The recent growth in distributed, compute-intensive ML applications has prompted data scientists and ML practitioners to find easy ways to prototype and develop their ML models. Running your Jupyter notebooks and JupyterHub on Google Kubernetes Engine (GKE) can provide a way to run your solution with security and scalability built-in as core elements of the platform.
GKE is a managed container orchestration service that provides a scalable and flexible platform for deploying and managing containerized applications. GKE abstracts away the underlying infrastructure, making it easy to deploy and manage complex deployments.
Jupyterhub is a powerful, multi-tenant server-based web application that allows users to interact with and collaborate on Jupyter notebooks. Users can create custom computing environments with custom images and computational resources in which to run their notebooks. “Zero to Jupyterhub for Kubernetes” (z2jh) is a Helm chart that you can use to install Jupyterhub on Kubernetes that provides numerous configurations for complex user scenarios.
We are excited to announce a solution template that will help you get started with Jupyterhub on GKE. This greatly simplifies the use of z2jh with GKE templates, offering a quick and easy way to set up Jupyterhub by providing a pre-configured GKE cluster, Jupyterhub config, and custom features. Further, we added features such as authentication and persistent storage and cut down the complexity for model prototyping and experimentation. In this blog post, we discuss the solution template, the Jupyterhub on GKE experience, unique characteristics that come from running on GKE, and features such as a custom authentication and persistent storage.
The Jupyter on GKE experience
Running Zero to Jupyterhub on GKE provides a powerful platform for ML applications but the installation process is complicated. To ensure ML practitioners have minimal friction, our solution templates abstract away the infrastructure setup and solve common enterprise platform challenges including authentication and security, and persistent storage for notebooks.
Security and Auth
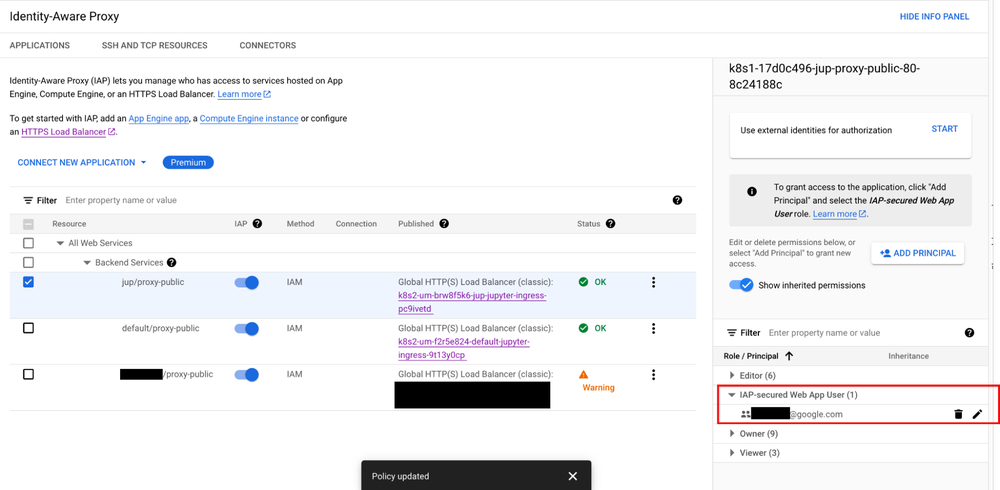
Granting the correct access to the notebooks can be especially difficult when working with sensitive data. By default, Jupyterhub exposes a public endpoint that anyone can access. This endpoint should be locked down to prevent unintended access. Our solution leverages Identity-Aware Proxy (IAP) to gate access to the public endpoint. IAP creates a central authorization layer for the Jupyterhub application access by HTTPS, utilizing the application-level access model and enabling IAM-based access control to the notebook to make users’ data more secure. Adding authentication to Jupyterhub ensures user validity and notebook security.
By default, the template reserves an IP address through Google Cloud IAP. Platform administrators can alternatively provide a domain to host their Jupyterhub endpoint, which will be guarded by IAP. Once IAP is configured, the platform administrator must update the service allowlist by granting users the role of “IAP-secure Web App User.” You can see how to allow access to the deployed Jupyterhub in the image below and as described here:
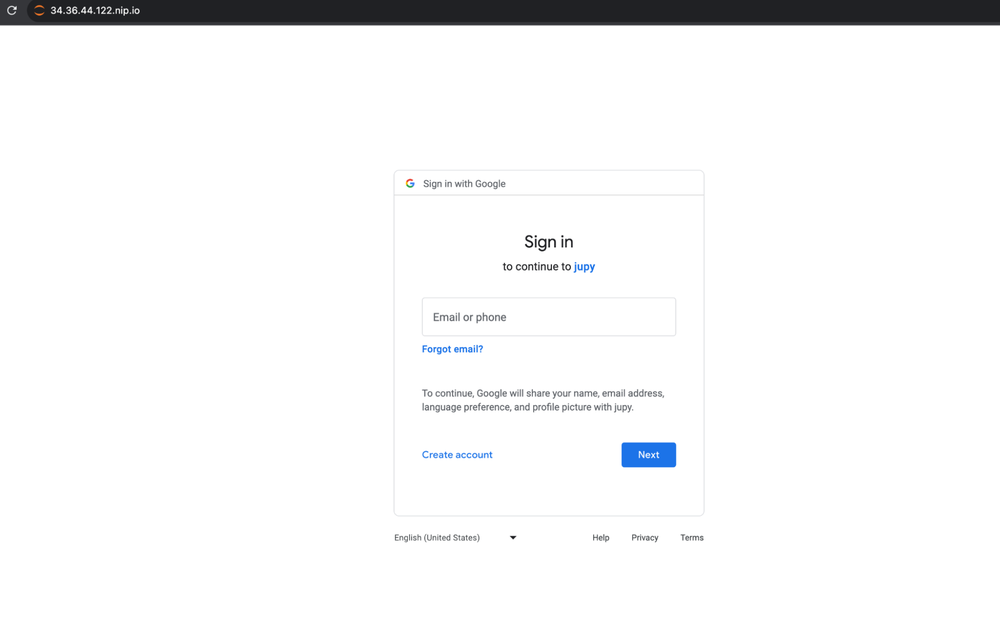
Now when a user navigates to the Jupyterhub endpoint gated behind IAP, they are presented with a Google login screen (shown below) to log in with their Google identity.
Persistent storage
Running Jupyterhub on GKE does not come with an out-of-the-box persistent storage solution, so notebooks are lost when the clusters are deleted. To persist notebook data, our templates provide options to integrate with Google storage solutions like Filestore, GCSFuse, andCompute Engine Persistent Disk. Each of these offer different features for different use cases:
- Filestore – Supports dynamic provisioning and standard POSIX. Although the persistent volumes come with a minimum size of 1Ti for the standard tier, they provide multishare support to optimize costs.
- GCSFuse – Uses Cloud Storage buckets as the persistent volume but requires manual bucket creation i.e., the platform engineer must provision a bucket for each user. Cloud Storage can be managed via the UI support in the Google Cloud console and access control can be configured via IAM.
- Compute Engine Persistent Disk – Supports dynamic provisioning and can automatically scale while supporting different disk types.
To learn more about storage solutions, check out this guide.
Solution overview
The solution template uses Terraform with Helm charts to provision JupyterHub. Follow the step-by-step instructions in the README file to get started. The solution contains two groups of resources: platform-level and jupyterhub-level.
Platform-level resources are expected to be deployed once for each development environment by the system administrator. This includes common infrastructure and Google Cloud service integrations that are shared by all users. System administrators can also reuse already deployed development environments as well.
- GKE Cluster and node pool – Configured in the main.tf file, this module deploys a GKE cluster with a GPU node pool. GKE also provides alternative GPU and machine types.
- Kubernetes System namespaces and service accounts, along with necessary IAM policy bindings.
The following resources are created when the system admins install Jupyterhub on the cluster. System administrators will be required to reinstall to apply any changes made to Jupyterhub configuration, i.e., the changes listed here.
- Jupyterhub z2jh server – Spins up Jupyter notebook environments for users.
- IAP-related k8s deployments – This includes the Ingress, Backend Configuration, and Managed Certificate that integrates Google Cloud IAP with Jupyterhub
- Depending on the user’s choice, storage volumes will be created by Filestore, GCSFuse, or Persistent Disk.
Customizable user profiles/resources
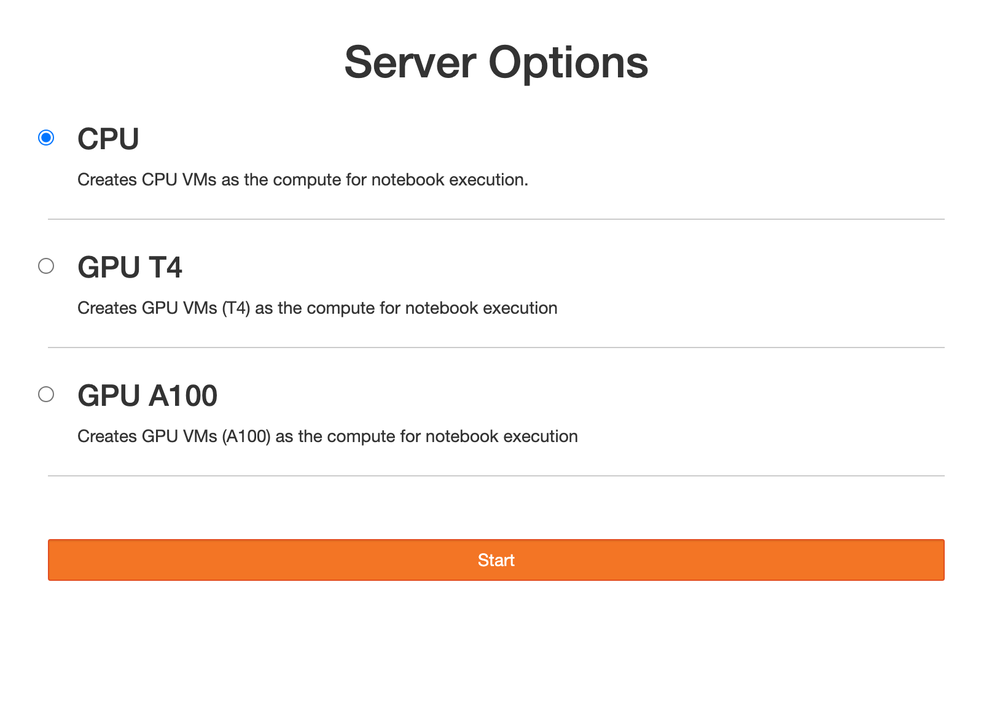
GKE’s flexible container customization and nodepool configurations work well with Jupyter’s concept of notebook profiles. Jupyterhub configuration offers a customizable number of preset profiles with predetermined Jupyter notebook images, memory, CPUs, GPUs, and many more. Using profiles, engineers can leverage GKE infrastructure like GPUs and TPUs to run their notebooks.
Better together: Jupyter and GKE
The combination of Jupyter and GKE offers a powerful yet simple solution for building, running, and managing AI workloads. Jupyterhub’s ease-of-use makes it a popular choice for machine learning models and data exploration. With GKE, Jupyterhub can go further by becoming more scalable and reliable.
You can also learn about running Jupyterhub with Ray here.
If you have any questions about using Jupyterhub with GKE, please raise an issue on our Github. Learn more about building AI Platforms with GKE by visiting our User Guide.