This blog post is co-written with Chaoyang He and Salman Avestimehr from FedML.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed data silos, lack of sufficient data at any single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository. Because they are in a highly regulated domain, HCLS partners and customers seek privacy-preserving mechanisms to manage and analyze large-scale, distributed, and sensitive data.
To mitigate these challenges, we propose using an open-source federated learning (FL) framework called FedML, which enables you to analyze sensitive HCLS data by training a global machine learning model from distributed data held locally at different sites. FL doesn’t require moving or sharing data across sites or with a centralized server during the model training process.
In this two-part series, we demonstrate how you can deploy a cloud-based FL framework on AWS. In the first post, we described FL concepts and the FedML framework. In the second post, we present the use cases and dataset to show its effectiveness in analyzing real-world healthcare datasets, such as the eICU data, which comprises a multi-center critical care database collected from over 200 hospitals.
Background
Although the volume of HCLS-generated data has never been greater, the challenges and constraints associated with accessing such data limits its utility for future research. Machine learning (ML) presents an opportunity to address some of these concerns and is being adopted to advance data analytics and derive meaningful insights from diverse HCLS data for use cases like care delivery, clinical decision support, precision medicine, triage and diagnosis, and chronic care management. Because ML algorithms are often not adequate in protecting the privacy of patient-level data, there is a growing interest among HCLS partners and customers to use privacy-preserving mechanisms and infrastructure for managing and analyzing large-scale, distributed, and sensitive data. [1]
We have developed an FL framework on AWS that enables analyzing distributed and sensitive health data in a privacy-preserving manner. It involves training a shared ML model without moving or sharing data across sites or with a centralized server during the model training process, and can be implemented across multiple AWS accounts. Participants can either choose to maintain their data in their on-premises systems or in an AWS account that they control. Therefore, it brings analytics to data, rather than moving data to analytics.
In this post, we showed how you can deploy the open-source FedML framework on AWS. We test the framework on eICU data, a multi-center critical care database collected from over 200 hospitals, to predict in-hospital patient mortality. We can use this FL framework to analyze other datasets, including genomic and life sciences data. It can also be adopted by other domains that are rife with distributed and sensitive data, including finance and education sectors.
Federated learning
Advancements in technology have led to an explosive growth of data across industries, including HCLS. HCLS organizations often store data in siloes. This poses a major challenge in data-driven learning, which requires large datasets to generalize well and achieve the desired level of performance. Moreover, gathering, curating, and maintaining high-quality datasets incur significant time and cost.
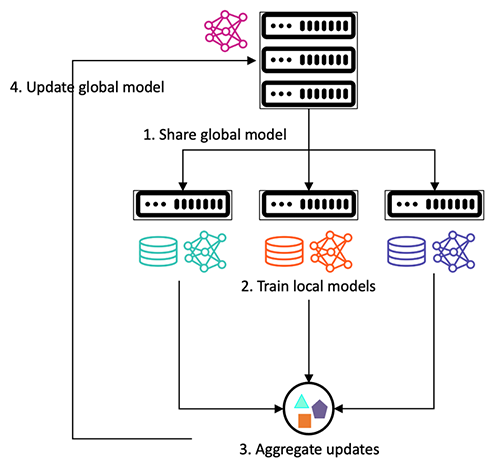
Federated learning mitigates these challenges by collaboratively training ML models that use distributed data, without the need to share or centralize them. It allows diverse sites to be represented within the final model, reducing the potential risk for site-based bias. The framework follows a client-server architecture, where the server shares a global model with the clients. The clients train the model based on local data and share parameters (such as gradients or model weights) with the server. The server aggregates these parameters to update the global model, which is then shared with the clients for next round of training, as shown in the following figure. This iterative process of model training continues until the global model converges.

Iterative process of model training
In recent years, this new learning paradigm has been successfully adopted to address the concern of data governance in training ML models. One such effort is MELLODDY, an Innovative Medicines Initiative (IMI)-led consortium, powered by AWS. It’s a 3-year program involving 10 pharmaceutical companies, 2 academic institutions, and 3 technology partners. Its primary goal is to develop a multi-task FL framework to improve the predictive performance and chemical applicability of drug discovery-based models. The platform comprises multiple AWS accounts, with each pharma partner retaining full control of their respective accounts to maintain their private datasets, and a central ML account coordinating the model training tasks.
The consortium trained models on billions of data points, consisting of over 20 million small molecules in over 40,000 biological assays. Based on experimental results, the collaborative models demonstrated a 4% improvement in categorizing molecules as either pharmacologically or toxicologically active or inactive. It also led to a 10% increase in its ability to yield confident predictions when applied to new types of molecules. Finally, the collaborative models were typically 2% better at estimating values of toxicological and pharmacological activities.
FedML
FedML is an open-source library to facilitate FL algorithm development. It supports three computing paradigms: on-device training for edge devices, distributed computing, and single-machine simulation. It also offers diverse algorithmic research with flexible and generic API design and comprehensive reference baseline implementations (optimizer, models, and datasets). For a detailed description of the FedML library, refer to FedML.
The following figure presents the open-source library architecture of FedML.

Open-source library architecture of FedML
As seen in the preceding figure, from the application point of view, FedML shields details of the underlying code and complex configurations of distributed training. At the application level, such as computer vision, natural language processing, and data mining, data scientists and engineers only need to write the model, data, and trainer in the same way as a standalone program and then pass it to the FedMLRunner object to complete all the processes, as shown in the following code. This greatly reduces the overhead for application developers to perform FL.
The FedML algorithm is still a work in progress and constantly being improved. To this end, FedML abstracts the core trainer and aggregator and provides users with two abstract objects, FedML.core.ClientTrainer and FedML.core.ServerAggregator, which only need to inherit the interfaces of these two abstract objects and pass them to FedMLRunner. Such customization provides ML developers with maximum flexibility. You can define arbitrary model structures, optimizers, loss functions, and more. These customizations can also be seamlessly connected with the open-source community, open platform, and application ecology mentioned earlier with the help of FedMLRunner, which completely solves the long lag problem from innovative algorithms to commercialization.
Finally, as shown in the preceding figure, FedML supports distributed computing processes, such as complex security protocols and distributed training as a Directed Acyclic Graph (DAG) flow computing process, making the writing of complex protocols similar to standalone programs. Based on this idea, the security protocol Flow Layer 1 and the ML algorithm process Flow Layer 2 can be easily separated so that security engineers and ML engineers can operate while maintaining a modular architecture.
The FedML open-source library supports federated ML use cases for edge as well as cloud. On the edge, the framework facilitates training and deployment of edge models to mobile phones and internet of things (IoT) devices. In the cloud, it enables global collaborative ML, including multi-Region, and multi-tenant public cloud aggregation servers, as well as private cloud deployment in Docker mode. The framework addresses key concerns with regards to privacy-preserving FL such as security, privacy, efficiency, weak supervision, and fairness.
Conclusion
In this post, we showed how you can deploy the open-source FedML framework on AWS. This allows you to train an ML model on distributed data, without the need to share or move it. We set up a multi-account architecture, where in a real-world scenario, organizations can join the ecosystem to benefit from collaborative learning while maintaining data governance. In the next post, we use the multi-hospital eICU dataset to demonstrate its effectiveness in a real-world scenario.
Please review the presentation at re:MARS 2022 focused on “Managed Federated Learning on AWS: A case study for healthcare” for a detailed walkthrough of this solution.
Reference
[1] Kaissis, G.A., Makowski, M.R., Rückert, D. et al. Secure, privacy-preserving and federated machine learning in medical imaging. Nat Mach Intell 2, 305–311 (2020). https://doi.org/10.1038/s42256-020-0186-1
[2] FedML https://fedml.ai
About the Authors
 Olivia Choudhury, PhD, is a Senior Partner Solutions Architect at AWS. She helps partners, in the Healthcare and Life Sciences domain, design, develop, and scale state-of-the-art solutions leveraging AWS. She has a background in genomics, healthcare analytics, federated learning, and privacy-preserving machine learning. Outside of work, she plays board games, paints landscapes, and collects manga.
Olivia Choudhury, PhD, is a Senior Partner Solutions Architect at AWS. She helps partners, in the Healthcare and Life Sciences domain, design, develop, and scale state-of-the-art solutions leveraging AWS. She has a background in genomics, healthcare analytics, federated learning, and privacy-preserving machine learning. Outside of work, she plays board games, paints landscapes, and collects manga.
 Vidya Sagar Ravipati is a Manager at the Amazon ML Solutions Lab, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption. Previously, he was a Machine Learning Engineer in Connectivity Services at Amazon who helped to build personalization and predictive maintenance platforms.
Vidya Sagar Ravipati is a Manager at the Amazon ML Solutions Lab, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption. Previously, he was a Machine Learning Engineer in Connectivity Services at Amazon who helped to build personalization and predictive maintenance platforms.
 Wajahat Aziz is a Principal Machine Learning and HPC Solutions Architect at AWS, where he focuses on helping healthcare and life sciences customers leverage AWS technologies for developing state-of-the-art ML and HPC solutions for a wide variety of use cases such as Drug Development, Clinical Trials, and Privacy Preserving Machine Learning. Outside of work, Wajahat likes to explore nature, hiking, and reading.
Wajahat Aziz is a Principal Machine Learning and HPC Solutions Architect at AWS, where he focuses on helping healthcare and life sciences customers leverage AWS technologies for developing state-of-the-art ML and HPC solutions for a wide variety of use cases such as Drug Development, Clinical Trials, and Privacy Preserving Machine Learning. Outside of work, Wajahat likes to explore nature, hiking, and reading.
 Divya Bhargavi is a Data Scientist and Media and Entertainment Vertical Lead at the Amazon ML Solutions Lab, where she solves high-value business problems for AWS customers using Machine Learning. She works on image/video understanding, knowledge graph recommendation systems, predictive advertising use cases.
Divya Bhargavi is a Data Scientist and Media and Entertainment Vertical Lead at the Amazon ML Solutions Lab, where she solves high-value business problems for AWS customers using Machine Learning. She works on image/video understanding, knowledge graph recommendation systems, predictive advertising use cases.
 Ujjwal Ratan is the leader for AI/ML and Data Science in the AWS Healthcare and Life Science Business Unit and is also a Principal AI/ML Solutions Architect. Over the years, Ujjwal has been a thought leader in the healthcare and life sciences industry, helping multiple Global Fortune 500 organizations achieve their innovation goals by adopting machine learning. His work involving the analysis of medical imaging, unstructured clinical text and genomics has helped AWS build products and services that provide highly personalized and precisely targeted diagnostics and therapeutics. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.
Ujjwal Ratan is the leader for AI/ML and Data Science in the AWS Healthcare and Life Science Business Unit and is also a Principal AI/ML Solutions Architect. Over the years, Ujjwal has been a thought leader in the healthcare and life sciences industry, helping multiple Global Fortune 500 organizations achieve their innovation goals by adopting machine learning. His work involving the analysis of medical imaging, unstructured clinical text and genomics has helped AWS build products and services that provide highly personalized and precisely targeted diagnostics and therapeutics. In his free time, he enjoys listening to (and playing) music and taking unplanned road trips with his family.
 Chaoyang He is Co-founder and CTO of FedML, Inc., a startup running for a community building open and collaborative AI from anywhere at any scale. His research focuses on distributed/federated machine learning algorithms, systems, and applications. He received his Ph.D. in Computer Science from the University of Southern California, Los Angeles, USA.
Chaoyang He is Co-founder and CTO of FedML, Inc., a startup running for a community building open and collaborative AI from anywhere at any scale. His research focuses on distributed/federated machine learning algorithms, systems, and applications. He received his Ph.D. in Computer Science from the University of Southern California, Los Angeles, USA.
 Salman Avestimehr is Professor, the inaugural director of the USC-Amazon Center for Secure and Trusted Machine Learning (Trusted AI), and the director of the Information Theory and Machine Learning (vITAL) research lab at the Electrical and Computer Engineering Department and Computer Science Department of University of Southern California. He is also the co-founder and CEO of FedML. He received my Ph.D. in Electrical Engineering and Computer Sciences from UC Berkeley in 2008. His research focuses on the areas of information theory, decentralized and federated machine learning, secure and privacy-preserving learning and computing.
Salman Avestimehr is Professor, the inaugural director of the USC-Amazon Center for Secure and Trusted Machine Learning (Trusted AI), and the director of the Information Theory and Machine Learning (vITAL) research lab at the Electrical and Computer Engineering Department and Computer Science Department of University of Southern California. He is also the co-founder and CEO of FedML. He received my Ph.D. in Electrical Engineering and Computer Sciences from UC Berkeley in 2008. His research focuses on the areas of information theory, decentralized and federated machine learning, secure and privacy-preserving learning and computing.