
Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data Platform
by Binbing Hou, Stephanie Vezich Tamayo, Xiao Chen, Liang Tian, Troy Ristow, Haoyuan Wang, Snehal Chennuru, Pawan Dixit
This is the first of the series of our work at Netflix on leveraging data insights and Machine Learning (ML) to improve the operational automation around the performance and cost efficiency of big data jobs. Operational automation–including but not limited to, auto diagnosis, auto remediation, auto configuration, auto tuning, auto scaling, auto debugging, and auto testing–is key to the success of modern data platforms. In this blog post, we present our project on Auto Remediation, which integrates the currently used rule-based classifier with an ML service and aims to automatically remediate failed jobs without human intervention. We have deployed Auto Remediation in production for handling memory configuration errors and unclassified errors of Spark jobs and observed its efficiency and effectiveness (e.g., automatically remediating 56% of memory configuration errors and saving 50% of the monetary costs caused by all errors) and great potential for further improvements.
Introduction
At Netflix, hundreds of thousands of workflows and millions of jobs are running per day across multiple layers of the big data platform. Given the extensive scope and intricate complexity inherent to such a distributed, large-scale system, even if the failed jobs account for a tiny portion of the total workload, diagnosing and remediating job failures can cause considerable operational burdens.
For efficient error handling, Netflix developed an error classification service, called Pensive, which leverages a rule-based classifier for error classification. The rule-based classifier classifies job errors based on a set of predefined rules and provides insights for schedulers to decide whether to retry the job and for engineers to diagnose and remediate the job failure.
However, as the system has increased in scale and complexity, the rule-based classifier has been facing challenges due to its limited support for operational automation, especially for handling memory configuration errors and unclassified errors. Therefore, the operational cost increases linearly with the number of failed jobs. In some cases–for example, diagnosing and remediating job failures caused by Out-Of-Memory (OOM) errors–joint effort across teams is required, involving not only the users themselves, but also the support engineers and domain experts.
To address these challenges, we have developed a new feature, called Auto Remediation, which integrates the rule-based classifier with an ML service. Based on the classification from the rule-based classifier, it uses an ML service to predict retry success probability and retry cost and selects the best candidate configuration as recommendations; and a configuration service to automatically apply the recommendations. Its major advantages are below:
- Integrated intelligence. Instead of completely deprecating the current rule-based classifier, Auto Remediation integrates the classifier with an ML service so that it can leverage the merits of both: the rule-based classifier provides static, deterministic classification results per error class, which is based on the context of domain experts; the ML service provides performance- and cost-aware recommendations per job, which leverages the power of ML. With the integrated intelligence, we can properly meet the requirements of remediating different errors.
- Fully automated. The pipeline of classifying errors, getting recommendations, and applying recommendations is fully automated. It provides the recommendations together with the retry decision to the scheduler, and particularly uses an online configuration service to store and apply recommended configurations. In this way, no human intervention is required in the remediation process.
- Multi-objective optimizations. Auto Remediation generates recommendations by considering both performance (i.e., the retry success probability) and compute cost efficiency (i.e., the monetary costs of running the job) to avoid blindly recommending configurations with excessive resource consumption. For example, for memory configuration errors, it searches multiple parameters related to the memory usage of job execution and recommends the combination that minimizes a linear combination of failure probability and compute cost.
These advantages have been verified by the production deployment for remediating Spark jobs’ failures. Our observations indicate that Auto Remediation can successfully remediate about 56% of all memory configuration errors by applying the recommended memory configurations online without human intervention; and meanwhile reduce the cost of about 50% due to its ability to recommend new configurations to make memory configurations successful and disable unnecessary retries for unclassified errors. We have also noted a great potential for further improvement by model tuning (see the section of Rollout in Production).
Rule-based Classifier: Basics and Challenges
Basics
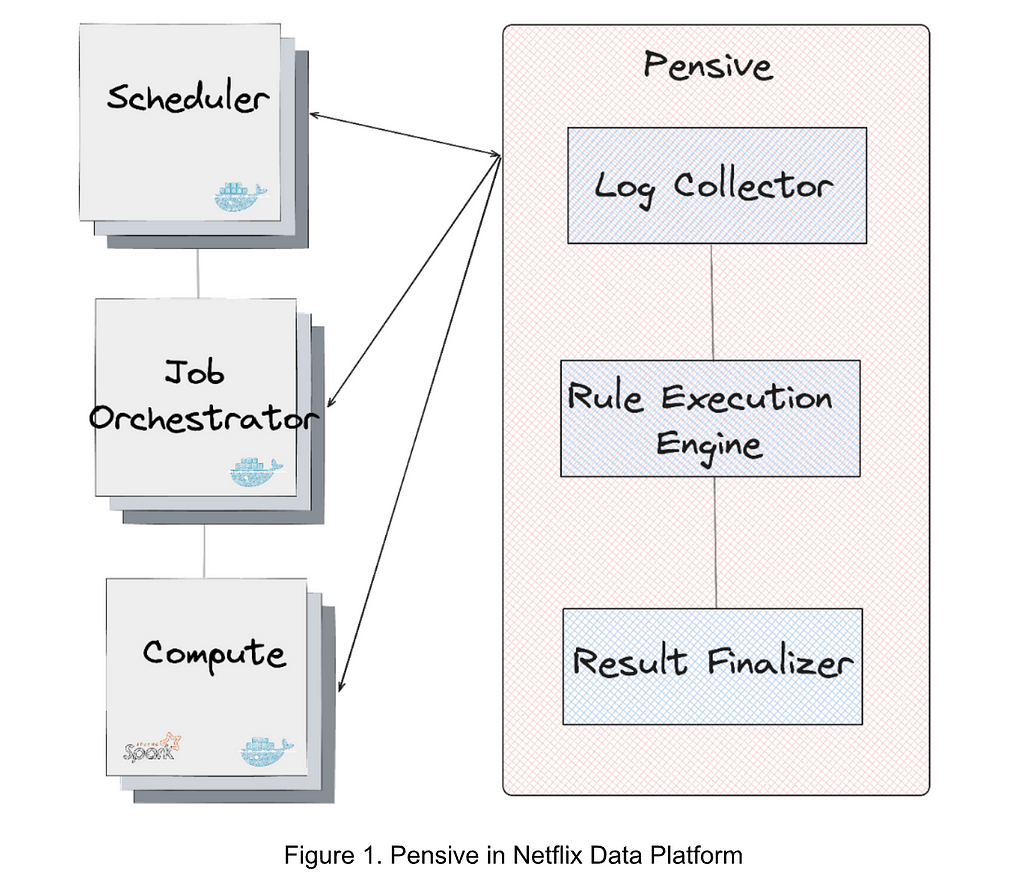
Figure 1 illustrates the error classification service, i.e., Pensive, in the data platform. It leverages the rule-based classifier and is composed of three components:
- Log Collector is responsible for pulling logs from different platform layers for error classification (e.g., the scheduler, job orchestrator, and compute clusters).
- Rule Execution Engine is responsible for matching the collected logs against a set of predefined rules. A rule includes (1) the name, source, log, and summary, of the error and whether the error is restartable; and (2) the regex to identify the error from the log. For example, the rule with the name SparkDriverOOM includes the information indicating that if the stdout log of a Spark job can match the regex SparkOutOfMemoryError:, then this error is classified to be a user error, not restartable.
- Result Finalizer is responsible for finalizing the error classification result based on the matched rules. If one or multiple rules are matched, then the classification of the first matched rule determines the final classification result (the rule priority is determined by the rule ordering, and the first rule has the highest priority). On the other hand, if no rules are matched, then this error will be considered unclassified.
Challenges
While the rule-based classifier is simple and has been effective, it is facing challenges due to its limited ability to handle the errors caused by misconfigurations and classify new errors:
- Memory configuration errors. The rules-based classifier provides error classification results indicating whether to restart the job; however, for non-transient errors, it still relies on engineers to manually remediate the job. The most notable example is memory configuration errors. Such errors are generally caused by the misconfiguration of job memory. Setting an excessively small memory can result in Out-Of-Memory (OOM) errors while setting an excessively large memory can waste cluster memory resources. What’s more challenging is that some memory configuration errors require changing the configurations of multiple parameters. Thus, setting a proper memory configuration requires not only the manual operation but also the expertise of Spark job execution. In addition, even if a job’s memory configuration is initially well tuned, changes such as data size and job definition can cause performance to degrade. Given that about 600 memory configuration errors per month are observed in the data platform, timely remediation of memory configuration errors alone requires non-trivial engineering efforts.
- Unclassified errors. The rule-based classifier relies on data platform engineers to manually add rules for recognizing errors based on the known context; otherwise, the errors will be unclassified. Due to the migrations of different layers of the data platform and the diversity of applications, existing rules can be invalid, and adding new rules requires engineering efforts and also depends on the deployment cycle. More than 300 rules have been added to the classifier, yet about 50% of all failures remain unclassified. For unclassified errors, the job may be retried multiple times with the default retry policy. If the error is non-transient, these failed retries incur unnecessary job running costs.
Evolving to Auto Remediation: Service Architecture
Methodology
To address the above-mentioned challenges, our basic methodology is to integrate the rule-based classifier with an ML service to generate recommendations, and use a configuration service to apply the recommendations automatically:
- Generating recommendations. We use the rule-based classifier as the first pass to classify all errors based on predefined rules, and the ML service as the second pass to provide recommendations for memory configuration errors and unclassified errors.
- Applying recommendations. We use an online configuration service to store and apply the recommended configurations. The pipeline is fully automated, and the services used to generate and apply recommendations are decoupled.
Service Integrations
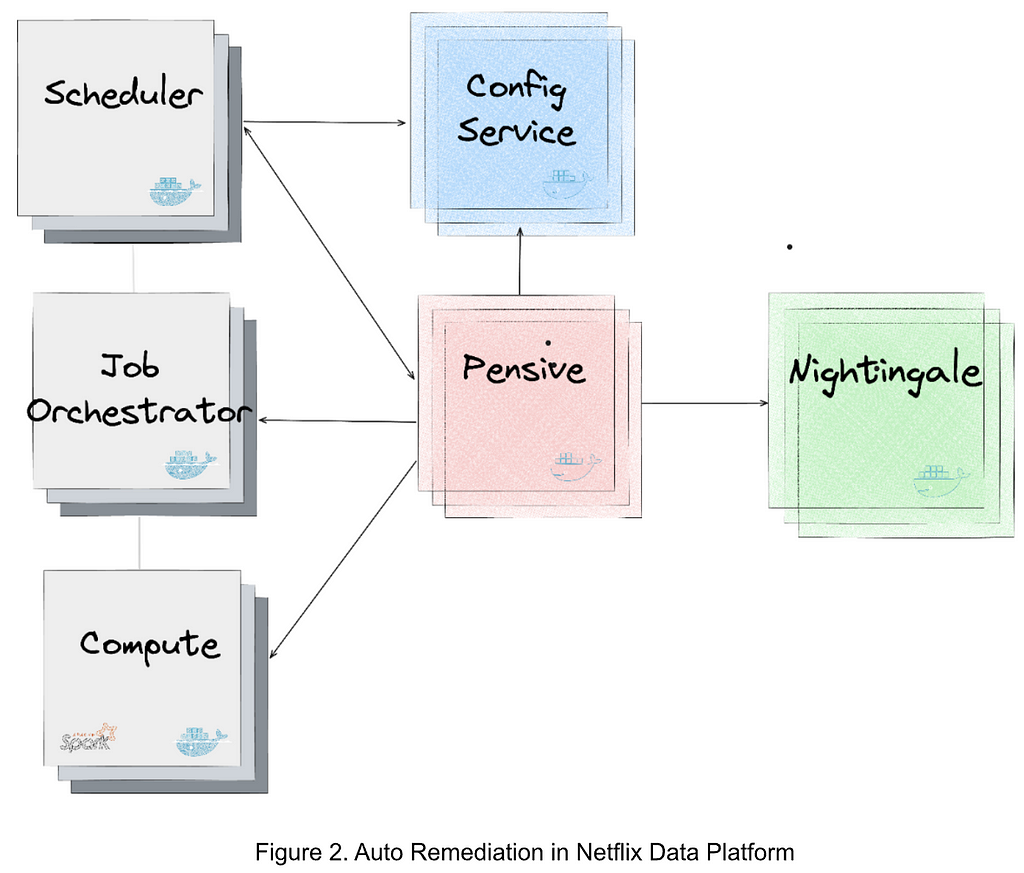
Figure 2 illustrates the integration of the services generating and applying the recommendations in the data platform. The major services are as follows:
- Nightingale is a service running the ML model trained using Metaflow and is responsible for generating a retry recommendation. The recommendation includes (1) whether the error is restartable; and (2) if so, the recommended configurations to restart the job.
- ConfigService is an online configuration service. The recommended configurations are saved in ConfigService as a JSON patch with a scope defined to specify the jobs that can use the recommended configurations. When Scheduler calls ConfigService to get recommended configurations, Scheduler passes the original configurations to ConfigService and ConfigService returns the mutated configurations by applying the JSON patch to the original configurations. Scheduler can then restart the job with the mutated configurations (including the recommended configurations).
- Pensive is an error classification service that leverages the rule-based classifier. It calls Nightingale to get recommendations and stores the recommendations to ConfigService so that it can be picked up by Scheduler to restart the job.
- Scheduler is the service scheduling jobs (our current implementation is with Netflix Maestro). Each time when a job fails, it calls Pensive to get the error classification to decide whether to restart a job and calls ConfigServices to get the recommended configurations for restarting the job.
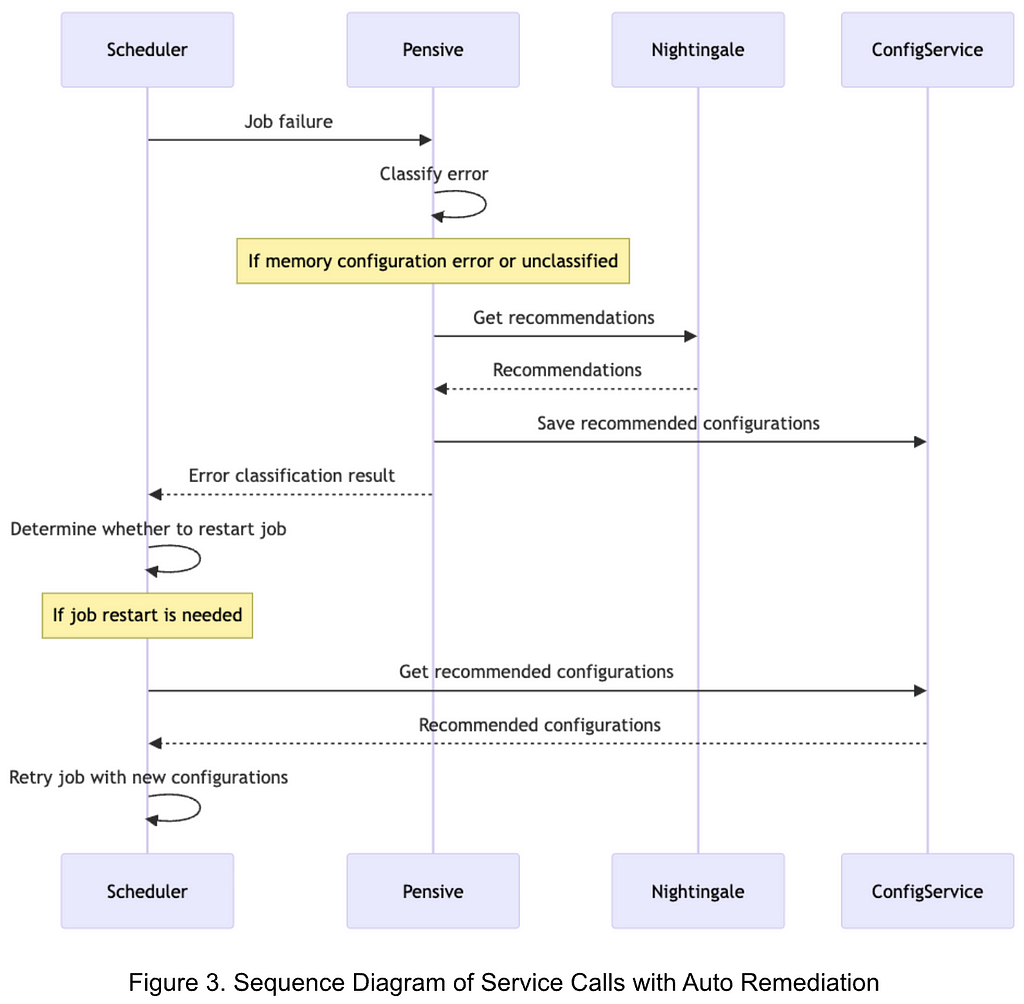
Figure 3 illustrates the sequence of service calls with Auto Remediation:
- Upon a job failure, Scheduler calls Pensive to get the error classification.
- Pensive classifies the error based on the rule-based classifier. If the error is identified to be a memory configuration error or an unclassified error, it calls Nightingale to get recommendations.
- With the obtained recommendations, Pensive updates the error classification result and saves the recommended configurations to ConfigService; and then returns the error classification result to Scheduler.
- Based on the error classification result received from Pensive, Scheduler determines whether to restart the job.
- Before restarting the job, Scheduler calls ConfigService to get the recommended configuration and retries the job with the new configuration.
Evolving to Auto Remediation: ML Service
Overview
The ML service, i.e., Nightingale, aims to generate a retry policy for a failed job that trades off between retry success probability and job running costs. It consists of two major components:
- A prediction model that jointly estimates a) probability of retry success, and b) retry cost in dollars, conditional on properties of the retry.
- An optimizer which explores the Spark configuration parameter space to recommend a configuration which minimizes a linear combination of retry failure probability and cost.
The prediction model is retrained offline daily, and is called by the optimizer to evaluate each candidate set of configuration parameter values. The optimizer runs in a RESTful service which is called upon job failure. If there is a feasible configuration solution from the optimization, the response includes this recommendation, which ConfigService uses to mutate the configuration for the retry. If there is no feasible solution–in other words, it is unlikely the retry will succeed by changing Spark configuration parameters alone–the response includes a flag to disable retries and thus eliminate wasted compute cost.
Prediction Model
Given that we want to explore how retry success and retry cost might change under different configuration scenarios, we need some way to predict these two values using the information we have about the job. Data Platform logs both retry success outcome and execution cost, giving us reliable labels to work with. Since we use a shared feature set to predict both targets, have good labels, and need to run inference quickly online to meet SLOs, we decided to formulate the problem as a multi-output supervised learning task. In particular, we use a simple Feedforward Multilayer Perceptron (MLP) with two heads, one to predict each outcome.
Training: Each record in the training set represents a potential retry which previously failed due to memory configuration errors or unclassified errors. The labels are: a) did retry fail, b) retry cost. The raw feature inputs are largely unstructured metadata about the job such as the Spark execution plan, the user who ran it, and the Spark configuration parameters and other job properties. We split these features into those that can be parsed into numeric values (e.g., Spark executor memory parameter) and those that cannot (e.g., user name). We used feature hashing to process the non-numeric values because they come from a high cardinality and dynamic set of values. We then create a lower dimensionality embedding which is concatenated with the normalized numeric values and passed through several more layers.
Inference: Upon passing validation audits, each new model version is stored in Metaflow Hosting, a service provided by our internal ML Platform. The optimizer makes several calls to the model prediction function for each incoming configuration recommendation request, described in more detail below.
Optimizer
When a job attempt fails, it sends a request to Nightingale with a job identifier. From this identifier, the service constructs the feature vector to be used in inference calls. As described previously, some of these features are Spark configuration parameters which are candidates to be mutated (e.g., spark.executor.memory, spark.executor.cores). The set of Spark configuration parameters was based on distilled knowledge of domain experts who work on Spark performance tuning extensively. We use Bayesian Optimization (implemented via Meta’s Ax library) to explore the configuration space and generate a recommendation. At each iteration, the optimizer generates a candidate parameter value combination (e.g., spark.executor.memory=7192 mb, spark.executor.cores=8), then evaluates that candidate by calling the prediction model to estimate retry failure probability and cost using the candidate configuration (i.e., mutating their values in the feature vector). After a fixed number of iterations is exhausted, the optimizer returns the “best” configuration solution (i.e., that which minimized the combined retry failure and cost objective) for ConfigService to use if it is feasible. If no feasible solution is found, we disable retries.
One downside of the iterative design of the optimizer is that any bottleneck can block completion and cause a timeout, which we initially observed in a non-trivial number of cases. Upon further profiling, we found that most of the latency came from the candidate generated step (i.e., figuring out which directions to step in the configuration space after the previous iteration’s evaluation results). We found that this issue had been raised to Ax library owners, who added GPU acceleration options in their API. Leveraging this option decreased our timeout rate substantially.
Rollout in Production
We have deployed Auto Remediation in production to handle memory configuration errors and unclassified errors for Spark jobs. Besides the retry success probability and cost efficiency, the impact on user experience is the major concern:
- For memory configuration errors: Auto remediation improves user experience because the job retry is rarely successful without a new configuration for memory configuration errors. This means that a successful retry with the recommended configurations can reduce the operational loads and save job running costs, while a failed retry does not make the user experience worse.
- For unclassified errors: Auto remediation recommends whether to restart the job if the error cannot be classified by existing rules in the rule-based classifier. In particular, if the ML model predicts that the retry is very likely to fail, it will recommend disabling the retry, which can save the job running costs for unnecessary retries. For cases in which the job is business-critical and the user prefers always retrying the job even if the retry success probability is low, we can add a new rule to the rule-based classifier so that the same error will be classified by the rule-based classifier next time, skipping the recommendations of the ML service. This presents the advantages of the integrated intelligence of the rule-based classifier and the ML service.
The deployment in production has demonstrated that Auto Remediation can provide effective configurations for memory configuration errors, successfully remediating about 56% of all memory configuration without human intervention. It also decreases compute cost of these jobs by about 50% because it can either recommend new configurations to make the retry successful or disable unnecessary retries. As tradeoffs between performance and cost efficiency are tunable, we can decide to achieve a higher success rate or more cost savings by tuning the ML service.
It is worth noting that the ML service is currently adopting a conservative policy to disable retries. As discussed above, this is to avoid the impact on the cases that users prefer always retrying the job upon job failures. Although these cases are expected and can be addressed by adding new rules to the rule-based classifier, we consider tuning the objective function in an incremental manner to gradually disable more retries is helpful to provide desirable user experience. Given the current policy to disable retries is conservative, Auto Remediation presents a great potential to eventually bring much more cost savings without affecting the user experience.
Beyond Error Handling: Towards Right Sizing
Auto Remediation is our first step in leveraging data insights and Machine Learning (ML) for improving user experience, reducing the operational burden, and improving cost efficiency of the data platform. It focuses on automating the remediation of failed jobs, but also paves the path to automate operations other than error handling.
One of the initiatives we are taking, called Right Sizing, is to reconfigure scheduled big data jobs to request the proper resources for job execution. For example, we have noted that the average requested executor memory of Spark jobs is about four times their max used memory, indicating a significant overprovision. In addition to the configurations of the job itself, the resource overprovision of the container that is requested to execute the job can also be reduced for cost savings. With heuristic- and ML-based methods, we can infer the proper configurations of job execution to minimize resource overprovisions and save millions of dollars per year without affecting the performance. Similar to Auto Remediation, these configurations can be automatically applied via ConfigService without human intervention. Right Sizing is in progress and will be covered with more details in a dedicated technical blog post later. Stay tuned.
Acknowledgements
Auto Remediation is a joint work of the engineers from different teams and organizations. This work would have not been possible without the solid, in-depth collaborations. We would like to appreciate all folks, including Spark experts, data scientists, ML engineers, the scheduler and job orchestrator engineers, data engineers, and support engineers, for sharing the context and providing constructive suggestions and valuable feedback (e.g., John Zhuge, Jun He, Holden Karau, Samarth Jain, Julian Jaffe, Batul Shajapurwala, Michael Sachs, Faisal Siddiqi).
![]()
Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data… was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.