
In 2019, Amazon co-founded the climate pledge. The pledge’s goal is to achieve net zero carbon by 2040. This is 10 years earlier than the Paris agreement outlines. Companies who sign up are committed to regular reporting, carbon elimination, and credible offsets. At the time of this writing, 377 companies have signed the climate pledge, and the number is still growing.
Because AWS is committed to helping you achieve your net zero goal through cloud solutions and machine learning (ML), many projects have already been developed and deployed that reduce carbon emissions. Manufacturing is one of the industries that can benefit greatly from such projects. Through optimized energy management of machines in manufacturing factories, such as compressors or chillers, companies can reduce their carbon footprint with ML.
Effectively transitioning from an ML experimentation phase to production is challenging. Automating model training and retraining, having a model registry, and tracking experiments and deployment are some of the key challenges. For manufacturing companies, there is another layer of complexity, namely how these deployed models can run at the edge.
In this post, we address these challenges by providing a machine learning operations (MLOps) template that hosts a sustainable energy management solution. The solution is agnostic to use cases, which means you can adapt it for your use cases by changing the model and data. We show you how to integrate models in Amazon SageMaker Pipelines, a native workflow orchestration tool for building ML pipelines, which runs a training job and optionally a processing job with a Monte Carlo Simulation. Experiments are tracked in Amazon SageMaker Experiments. Models are tracked and registered in the Amazon SageMaker model registry. Finally, we provide code for deployment of your final model in an AWS Lambda function.
Lambda is a compute service that lets you run code without managing or provisioning servers. Lambda’s automatic scaling, pay-per-request billing, and ease of use make it a common deployment choice for data science teams. With this post, data scientists can turn their model into a cost-effective and scalable Lambda function. Furthermore, Lambda allows for integration with AWS IoT Greengrass, which helps you build software that enables your devices to act at the edge on the data that they generate, as would be the case for a sustainable energy management solution.
Solution overview
The architecture we deploy (see the following figure) is a fully CI/CD-driven approach to machine learning. Elements are decoupled to avoid having one monolithic solution.

Let’s start with the top left of the diagram. The Processing – Image build component is a CI/CD-driven AWS CodeCommit repository that helps build and push a Docker container to Amazon Elastic Container Registry (Amazon ECR). This processing container serves as the first step in our ML pipeline, but it’s also reused for postprocessing steps. In our case, we apply a Monte Carlo Simulation as postprocessing. The Training – Image build repository outlined on the bottom left has the same mechanism as the Processing block above it. The main difference is that it builds the container for model training.
The main pipeline, Model building (Pipeline), is another CodeCommit repository that automates running your SageMaker pipelines. This pipeline automates and connects the data preprocessing, model training, model metrics tracking in SageMaker Experiments, data postprocessing, and, model cataloging in SageMaker model registry.
The final component is on the bottom right: Model deployment. If you follow the examples in Amazon SageMaker Projects, you get a template that hosts your model using a SageMaker endpoint. Our deployment repository instead hosts the model in a Lambda function. We show an approach for deploying the Lambda function that can run real-time predictions.
Prerequisites
To deploy our solution successfully, you need the following:
- An AWS account.
- An AWS Cloud Development Kit (AWS CDK) installation. For this post, we use Python.
- An AWS Command Line Interface (AWS CLI) installation.
- An Amazon SageMaker Studio domain with a user set up.
Download the GitHub repository
As a first step, clone the GitHub repository to your local machine. It contains the following folder structure:
- deployment – Contains code relevant for deployment
- mllib — Contains ML code for preprocessing, training, serving, and simulating
- tests — Contains unit and integration tests
The key file for deployment is the shell script deployment/deploy.sh. You use this file to deploy the resources in your account. Before we can run the shell script, complete the following steps:
- Open the
deployment/app.pyand change the bucket_name underSageMakerPipelineSourceCodeStack. Thebucket_nameneeds to be globally unique (for example, add your full name). - In
deployment/pipeline/assets/modelbuild/pipelines/energy_management/pipeline.py, change thedefault_bucketunderget_pipelineto the same name as specified in step 1.
Deploy solution with the AWS CDK
First, configure your AWS CLI with the account and Region that you want to deploy in. Then run the following commands to change to the deployment directory, create a virtual environment, activate it, install the required pip packages specified in setup.py, and run the deploy.sh:
deploy.sh performs the following actions:
- Creates a virtual environment in Python.
- Sources the virtual environment activation script.
- Installs the AWS CDK and the requirements outlined in
setup.py. - Bootstraps the environment.
- Zips and copies the necessary files that you developed, such as your
mllibfiles, into the corresponding folders where these assets are needed. - Runs
cdk deploy —require-approval never. - Creates an AWS CloudFormation stack through the AWS CDK.
The initial stage of the deployment should take less than 5 minutes. You should now have four repositories in CodeCommit in the Region you specified through the AWS CLI, as outlined in the architecture diagram. The AWS CodePipeline pipelines are run simultaneously. The modelbuild and modeldeploy pipelines depend on a successful run of the processing and training image build. The modeldeploy pipeline depends on a successful model build. The model deployment should be complete in less than 1.5 hours.
Clone the model repositories in Studio
To customize the SageMaker pipelines created through the AWS CDK deployment in the Studio UI, you first need to clone the repositories into Studio. Launch the system terminal in Studio and run the following commands after providing the project name and ID:
After cloning the repositories, you can push a commit to the repositories. These commits trigger a CodePipeline run for the related pipelines.
You can also adapt the solution on your local machine and work on your preferred IDE.
Navigate the SageMaker Pipelines and SageMaker Experiments UI
A SageMaker pipeline is a series of interconnected steps that are defined using the Amazon SageMaker Python SDK. This pipeline definition encodes a pipeline using a Directed Acyclic Graph (DAG) that can be exported as a JSON definition. To learn more about the structure of such pipelines, refer to SageMaker Pipelines Overview.
Navigate to SageMaker resources pane and choose the Pipelines resource to view. Under Name, you should see PROJECT_NAME-PROJECT_ID. In the run UI, there should be a successful run that is expected to take a little over 1 hour. The pipeline should look as shown in the following screenshot.
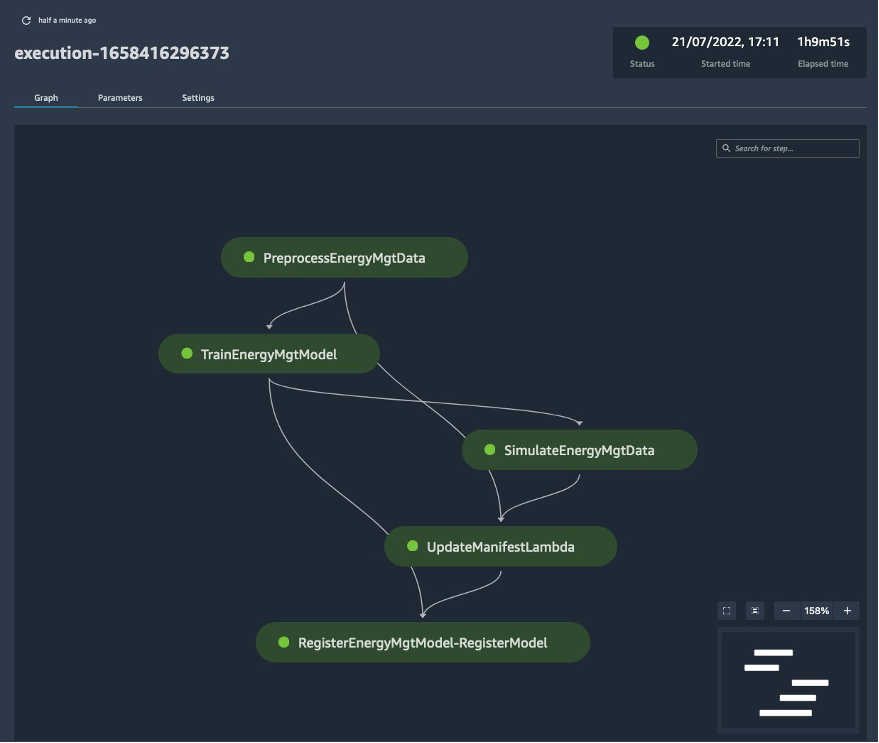
The run was automatically triggered after the AWS CDK stack was deployed. You can manually invoke a run by choosing Create execution. From there you can choose your own pipeline parameters such as the instance type and number of instances for the processing and training steps. Furthermore, you can give the run a name and description. The pipeline is highly configurable through pipeline parameters that you can reference and define throughout your pipeline definition.
Feel free to start another pipeline run with your parameters as desired. Afterwards, navigate to the SageMaker resources pane again and choose Experiments and trials. There you should again see a line with a name such as PROJECT_NAME-PROJECT_ID. Navigate to the experiment and choose the only run with a random ID. From there, choose the SageMaker training job to explore the metrics related to the training Job.
The goal of SageMaker Experiments is to make it as simple as possible to create experiments, populate them with trials, and run analytics across trials and experiments. SageMaker Pipelines are closely integrated with SageMaker Experiments, and by default for each run create an experiment, trial and trial components in case they do not exist.
Approve Lambda deployment in the model registry
As a next step, navigate to the model registry under SageMaker resources. Here you can find again a line with a name such as PROJECT_NAME-PROJECT_ID. Navigate to the only model that exists and approve it. This automatically deploys the model artifact in a container in Lambda.
After you approve your model in the model registry, an Amazon EventBridge event rule is triggered. This rule runs the CodePipeline pipeline with the ending *-modeldeploy. In this section, we discuss how this solution uses the approved model and hosts it in a Lambda function. CodePipeline takes the existing CodeCommit repository also ending with *-modeldeploy and uses that code to run in CodeBuild. The main entry for CodeBuild is the buildspec.yml file. Let’s look at this first:
During the installation phase, we ensure that the Python libraries are up to date, create a virtual environment, install AWS CDK v2.26.0, and install the aws-cdk Python library along with others using the requirements file. We also bootstrap the AWS account. In the build phase, we run build.py, which we discuss next. That file downloads the latest approved SageMaker model artifact from Amazon Simple Storage Service (Amazon S3) to your local CodeBuild instance. This .tar.gz file is unzipped and its contents copied into the folder that also contains our main Lambda code. The Lambda function is deployed using the AWS CDK, and code runs out of a Docker container from Amazon ECR. This is done automatically by AWS CDK.
The build.py file is a Python file that mostly uses the AWS SDK for Python (Boto3) to list the model packages available.
The function get_approved_package returns the Amazon S3 URI of the artifact that is then downloaded, as described earlier.
After successfully deploying your model, you can test it directly on the Lambda console in the Region you chose to deploy in. The name of the function should contain DigitalTwinStack-DigitalTwin*. Open the function and navigate to the Test tab. You can use the following event to run a test call:
After running the test event, you get a response similar to that shown in the following screenshot.
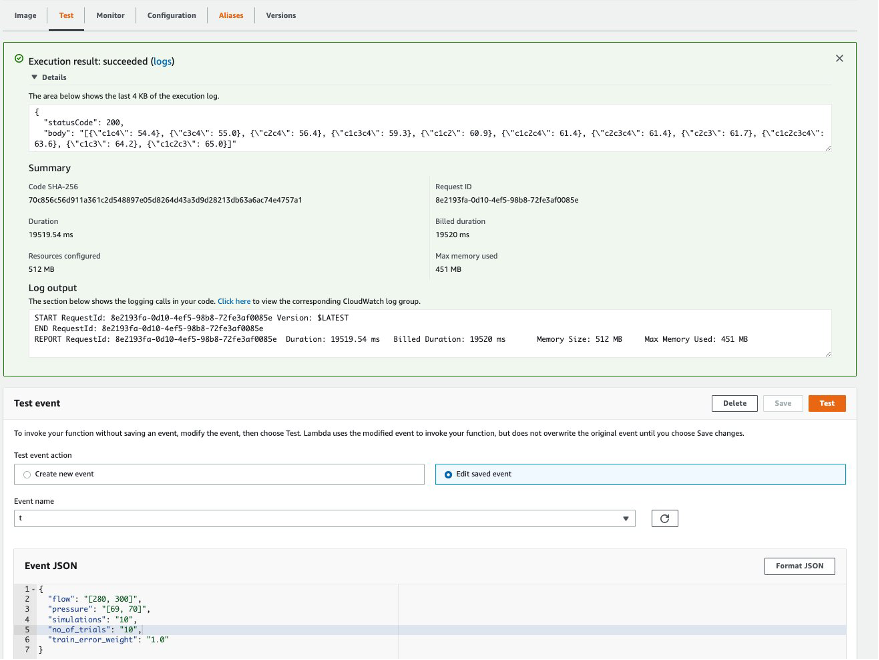
If you want to run more simulations or trials, you can increase the Lambda timeout limit and experiment with the code! Or you might want to pick up the data generated and visualize the same in Amazon QuickSight. Below is an example. It’s your turn now!

Clean up
To avoid further charges, complete the following steps:
- On the AWS CloudFormation console, delete the
EnergyOptimizationstack.
This deletes the entire solution. - Delete the stack
DigitalTwinStack, which deployed your Lambda function.
Conclusion
In this post, we showed you a CI/CD-driven MLOps pipeline of an energy management solution where we keep each step decoupled. You can track your ML pipelines and experiments in the Studio UI. We also demonstrated a different deployment approach: upon approval of a model in the model registry, a Lambda function hosting the approved model is built automatically through CodePipeline.
If you’re interested in exploring either the MLOps pipeline on AWS or the sustainable energy management solution, check out the GitHub repository and deploy the stack in your own AWS environment!
About the Authors
 Laurens van der Maas is a Data Scientist at AWS Professional Services. He works closely with customers building their machine learning solutions on AWS, and is passionate about how machine learning is changing the world as we know it.
Laurens van der Maas is a Data Scientist at AWS Professional Services. He works closely with customers building their machine learning solutions on AWS, and is passionate about how machine learning is changing the world as we know it.
 Kangkang Wang is an AI/ML consultant with AWS Professional Services. She has extensive experience of deploying AI/ML solutions in healthcare and life sciences vertical. She also enjoys helping enterprise customers to build scalable AI/ML platforms to accelerate the cloud journey of their data scientists.
Kangkang Wang is an AI/ML consultant with AWS Professional Services. She has extensive experience of deploying AI/ML solutions in healthcare and life sciences vertical. She also enjoys helping enterprise customers to build scalable AI/ML platforms to accelerate the cloud journey of their data scientists.
 Selena Tabbara is a Data Scientist at AWS Professional Services. She works everyday with her customers to achieve their business outcomes by innovating on AWS platforms. In her spare time, Selena enjoys playing the piano, hiking and watching basketball.
Selena Tabbara is a Data Scientist at AWS Professional Services. She works everyday with her customers to achieve their business outcomes by innovating on AWS platforms. In her spare time, Selena enjoys playing the piano, hiking and watching basketball.
 Michael Wallner is a Senior Consultant with focus on AI/ML with AWS Professional Services. Michael is passionate about enabling customers on their cloud journey to become AWSome. He is excited about manufacturing and enjoys helping transform the manufacturing space through data.
Michael Wallner is a Senior Consultant with focus on AI/ML with AWS Professional Services. Michael is passionate about enabling customers on their cloud journey to become AWSome. He is excited about manufacturing and enjoys helping transform the manufacturing space through data.