The pace of progress with AI model architectures is staggering, driven by breakthrough inventions such as Transformer, and by rapid growth in high-quality training data. In generative AI, for instance, large language models (LLMs) have been growing in size by as much as 10x per year. Organizations are deploying these AI models in their products and services, driving the exponential growth in demand for AI-accelerated computing for AI training and inference, to reliably and efficiently serve AI models to users across the world.
The latest MLPerf™ 3.1 Inference results1 showcase how Google’s systems breakthroughs enable our customers to keep pace with the ever-growing compute demands of the latest AI models. Google Cloud inference systems deliver between a factor of 2-4x performance improvement and more than a factor of 2x cost-efficiency improvement over existing offerings. At Google Cloud, we are proud to be the only cloud provider to offer a wide range of high-performance, cost-efficient, and scalable AI inference offerings powered by both NVIDIA GPUs and Google Cloud’s purpose-built Tensor Processor Units (TPUs).
GPU-accelerated AI inference on Google Cloud
Google Cloud and NVIDIA continue to partner to help bring the most advanced GPU-accelerated inference platform to our customers. In addition to the A2 VM powered by NVIDIA’s A100 GPU, we recently launched the G2 VM, the cloud industry’s first and only offering powered by the NVIDIA L4 Tensor Core GPU. In addition, our next-generation A3 VMs, powered by the H100 GPU, are in private preview and will be generally available in the next month. Google Cloud is the only cloud provider to offer all three of these NVIDIA-powered AI accelerators.
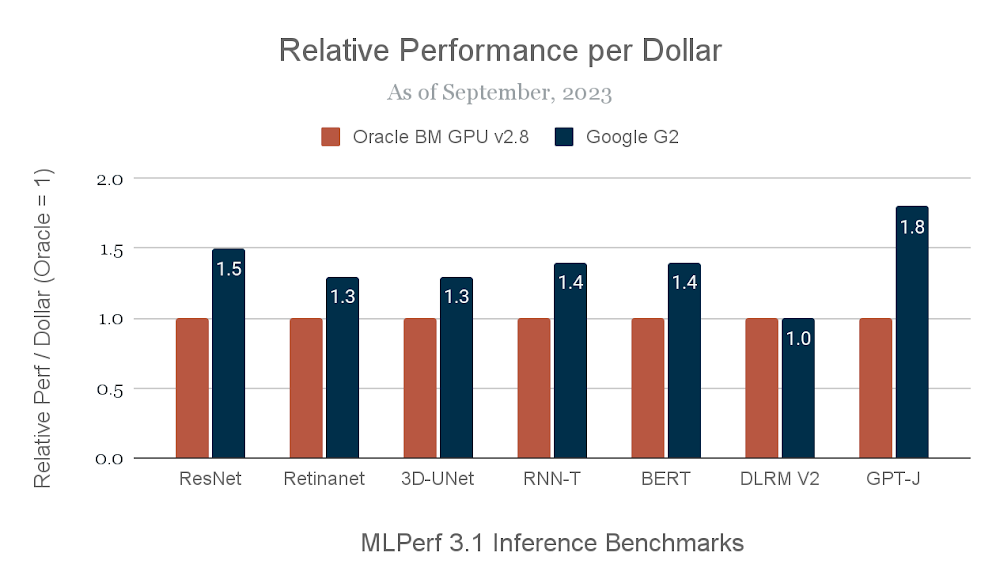
With the superb MLPerf™ 3.1 Inference Closed results of the H100 GPU, the A3 VM delivers between 1.7x-3.9x relative performance improvement over the A2 VM for demanding inference workloads. The Google Cloud G2 VM powered by the L4 GPU, meanwhile, is a great choice for customers looking to optimize inference cost-efficiency. NVIDIA’s MLPerf™ 3.1 results for the L4 GPU speak to G2’s strengths: up to 1.8x improvement in performance per dollar than a comparable public cloud inference offering. Google Cloud customers such as Bending Spoons are using G2 VMs to deploy new AI-powered experiences for their end users.
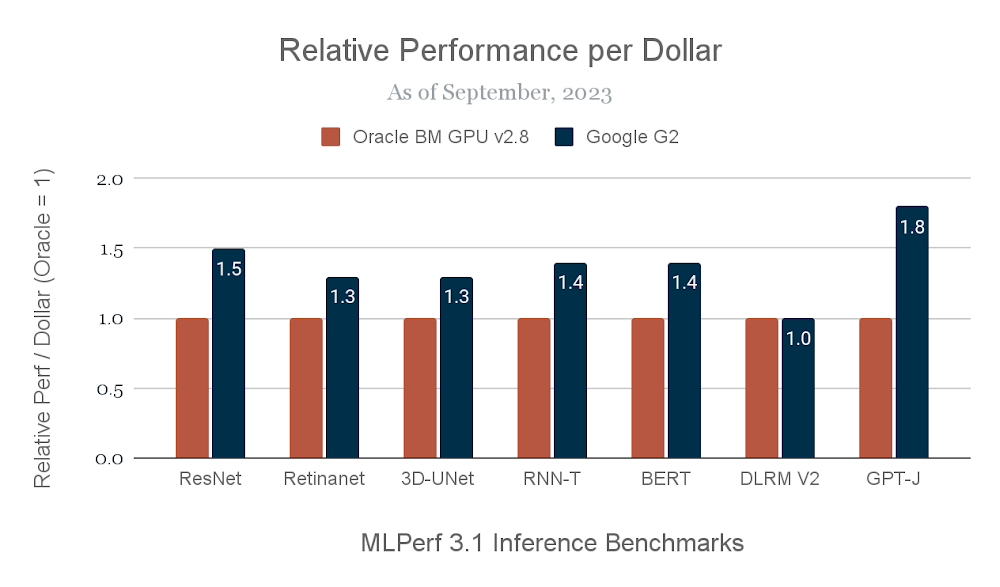
We derived our performance per dollar metrics, which we use throughout this blog post, from the results of MLPerf™ v3.1 Inference Closed. All prices are current at the time of publication. Performance per dollar is not an official MLPerf™ metric and is not verified by MLCommons® Association.
Cost-efficient AI inference at scale using Cloud TPUs
The new Cloud TPU v5e, announced at Google Cloud Next, enables high-performance and cost-effective inference for a broad range AI workloads, including the latest state-of-the-art LLMs and generative AI models. Designed to be efficient, scalable, and versatile, Cloud TPU v5e delivers high-throughput and low-latency inference performance. Each TPU v5e chip provides up to 393 trillion int8 operations per second (TOPS), allowing fast predictions for the most complex models.
Our high-speed inter-chip interconnect (ICI) allows Cloud TPU v5e to scale out to the largest models with multiple TPUs working in tight unison. Our MLPerf™ 3.1 inference results use four TPU v5e chips to run the 6-billion-parameter GPT-J LLM benchmark. TPU v5e delivers 2.7x higher performance per dollar compared to TPU v4:
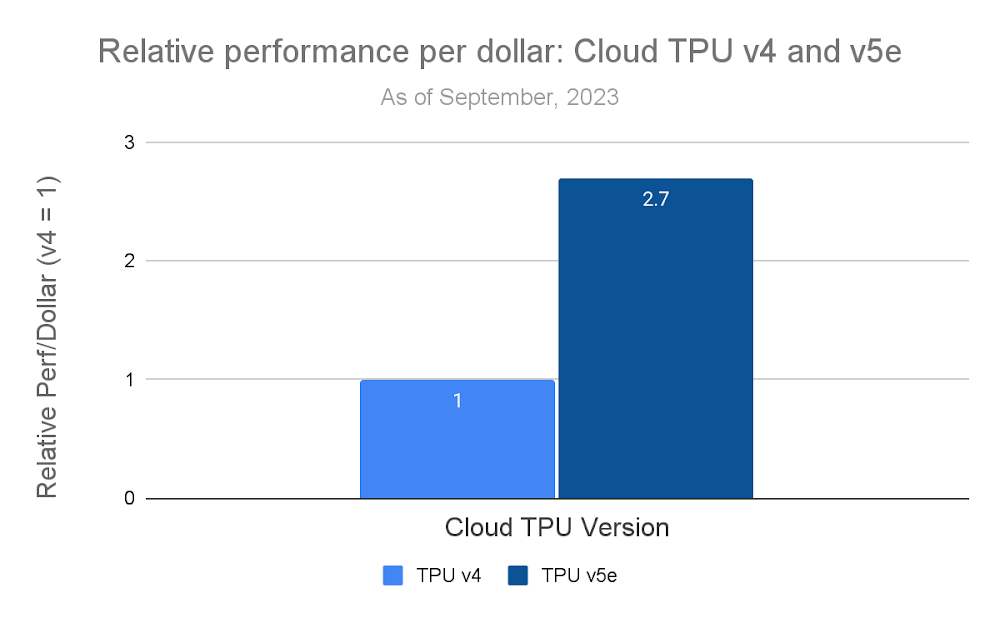
Similarly to the G2 performance per dollar metrics, we derived the performance per dollar metrics for the TPU3 from the results of MLPerf™ v3.1 Inference Closed. All prices are current at the time of publication. Performance per dollar is not an official MLPerf™ metric and is not verified by MLCommons® Association2.
The 2.7x gain in performance per dollar is possible thanks to an optimized inference software stack that takes full advantage of the powerful TPU v5e hardware, allowing it to match the QPS of the Cloud TPU v4 system on the GPT-J LLM benchmark. The inference stack uses SAX, a system created by Google DeepMind for high-performance AI inference, and XLA, Google’s AI compiler. Key optimizations include:
XLA optimizations and fusions of Transformer operators
Post-training weight quantization with int8 precision
High-performance sharding across the 2×2 topology using GSPMD
Bucketized execution of batches of prefix computation and decoding in SAX
Dynamic batching in SAX
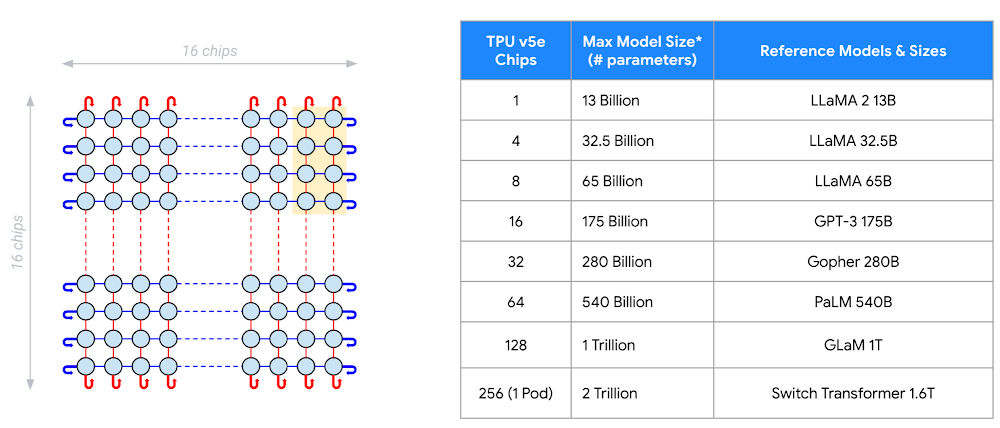
While these results showcase inference performance in four-chip configurations, TPU v5e scales seamlessly via our ICI from 1 chip to 256 chips, enabling the platform to flexibly support a range of inference and training requirements. As shown below, a 256-chip 16×16 TPU v5e topology supports inference for up to 2 trillion parameter models. With our newly available multi-slice training and multi-host inference software, Cloud TPU v5e can further scale to multiple 256-chip pods, enabling customers to leverage the same technology used internally by Google to meet the requirements of the largest and most complex model training and serving systems.
Accelerating your AI innovation at scale
With a full range of high-performance, cost-efficient AI inference choices powered by GPUs and TPUs, Google Cloud is uniquely positioned to empower organizations to accelerate their AI workloads at scale:
“Our team is a huge fan of Google Cloud’s AI infrastructure solution and we use Google Cloud G2 GPU VMs for the ‘AI Filter’ feature in our AI photography app, Remini, including for the latest filters – ‘Barbie and Ken.’ Using G2 VMs has allowed us to considerably lower latency times for processing by up to 15 seconds per task. Google Cloud has also been instrumental in helping us seamlessly scale up to 32,000 GPUs at peak times like when our Remini app soared into the No. 1 overall position on the U.S. App Store and down to a daily average of 2,000 GPUs.” — Luca Ferrari, CEO and Co-Founder, Bending Spoons
“Cloud TPU v5e consistently delivered up to 4X greater performance per dollar than comparable solutions in the market for running inference on our production model. The Google Cloud software stack is optimized for peak performance and efficiency, taking full advantage of the TPU v5e hardware that was purpose-built for accelerating the most advanced AI and ML models. This powerful and versatile combination of hardware and software dramatically accelerated our time-to-solution: instead of spending weeks hand-tuning custom kernels, within hours we optimized our model to meet and exceed our inference performance targets.” — Domenic Donato, VP of Technology, AssemblyAI
“YouTube is using the TPU v5e platform to serve recommendations on YouTube’s Homepage and WatchNext to billions of users. TPU v5e delivers up to 2.5x more queries for the same cost compared to the previous generation.” — Todd Beaupré, Director of Product Management, YouTube
To get started with Google Cloud GPUs and TPUs, reach out to your Google Cloud account manager or contact Google Cloud sales.
1. MLPerf™ v3.1 Inference Closed, multiple benchmarks as shown, Offline, 99%. Retrieved September 11th, 2023 from mlcommons.org. Results 3.1-0106, 3.1-0107, 3.1-0120, 3.1-0143. Performance per dollar is not an MLPerf metric.TPU v4 results are Unverified: not verified by MLCommons Association. The MLPerf™ name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.orgfor more information.
2. To derive performance per dollar for the Oracle BM GPU v2.8, we divided the QPS that Oracle submitted for the A100 results by $32.00, the publicly available server price per hour (US$). The Oracle system used 8 chips. To derive G2 performance per dollar, we divided the QPS from the L4 result by $0.85, the publicly available on-demand price per chip-hour (US$) for g2-standard-8 (a comparable Google instance type with a publicly available price point) in the us-central1 region. The L4 system used 1 chip.
3. To derive TPU v5e performance per dollar, we divided the QPS by the number of chips (4) used multiplied by $1.20, which is the publicly available on-demand price per chip-hour (US$) for TPU v5e in the us-west4 region. To derive TPU v4 performance per dollar, we divided the QPS (internal Google Cloud results, not verified by MLCommons Association) by the number of chips multiplied by $3.22, the publicly available on-demand price per chip-hour (US$) for TPU v4 in the us-central2 region.