Editor’s note: In this post, I’ll be showing some amazing ways Document AI can help you extract meaning from your documents – keep reading, or jump directly into a tutorial using the Cloud Console!
Documents are a crucial part of most businesses, used to store and communicate important information. The variety is vast: invoices, contracts, receipts, applications, plus documents unique within industries and geographies. Unfortunately, making the information contained in these documents accessible can be a time-consuming and manual process.
Document AI is a document understanding platform in Google Cloud that takes unstructured data from documents and transforms it into structured data, making them easier to understand, analyze, and consume. By using this technology, you can streamline your document processing workflows, reduce errors, and unlock insights that were previously buried in mountains of paperwork.
Whether you’re a small business owner or an enterprise looking to bring efficiency to your operations, Document AI has something to offer. So let’s take a look and see what it can do!
Understanding documents with Document AI
When we say that Document AI can understand documents, we mean that it is able to analyze the content within documents and derive meaningful insights from it. This goes beyond simply recognizing the characters and words within a document (which is what traditional OCR technology does) – Document AI can actually comprehend the meaning behind the text.
For example, let’s say you have a contract that needs to be processed. Traditional OCR technology might be able to extract the text from the document, but it would not be able to understand the legal terms and clauses within it. Document AI, on the other hand, can actually interpret the meaning of the text and extract key information such as parties involved, terms and conditions, dates, and signatures.
Document AI offers several pre-built models and processors that are specifically designed to extract different types of data from various document types. Within the specific document types, the processors can perform several tasks such as Optical Character Recognition (OCR), form parsing, splitting, classification or entity extraction. These processors can be customized and combined to create powerful document processing workflows that are tailored to a business’s unique needs.
Let’s look closer at a few of the processors available in Document AI, including the Form Parser, Invoice Parser, Expense Parser, Identity Document Proofing Parser, and Intelligent Document Quality Processor.
Form Parser
This general processor is designed to extract structured data from forms such as application forms, surveys, and questionnaires. It automatically identifies and extracts data from form fields (key-value pairs), such as names, addresses, dates, and other types of structured data; even checkboxes and tables. This processor also leverages deep learning models to extract generic entities that are common in various document types, meaning it can identify if something is an email address, phone number, datetime, organization, quantity, price, person, and more.
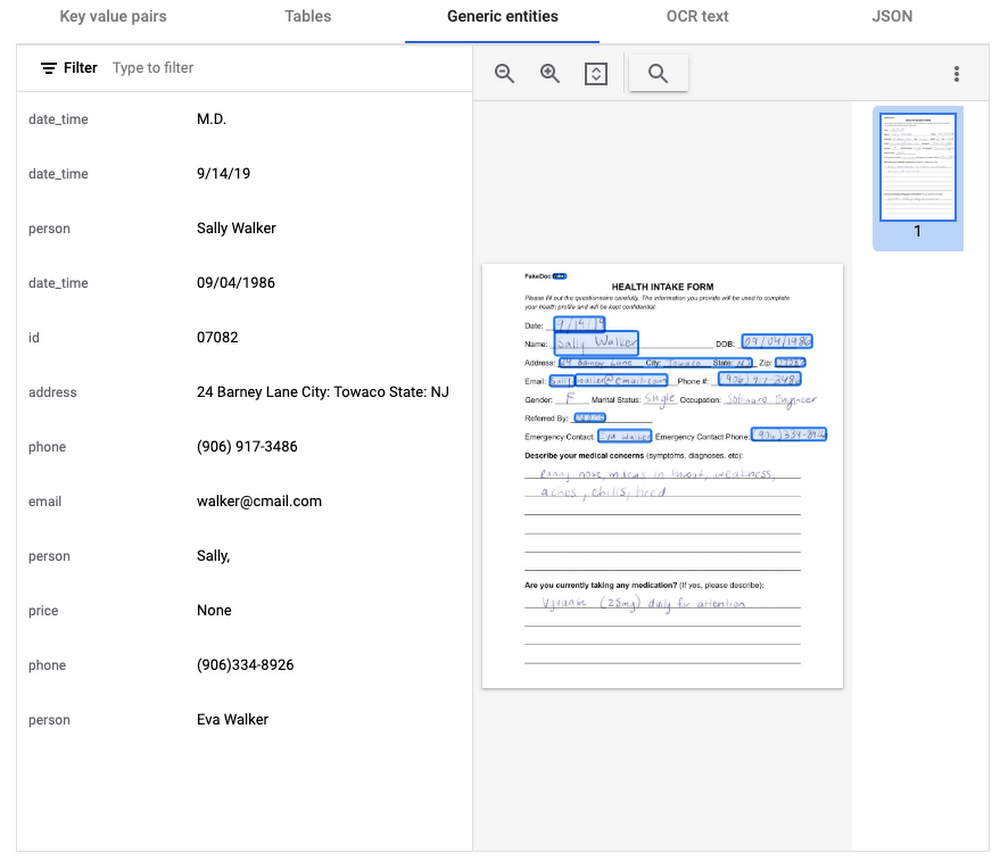
In this visualization of the API response, you can see that Document AI has identified several key value pairs that correspond to the form’s fields and the responder’s answers.
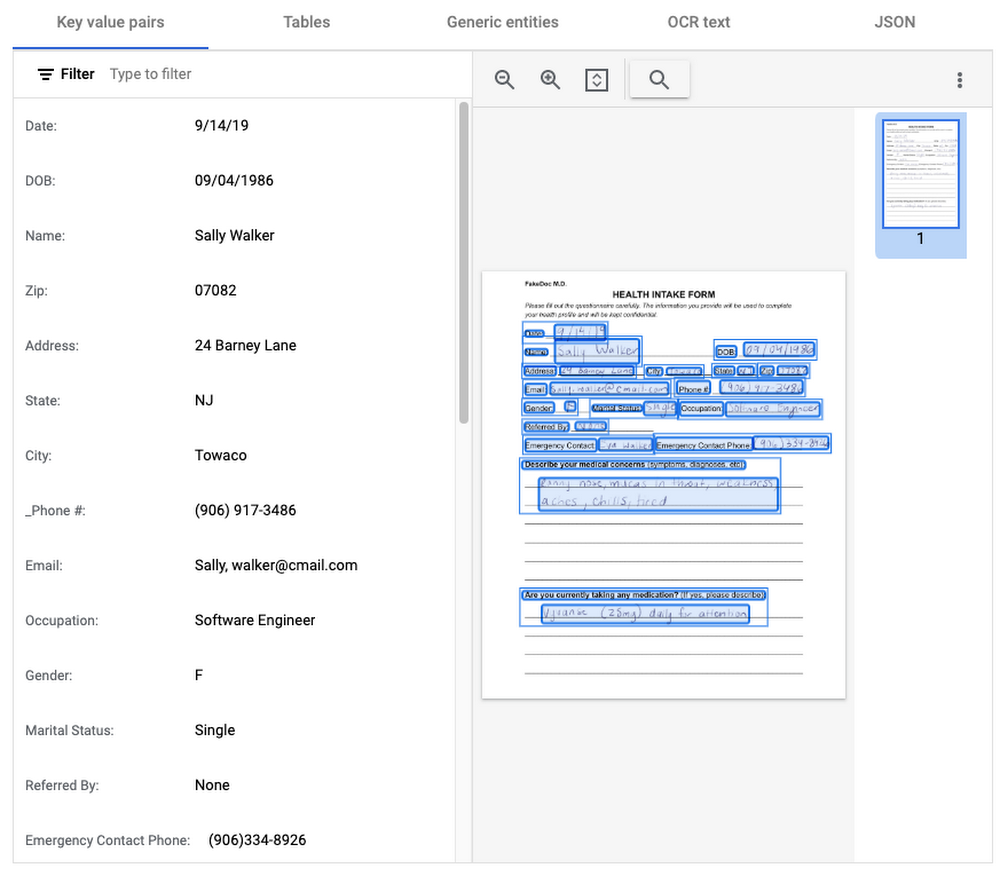
Also of interest is that the form parser recognized certain generic entities including: several dates, an address, phone numbers, email, and two people (the responder and their listed emergency contact).
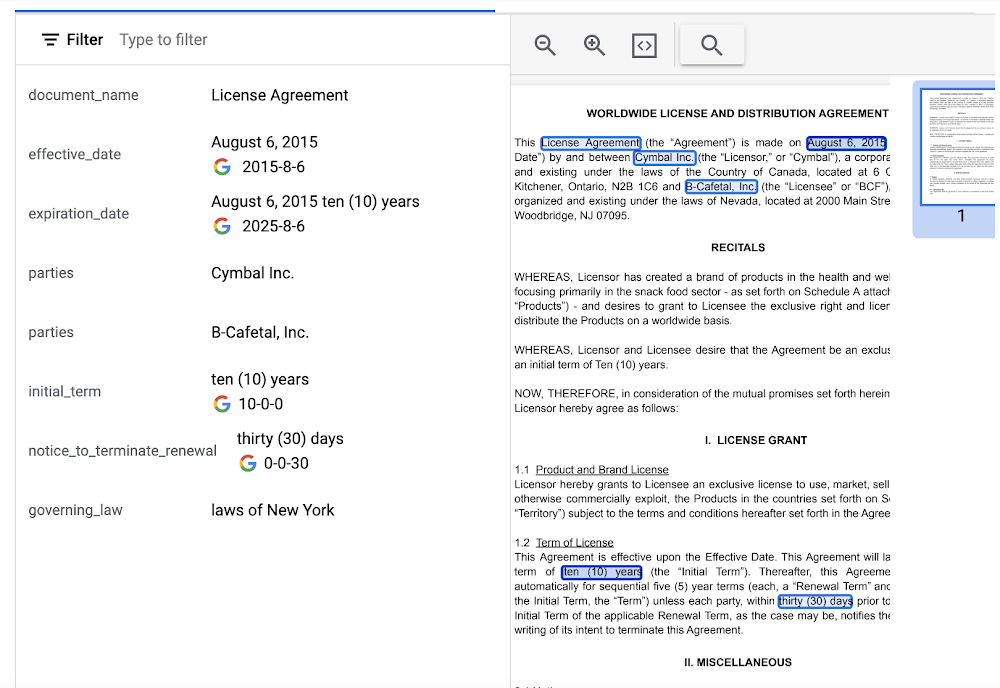
Invoice Parser
This parser is designed to identify and extract relevant information from invoices including a large number of typical invoice fields, but can also be customized (uptrained) to recognize different invoice layouts, languages, and data fields. Invoices are a critical part of the accounts payable process, making this functionality valuable across industries and companies building A/P features into their products.
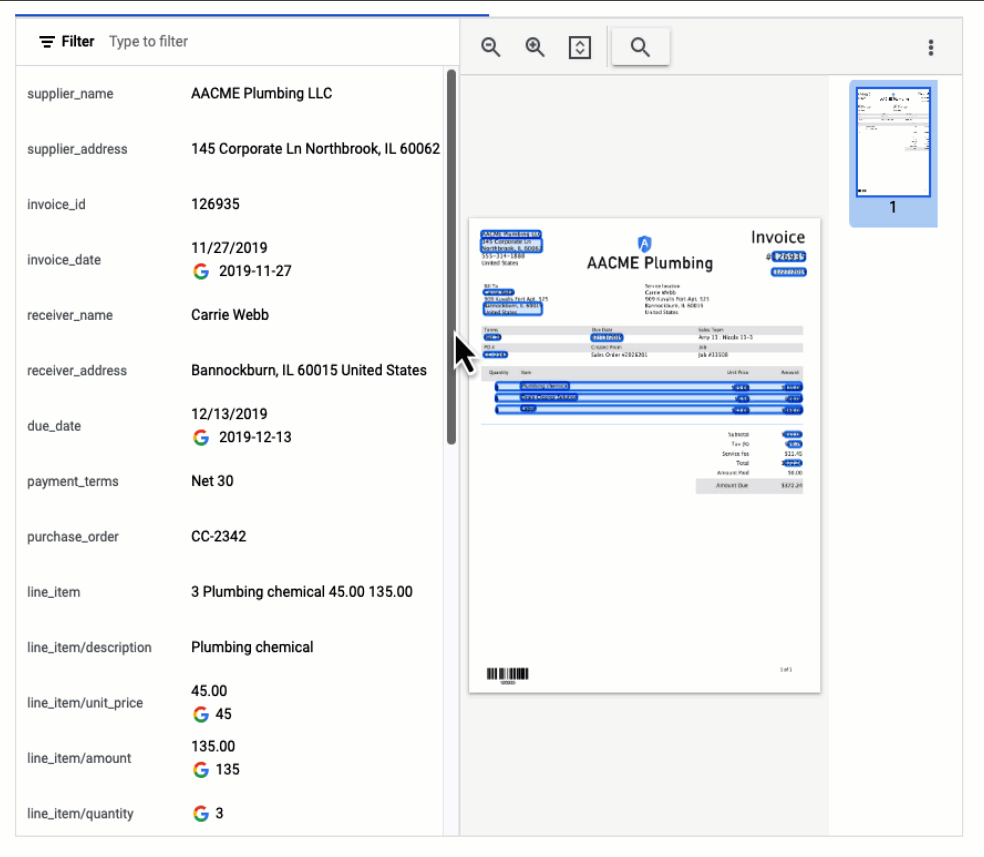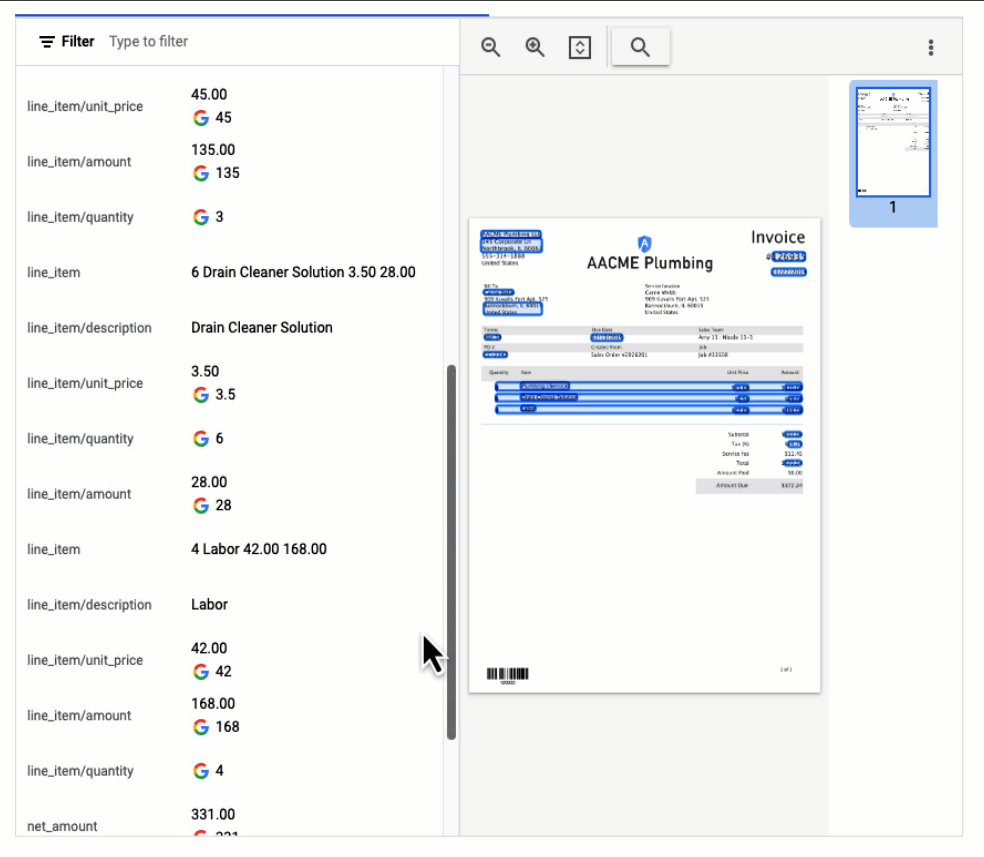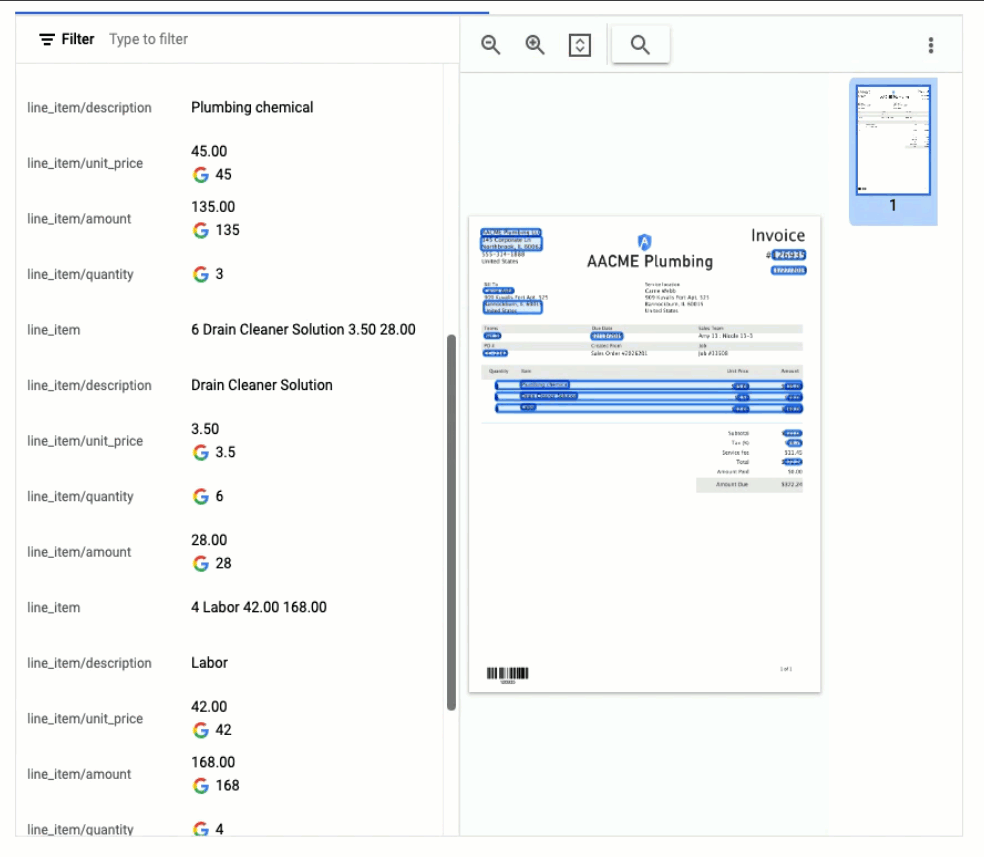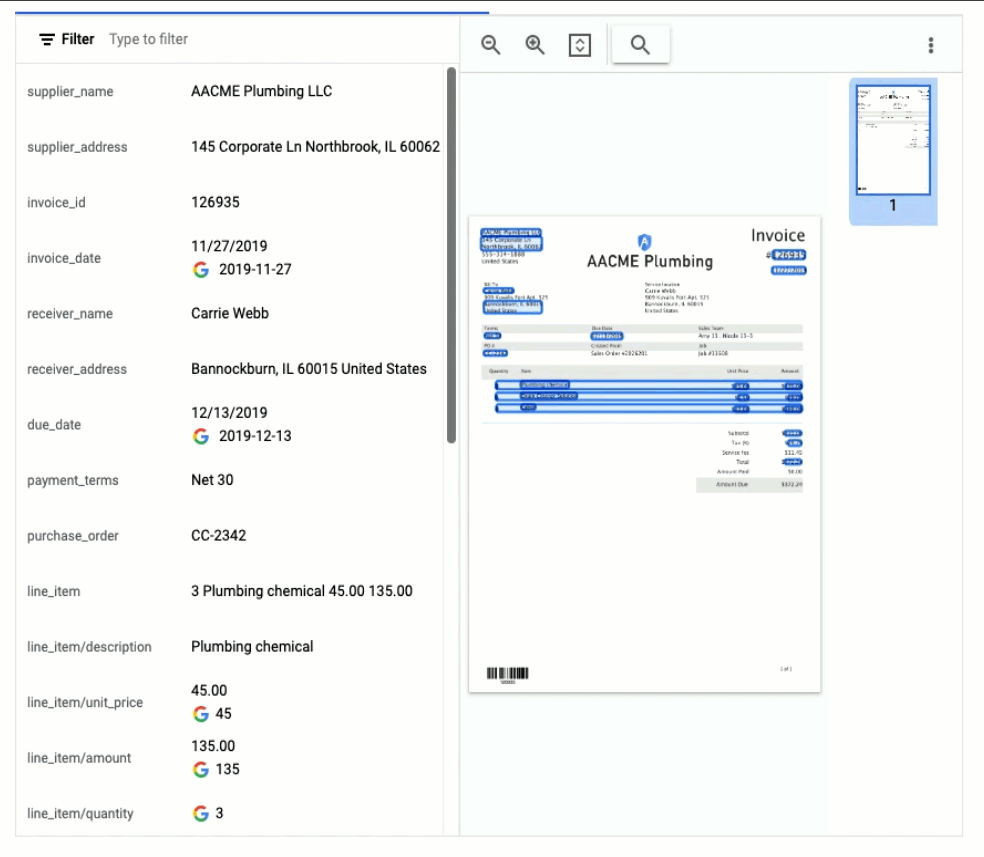
In this visualization of the API response, you can see that Document AI has extracted a large number of key-value pairs and even provided normalized values for several of the fields.
Expense Parser
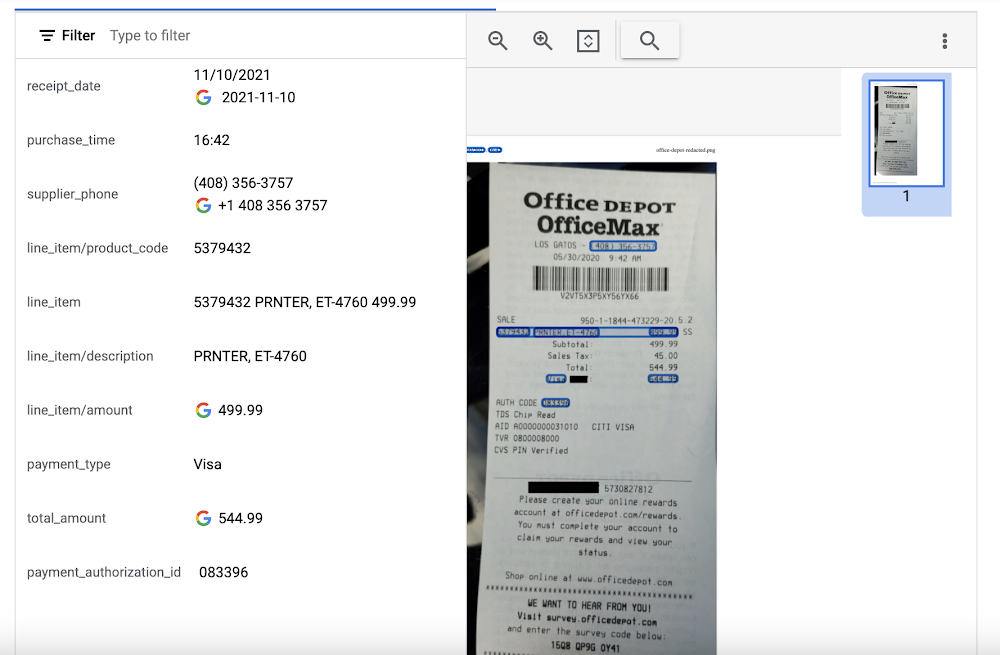
This specialized processor is designed to extract data from receipts and invoices, such as vendor name, date, and total amount paid. It can also identify line items within an invoice and categorize them based on the type of expense (e.g. meals, travel, office supplies). The expense parser makes it easier for you to process expense reports and other financial documents, and it can integrate with other tools and systems to completely automate the entire expense reporting process.
In this visualization of the API response, you can see that Document AI has extracted the text from the receipt and identified several typical entities such as purchase date and time, payment type, and total amount.
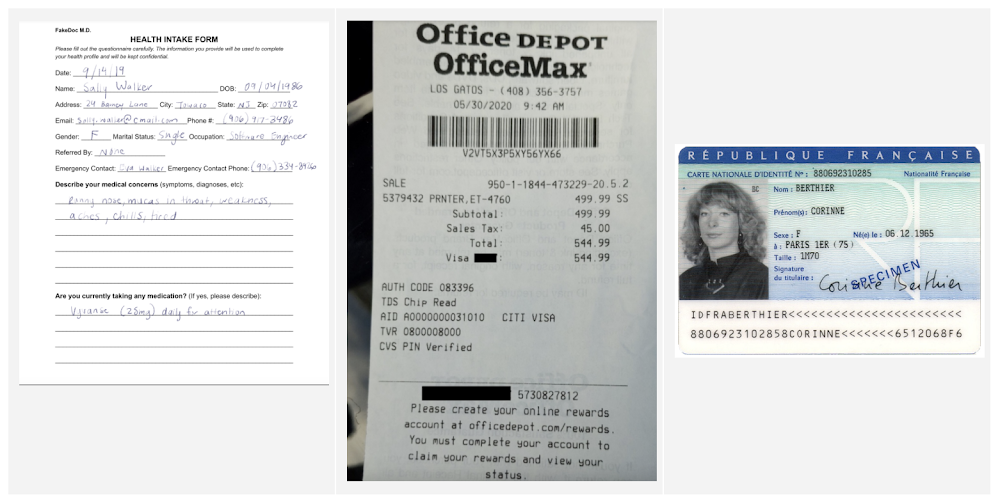
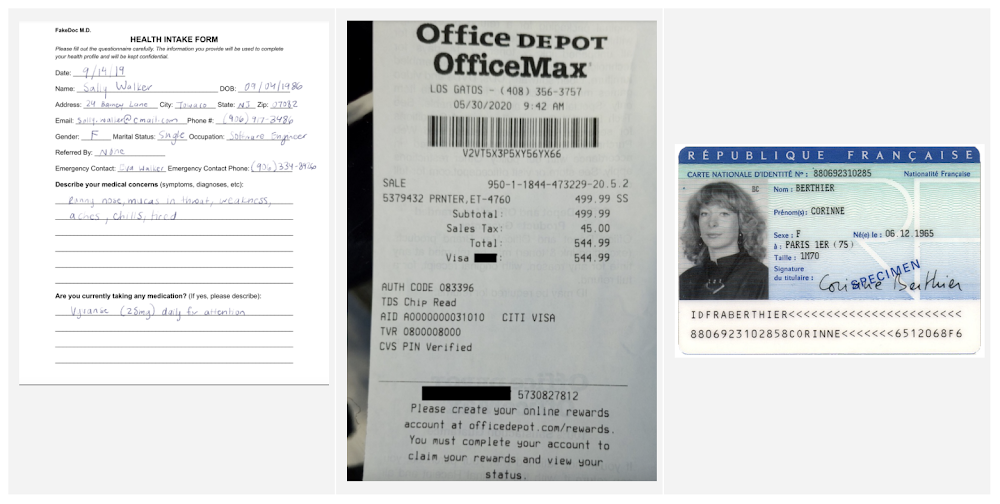
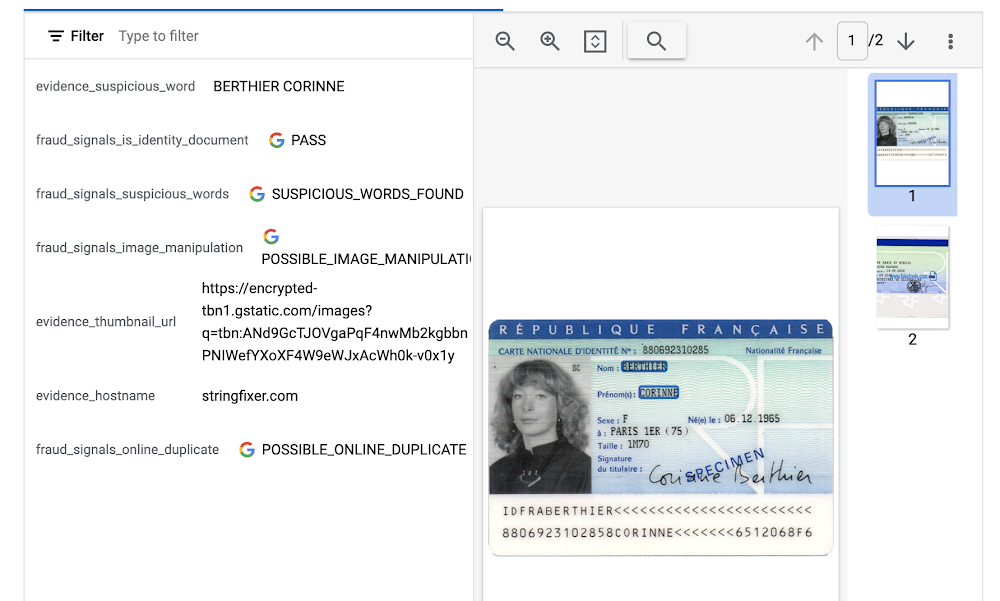
Identity Document Proofing Parser
This processor is designed to help predict the validity of ID documents with four different signals.
is_identity_document detection: Predicts whether an image contains a recognized identity document.
suspicious_words detection: Predicts whether words are present that aren’t typical on IDs.
image_manipulation detection: Predicts whether the image was altered or tampered via an image editing tool.
online_duplicate detection: Predicts whether the image can be found online.
If suspicious words are detected or the image can be found online, additional information is provided to explain these signals.
This can be particularly useful for businesses that need to verify the identity of customers or employees as part of their operations. This processor could be used in conjunction with other processors that extract key information such as name, date of birth, ID number, and expiration date from specific identity documents (US Driver License Parser, US Passport, France National ID Parser, etc.).
In this visualization of the API response, you can see that Document AI has passed the document on the first detection point (is_identity_document), but failed the document for the other three items and provided additional information in the evidence fields.
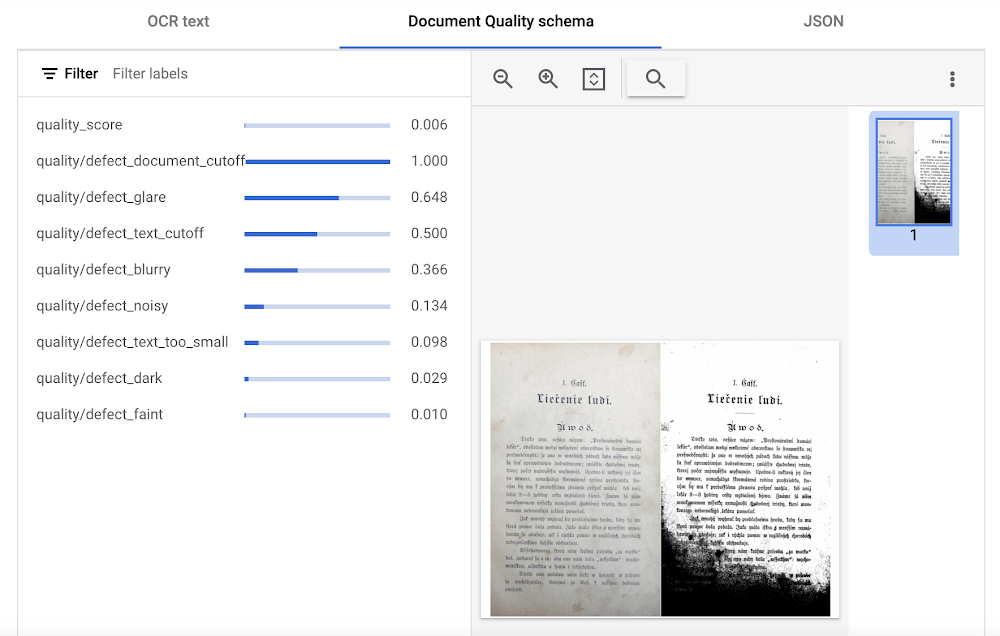
Intelligent Document Quality Processor
This general use processor is designed to detect a variety of document quality issues, such as missing pages, blurry images, low contrast, inconsistent formatting, and incorrect data, and flag these potential issues which could affect their usability, accuracy, or compliance. It can also identify sensitive information that has not been redacted or missing information required by regulatory standards.
This quality assessment is returned as a quality score from 0 to 1, where 1 means perfect quality. If the quality score detected is lower than 0.5, a list of negative quality reasons (sorted by the likelihood) is also returned.
In this visualization of the API response, you can see that Document AI has determined a quality_score of 0.006 and also provided a list of several reasons including document and text cutoff, blurriness, and glare (among others).
Next steps
These are just a few examples of the types of processors that Document AI offers. Perusing the current documentation, you can find it has more than 40 processors, with each providing several functions, to explore. Document AI also offers you the ability to uptrain certain processors and supports the option to build your own custom processor. Across the board, if a document contains structured or unstructured text, Document AI has the capability to extract valuable data from it.
Get started and learn more by heading to our tutorials in the Cloud Console: