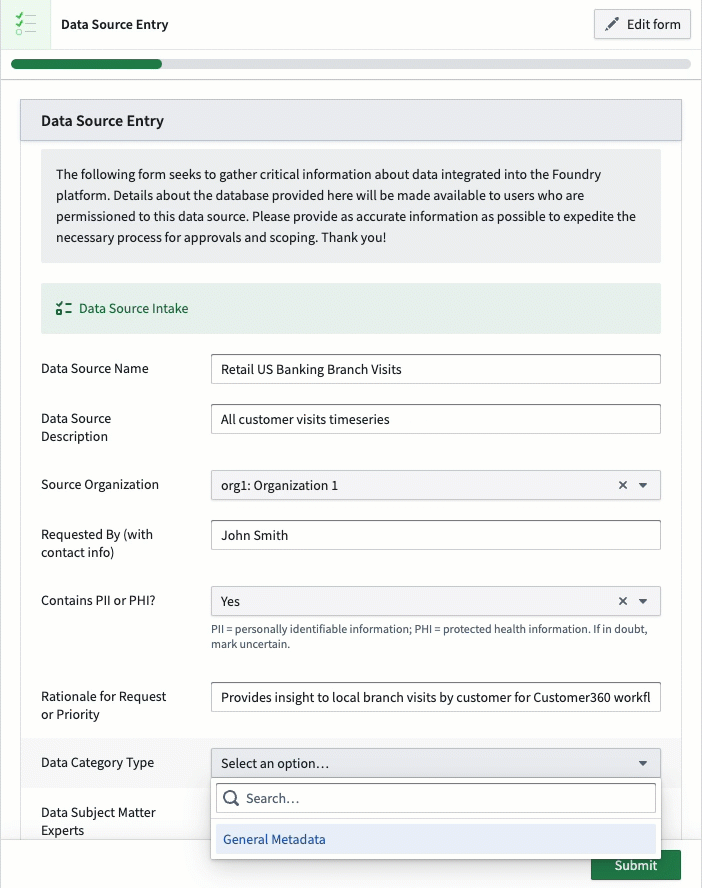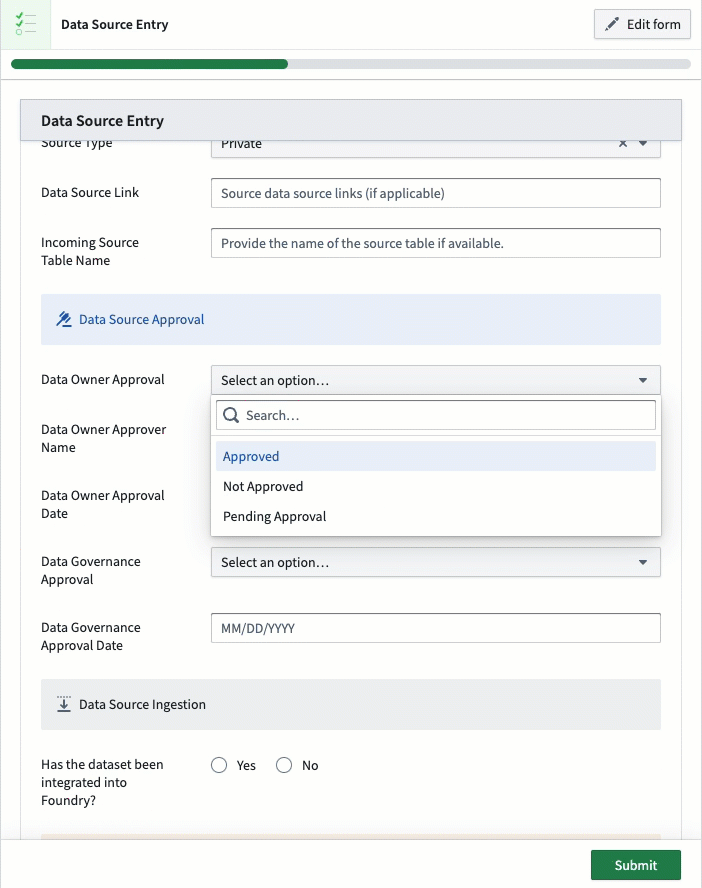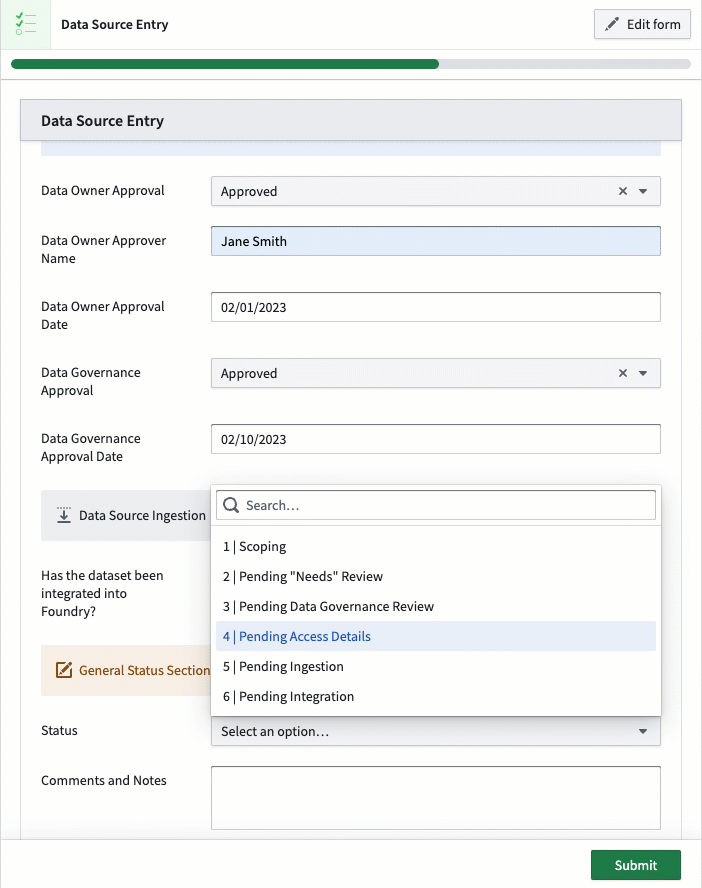
The implications of this data capture can be pivotal to how it can be used, especially with respect to different data protection regulations around the world, whether for geographies, sectors, or types of data. Examples of data handling requirements can range from anonymization requirements, retention requirements, or even data quality concerns. Establishing a method for oversight and review is important to ensure data platforms align and comply with requirements and so that users can know how to leverage data appropriately.
Another way this data can be populated is with automation for whenever data lands into the platform. Foundry can support this by automatically detecting new data coming onto the platform and regularly pulling metadata about those tables, such as columns, data formats, and other metadata from the source. The method selected largely depends on the ideal data governance workflow, specifically on whether data needs to be approved prior to landing in Foundry or not.
Centralized Application
Once the data has been identified and relevant metadata and information captured, all of this data can then be deposited into a user-friendly data catalog. The data catalog provides the single pane of glass to navigate around everything involving data on the platform. This includes the list of all data available, where to input new information, the functionality to search across data, and much more.
Below is an example setup for a “Data Source Tracker” or data catalog for a financial institution. Users can scroll through all data, filter, or search for specific characteristics and statuses, and link directly to the source. Here, the Data Source Tracker signals to users if there is PII, if the data has not been approved, even if the data is ready or not for users to access it.
Typically in an organization without a data catalog, data can be scattered across the different departments and requires users to know the right person to ask and retrieve it in order provide you with the correct access. With the Data Source Tracker, the repository of knowledge is at the fingertips of the community providing the information, with the approvals and oversight managed in the common store.
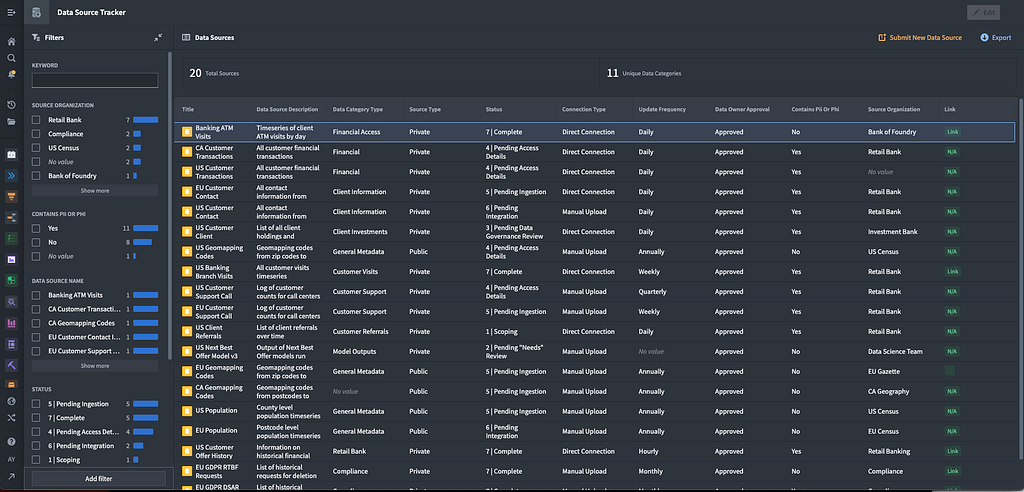
When it comes to data protection, for users who are working with data they are just finding on the platform, the Data Source Tracker also provides a way for them to have a curated view of information they need to know about the data. This is particularly relevant in cases when data needs to be handled in specific ways or only for specific use cases.
For instance, some data may need to have restrictions on what PII can be shared for certain purposes, others may require data to be aggregated or deidentified prior to further sharing. The power of the Data Source Tracker is that the data governance instructions sit alongside the data, streamlining the process for getting context and using the data.
Dynamic Search across Data
The power of the Data Catalog then can come with the ability to quickly search for information across the platform. Whether looking for columns or characteristics, the ability to dynamically search gives users a quick way to find what they are looking for faster and more comprehensively. For instance, in the example of a financial institution, analysts may be looking for data to build next best offer models based on geographies. They might start with first seeing where there is PII data about customers, filtering for those datasets, and then finding which tables have addresses about individuals.

Conclusion
From our work with everyone from car manufacturers to pharmaceutical companies and public health agencies around the world, we have seen that as organizations with large-scale operations become more data-driven, the transition demands systems and processes to responsibly govern data across a data platform, such as using data catalogs.
Data catalogs give platform administrators the ability to centrally funnel and manage data coming onto the platform and signal data governance controls, while giving users the ability to quickly search, filter, and navigate to the data they need. It becomes a central component for data governance, while being able to leverage the underlying flexibility of Foundry to adapt over time. This investment in making data cataloging easy and adaptable unlocks the power of data platforms by structuring data, making users and ultimately organizations, more powerful in their day-to-day operations.
Author
Alice Yu, Privacy & Civil Liberties Commercial and Public Health Lead, Palantir Technologies
![]()
Data Cataloging: Bringing order to chaos was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.