
Turning images of damaged vehicles into accurate claims information is critical for insurance agencies. For that reason, KASIKORN Business-Technology Group (KBTG) Labs, a leading tech company in Thailand, is using Machine learning (ML) technology to help speed up this process, and ensure the accuracy of every claim.
KBTG worked with Muang Thai Insurance PCL (MTI), an insurance company in Thailand that provides fire, marine, and automobile insurance. When a vehicle is damaged in an accident the repair shop typically assesses the damage and submits a claim to the insurance company for processing. These claims are validated by the insurance company and then processed with intermediaries that validate the claims and submit photos as proof.
Currently, this complete process of assessing the damage and evaluating the claim is completely manual, which slows down processing time and is expensive, because multiple partners and intermediaries are involved. To address this issue, KBTG Labs worked with Google Cloud to devise a solution to this problem.
Building a solution architecture
The existing dataset used for claims processing had many data quality and quantity challenges, For example, some images might be taken from too far a distance or too close to identify the specific area of damage, or the descriptions may be incorrect.

To resolve this problem, Google Cloud proposed a solution architecture that leverages a cascaded model approach, including image quality assessment.
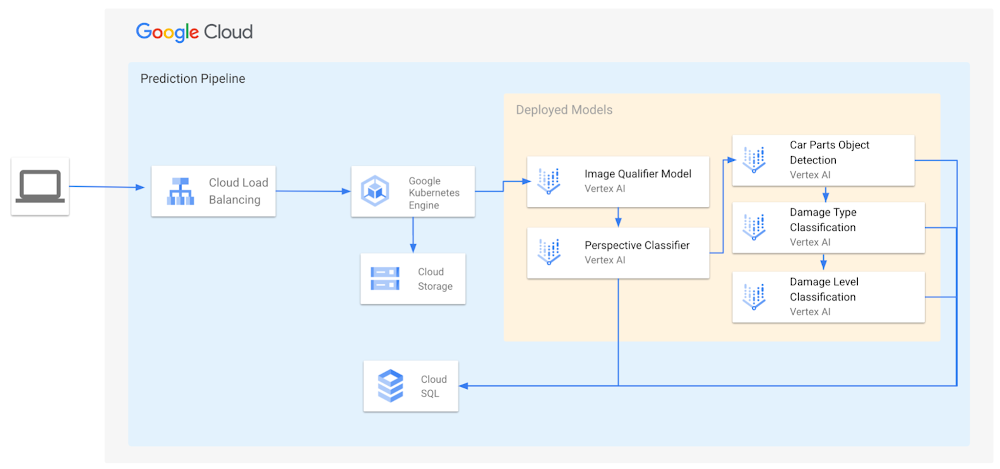
The inference pipeline depicted above is designed for scalability, high availability, and fault tolerance. A microservice for execution, model selection based on inputs and outputs of the intermediary models is served by Google Kubernetes Engine. The images are then stored on Cloud Storage and sent for prediction in a bucket, to be labeled later and consumed in continuous training. Cloud SQL stores the results for the inference and analytics. The Image Qualifier model uses Vertex AI to classify the input image into a good or bad image. This model type is intended to act as a filter for the image quality for the model inference and streamline the process for only executing the model if the image conforms to intended image quality standards.
Experimenting with different images
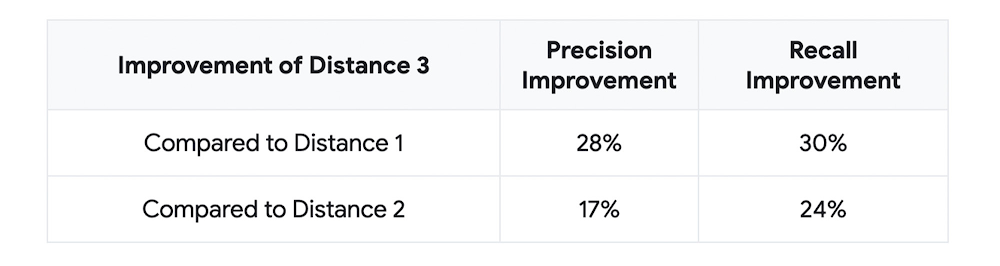
Google Cloud’s proposed architecture includes an Image Qualifier model that identifies which images are suitable for ML and which are not, as mentioned above. Later in the project, the team ran experiments by distinguishing “good” and “bad” images in this model. Through this analysis, the team found that distance was one of the most important factors in the images, and that using images with the appropriate Distance metric successfully improved metrics such as Precision and Recall of the ML model by about 30%. The table below shows the results from the experiments.
Note :
Distance 1 = image does not show the whole car but many car parts are visible (i.e., more close-up than label 0, which is appropriate for images in which the entire vehicle is visible)
Distance 2 = images focuses only one main part in the middle of image (i.e., more close-up than label 1)
Distance 3 = images cannot be used to identify the car part because it’s shot from a very, very close-up distance
Improving model predictions with Explainable AI
To gain further explanatory power in image classification, the team used a Google Cloud product called Explainable AI. Explainable AI is a feature of Vertex AI that enables users to generate “feature attributions” or “feature importance” values for their model’s predictions. Feature attributions are an explainability method that show users how much each input feature contributes to their model’s predictions and to the model’s overall predictive power.

Below is a True Positive example of a break defect. In other words, it is an example where ML was able to correctly predict the image of an image of a break as a legitimate break. But as you can see in the images, the light is reflected in all examples. Explainable AI concentrates green dots on the areas where the car light is and the break defect is judged based on the lit up parts by Explainable AI.

Initially, the intended architecture considered damage classification separately from object detection. However, by providing insights that explained the model’s behavior and how to optimize its performance, these results showed that damage identification should be done with object detection in order to avoid the influence of objects in the background of the damage as much as possible.
Key learnings and improvements as next steps
Explainable AI revealed that the ML model focuses on not only the damage, but also the damaged object itself. From this result, we hypothesize that damage itself is more effective for object detection than learning via only a simple classification model.
Through this project, it was discovered that the distance at which an object is photographed is critical to detecting vehicle damage, and that it is important to eliminate the influence of objects in the background as much as possible. Based on these results, we would like to assess the results of the experiment, including the object detection process.
To learn more about what Vertex AI can do for your business, visit our product page, and to learn more about Explainable AI, click here.