Data classification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. AWS intelligent document processing (IDP), with AI services such as Amazon Textract, allows you to take advantage of industry-leading machine learning (ML) technology to quickly and accurately process data from any scanned document or image. Generative artificial intelligence (generative AI) complements Amazon Textract to further automate document processing workflows. Features such as normalizing key fields and summarizing input data support faster cycles for managing document process workflows, while reducing the potential for errors.
Generative AI is driven by large ML models called foundation models (FMs). FMs are transforming the way you can solve traditionally complex document processing workloads. In addition to existing capabilities, businesses need to summarize specific categories of information, including debit and credit data from documents such as financial reports and bank statements. FMs make it easier to generate such insights from the extracted data. To optimize time spent in human review and to improve employee productivity, mistakes such as missing digits in phone numbers, missing documents, or addresses without street numbers can be flagged in an automated way. In the current scenario, you need to dedicate resources to accomplish such tasks using human review and complex scripts. This approach is tedious and expensive. FMs can help complete these tasks faster, with fewer resources, and transform varying input formats into a standard template that can be processed further. At AWS, we offer services such as Amazon Bedrock, the easiest way to build and scale generative AI applications with FMs. Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can find the model that best suits your requirements. We also offer Amazon SageMaker JumpStart, which allows ML practitioners to choose from a broad selection of open-source FMs. ML practitioners can deploy FMs to dedicated Amazon SageMaker instances from a network isolated environment and customize models using SageMaker for model training and deployment.
Ricoh offers workplace solutions and digital transformation services designed to help customers manage and optimize information flow across their businesses. Ashok Shenoy, VP of Portfolio Solution Development, says, “We are adding generative AI to our IDP solutions to help our customers get their work done faster and more accurately by utilizing new capabilities such as Q&A, summarization, and standardized outputs. AWS allows us to take advantage of generative AI while keeping each of our customers’ data separate and secure.”
In this post, we share how to enhance your IDP solution on AWS with generative AI.
Improving the IDP pipeline
In this section, we review how the traditional IDP pipeline can be augmented by FMs and walk through an example use case using Amazon Textract with FMs.
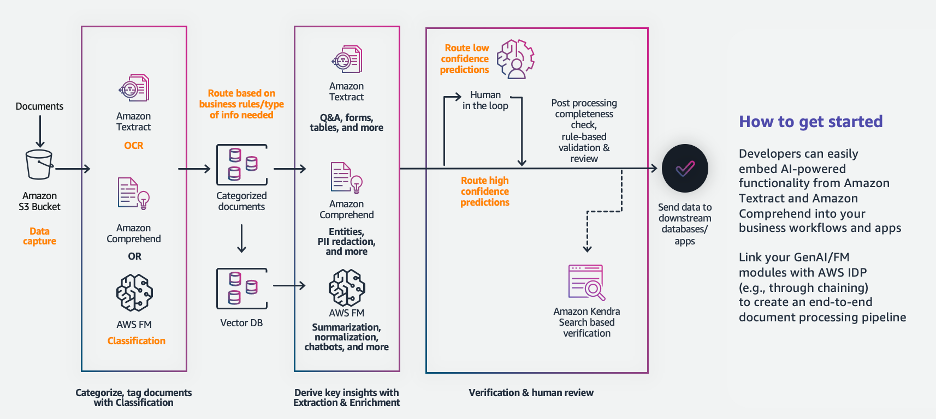
AWS IDP is comprised of three stages: classification, extraction, and enrichment. For more details about each stage, refer to Intelligent document processing with AWS AI services: Part 1 and Part 2. In the classification stage, FMs can now classify documents without any additional training. This means that documents can be categorized even if the model hasn’t seen similar examples before. FMs in the extraction stage normalize date fields and verify addresses and phone numbers, while ensuring consistent formatting. FMs in the enrichment stage allow inference, logical reasoning, and summarization. When you use FMs in each IDP stage, your workflow will be more streamlined and performance will improve. The following diagram illustrates the IDP pipeline with generative AI.

Extraction stage of the IDP pipeline
When FMs can’t directly process documents in their native formats (such as PDFs, img, jpeg, and tiff) as an input, a mechanism to convert documents to text is needed. To extract the text from the document before sending it to the FMs, you can use Amazon Textract. With Amazon Textract, you can extract lines and words and pass them to downstream FMs. The following architecture uses Amazon Textract for accurate text extraction from any type of document before sending it to FMs for further processing.

Typically, documents are comprised of structured and semi-structured information. Amazon Textract can be used to extract raw text and data from tables and forms. The relationship between the data in tables and forms plays a vital role in automating business processes. Certain types of information may not be processed by FMs. As a result, we can choose to either store this information in a downstream store or send it to FMs. The following figure is an example of how Amazon Textract can extract structured and semi-structured information from a document, in addition to lines of text that need to be processed by FMs.

Using AWS serverless services to summarize with FMs
The IDP pipeline we illustrated earlier can be seamlessly automated using AWS serverless services. Highly unstructured documents are common in big enterprises. These documents can span from Securities and Exchange Commission (SEC) documents in the banking industry to coverage documents in the health insurance industry. With the evolution of generative AI at AWS, people in these industries are looking for ways to get a summary from those documents in an automated and cost-effective manner. Serverless services help provide the mechanism to build a solution for IDP quickly. Services such as AWS Lambda, AWS Step Functions, and Amazon EventBridge can help build the document processing pipeline with integration of FMs, as shown in the following diagram.

The sample application used in the preceding architecture is driven by events. An event is defined as a change in state that has recently occurred. For example, when an object gets uploaded to an Amazon Simple Storage Service (Amazon S3) bucket, Amazon S3 emits an Object Created event. This event notification from Amazon S3 can trigger a Lambda function or a Step Functions workflow. This type of architecture is termed as an event-driven architecture. In this post, our sample application uses an event-driven architecture to process a sample medical discharge document and summarize the details of the document. The flow works as follows:
- When a document is uploaded to an S3 bucket, Amazon S3 triggers an Object Created event.
- The EventBridge default event bus propagates the event to Step Functions based on an EventBridge rule.
- The state machine workflow processes the document, beginning with Amazon Textract.
- A Lambda function transforms the analyzed data for the next step.
- The state machine invokes a SageMaker endpoint, which hosts the FM using direct AWS SDK integration.
- A summary S3 destination bucket receives the summary response gathered from the FM.
We used the sample application with a flan-t5 Hugging face model to summarize the following sample patient discharge summary using the Step Functions workflow.

The Step Functions workflow uses AWS SDK integration to call the Amazon Textract AnalyzeDocument and SageMaker runtime InvokeEndpoint APIs, as shown in the following figure.

This workflow results in a summary JSON object that is stored in a destination bucket. The JSON object looks as follows:
{
"summary": [
"John Doe is a 35-year old male who has been experiencing stomach problems for two months. He has been taking antibiotics for the last two weeks, but has not been able to eat much. He has been experiencing a lot of abdominal pain, bloating, and fatigue. He has also noticed a change in his stool color, which is now darker. He has been taking antacids for the last two weeks, but they no longer help. He has been experiencing a lot of fatigue, and has been unable to work for the last two weeks. He has also been experiencing a lot of abdominal pain, bloating, and fatigue. He has been taking antacids for the last two weeks, but they no longer help. He has been experiencing a lot of abdominal pain, bloating, and fatigue. He has been taking antacids for the last two weeks, but they no longer help. He has been experiencing a lot of abdominal pain, bloating, and fatigue. He has been taking antacids for the last two weeks, but they no longer help. He has been experiencing a lot of abdominal pain, bloating, and fatigue. He has been taking antacids for the last two weeks, but they no longer help."
],
"forms": [
{
"key": "Ph: ",
"value": "(888)-(999)-(0000) "
},
{
"key": "Fax: ",
"value": "(888)-(999)-(1111) "
},
{
"key": "Patient Name: ",
"value": "John Doe "
},
{
"key": "Patient ID: ",
"value": "NARH-36640 "
},
{
"key": "Gender: ",
"value": "Male "
},
{
"key": "Attending Physician: ",
"value": "Mateo Jackson, PhD "
},
{
"key": "Admit Date: ",
"value": "07-Sep-2020 "
},
{
"key": "Discharge Date: ",
"value": "08-Sep-2020 "
},
{
"key": "Discharge Disposition: ",
"value": "Home with Support Services "
},
{
"key": "Pre-existing / Developed Conditions Impacting Hospital Stay: ",
"value": "35 yo M c/o stomach problems since 2 months. Patient reports epigastric abdominal pain non- radiating. Pain is described as gnawing and burning, intermittent lasting 1-2 hours, and gotten progressively worse. Antacids used to alleviate pain but not anymore; nothing exacerbates pain. Pain unrelated to daytime or to meals. Patient denies constipation or diarrhea. Patient denies blood in stool but have noticed them darker. Patient also reports nausea. Denies recent illness or fever. He also reports fatigue for 2 weeks and bloating after eating. ROS: Negative except for above findings Meds: Motrin once/week. Tums previously. PMHx: Back pain and muscle spasms. No Hx of surgery. NKDA. FHx: Uncle has a bleeding ulcer. Social Hx: Smokes since 15 yo, 1/2-1 PPD. No recent EtOH use. Denies illicit drug use. Works on high elevation construction. Fast food diet. Exercises 3-4 times/week but stopped 2 weeks ago. "
},
{
"key": "Summary: ",
"value": "some activity restrictions suggested, full course of antibiotics, check back with physican in case of relapse, strict diet "
}
]
}
Generating these summaries using IDP with serverless implementation at scale helps organizations get meaningful, concise, and presentable data in a cost-effective way. Step Functions doesn’t limit the method of processing documents to one document at a time. Its distributed map feature can summarize large numbers of documents on a schedule.
The sample application uses a flan-t5 Hugging face model; however, you can use an FM endpoint of your choice. Training and running the model is out of scope of the sample application. Follow the instructions in the GitHub repository to deploy a sample application. The preceding architecture is a guidance on how you can orchestrate an IDP workflow using Step Functions. Refer to the IDP Generative AI workshop for detailed instructions on how to build an application with AWS AI services and FMs.
Set up the solution
Follow the steps in the README file to set the solution architecture (except for the SageMaker endpoints). After you have your own SageMaker endpoint available, you can pass the endpoint name as a parameter to the template.
Clean up
To save costs, delete the resources you deployed as part of the tutorial:
- Follow the steps in the cleanup section of the README file.
- Delete any content from your S3 bucket and then delete the bucket through the Amazon S3 console.
- Delete any SageMaker endpoints you may have created through the SageMaker console.
Conclusion
Generative AI is changing how you can process documents with IDP to derive insights. AWS AI services such as Amazon Textract along with AWS FMs can help accurately process any type of documents. For more information on working with generative AI on AWS, refer to Announcing New Tools for Building with Generative AI on AWS.
About the Authors
 Sonali Sahu is leading intelligent document processing with the AI/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
Sonali Sahu is leading intelligent document processing with the AI/ML services team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
 Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for Intelligent document processing. He got his Master’s in Business Administration at the University of Washington.
Ashish Lal is a Senior Product Marketing Manager who leads product marketing for AI services at AWS. He has 9 years of marketing experience and has led the product marketing effort for Intelligent document processing. He got his Master’s in Business Administration at the University of Washington.
 Mrunal Daftari is an Enterprise Senior Solutions Architect at Amazon Web Services. He is based in Boston, MA. He is a cloud enthusiast and very passionate about finding solutions for customers that are simple and address their business outcomes. He loves working with cloud technologies, providing simple, scalable solutions that drive positive business outcomes, cloud adoption strategy, and design innovative solutions and drive operational excellence.
Mrunal Daftari is an Enterprise Senior Solutions Architect at Amazon Web Services. He is based in Boston, MA. He is a cloud enthusiast and very passionate about finding solutions for customers that are simple and address their business outcomes. He loves working with cloud technologies, providing simple, scalable solutions that drive positive business outcomes, cloud adoption strategy, and design innovative solutions and drive operational excellence.
 Dhiraj Mahapatro is a Principal Serverless Specialist Solutions Architect at AWS. He specializes in helping enterprise financial services adopt serverless and event-driven architectures to modernize their applications and accelerate their pace of innovation. Recently, he has been working on bringing container workloads and practical usage of generative AI closer to serverless and EDA for financial services industry customers.
Dhiraj Mahapatro is a Principal Serverless Specialist Solutions Architect at AWS. He specializes in helping enterprise financial services adopt serverless and event-driven architectures to modernize their applications and accelerate their pace of innovation. Recently, he has been working on bringing container workloads and practical usage of generative AI closer to serverless and EDA for financial services industry customers.
 Jacob Hauskens is a Principal AI Specialist with over 15 years of strategic business development and partnerships experience. For the past 7 years, he has led the creation and implementation of go-to-market strategies for new AI-powered B2B services. Recently, he has been helping ISVs grow their revenue by adding generative AI to intelligent document processing workflows.
Jacob Hauskens is a Principal AI Specialist with over 15 years of strategic business development and partnerships experience. For the past 7 years, he has led the creation and implementation of go-to-market strategies for new AI-powered B2B services. Recently, he has been helping ISVs grow their revenue by adding generative AI to intelligent document processing workflows.