
OpenAI Whisper is an advanced automatic speech recognition (ASR) model with an MIT license. ASR technology finds utility in transcription services, voice assistants, and enhancing accessibility for individuals with hearing impairments. This state-of-the-art model is trained on a vast and diverse dataset of multilingual and multitask supervised data collected from the web. Its high accuracy and adaptability make it a valuable asset for a wide array of voice-related tasks.
In the ever-evolving landscape of machine learning and artificial intelligence, Amazon SageMaker provides a comprehensive ecosystem. SageMaker empowers data scientists, developers, and organizations to develop, train, deploy, and manage machine learning models at scale. Offering a wide range of tools and capabilities, it simplifies the entire machine learning workflow, from data pre-processing and model development to effortless deployment and monitoring. SageMaker’s user-friendly interface makes it a pivotal platform for unlocking the full potential of AI, establishing it as a game-changing solution in the realm of artificial intelligence.
In this post, we embark on an exploration of SageMaker’s capabilities, specifically focusing on hosting Whisper models. We’ll dive deep into two methods for doing this: one utilizing the Whisper PyTorch model and the other using the Hugging Face implementation of the Whisper model. Additionally, we’ll conduct an in-depth examination of SageMaker’s inference options, comparing them across parameters such as speed, cost, payload size, and scalability. This analysis empowers users to make informed decisions when integrating Whisper models into their specific use cases and systems.
Solution overview
The following diagram shows the main components of this solution.
- In order to host the model on Amazon SageMaker, the first step is to save the model artifacts. These artifacts refer to the essential components of a machine learning model needed for various applications, including deployment and retraining. They can include model parameters, configuration files, pre-processing components, as well as metadata, such as version details, authorship, and any notes related to its performance. It’s important to note that Whisper models for PyTorch and Hugging Face implementations consist of different model artifacts.
- Next, we create custom inference scripts. Within these scripts, we define how the model should be loaded and specify the inference process. This is also where we can incorporate custom parameters as needed. Additionally, you can list the required Python packages in a
requirements.txtfile. During the model’s deployment, these Python packages are automatically installed in the initialization phase. - Then we select either the PyTorch or Hugging Face deep learning containers (DLC) provided and maintained by AWS. These containers are pre-built Docker images with deep learning frameworks and other necessary Python packages. For more information, you can check this link.
- With the model artifacts, custom inference scripts and selected DLCs, we’ll create Amazon SageMaker models for PyTorch and Hugging Face respectively.
- Finally, the models can be deployed on SageMaker and used with the following options: real-time inference endpoints, batch transform jobs, and asynchronous inference endpoints. We’ll dive into these options in more detail later in this post.
The example notebook and code for this solution are available on this GitHub repository.
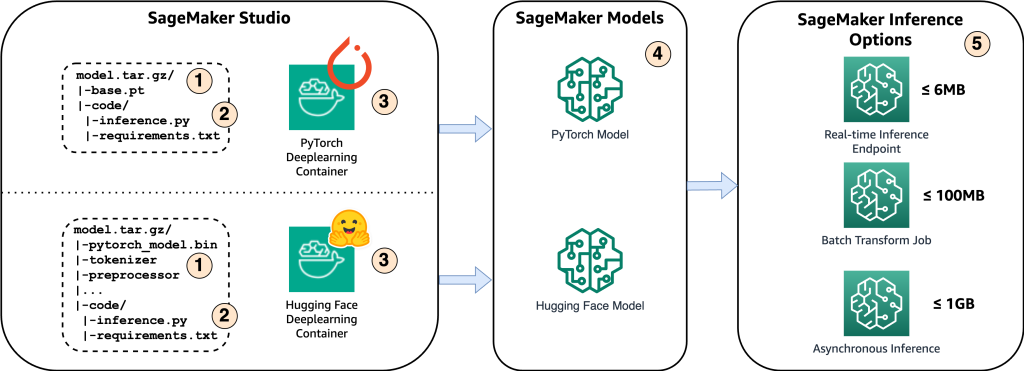
Figure 1. Overview of Key Solution Components
Walkthrough
Hosting the Whisper Model on Amazon SageMaker
In this section, we’ll explain the steps to host the Whisper model on Amazon SageMaker, using PyTorch and Hugging Face Frameworks, respectively. To experiment with this solution, you need an AWS account and access to the Amazon SageMaker service.
PyTorch framework
- Save model artifacts
The first option to host the model is to use the Whisper official Python package, which can be installed using pip install openai-whisper. This package provides a PyTorch model. When saving model artifacts in the local repository, the first step is to save the model’s learnable parameters, such as model weights and biases of each layer in the neural network, as a ‘pt’ file. You can choose from different model sizes, including ‘tiny,’ ‘base,’ ‘small,’ ‘medium,’ and ‘large.’ Larger model sizes offer higher accuracy performance, but come at the cost of longer inference latency. Additionally, you need to save the model state dictionary and dimension dictionary, which contain a Python dictionary that maps each layer or parameter of the PyTorch model to its corresponding learnable parameters, along with other metadata and custom configurations. The code below shows how to save the Whisper PyTorch artifacts.
- Select DLC
The next step is to select the pre-built DLC from this link. Be careful when choosing the correct image by considering the following settings: framework (PyTorch), framework version, task (inference), Python version, and hardware (i.e., GPU). It is recommended to use the latest versions for the framework and Python whenever possible, as this results in better performance and address known issues and bugs from previous releases.
- Create Amazon SageMaker models
Next, we utilize the SageMaker Python SDK to create PyTorch models. It’s important to remember to add environment variables when creating a PyTorch model. By default, TorchServe can only process file sizes up to 6MB, regardless of the inference type used.
The following table shows the settings for different PyTorch versions:
| Framework | Environment variables |
| PyTorch 1.8 (based on TorchServe) | ‘TS_MAX_REQUEST_SIZE‘: ‘100000000’‘ TS_MAX_RESPONSE_SIZE‘: ‘100000000’‘ TS_DEFAULT_RESPONSE_TIMEOUT‘: ‘1000’ |
| PyTorch 1.4 (based on MMS) | ‘MMS_MAX_REQUEST_SIZE‘: ‘1000000000’‘ MMS_MAX_RESPONSE_SIZE‘: ‘1000000000’‘ MMS_DEFAULT_RESPONSE_TIMEOUT‘: ‘900’ |
- Define the model loading method in inference.py
In the custom inference.py script, we first check for the availability of a CUDA-capable GPU. If such a GPU is available, then we assign the 'cuda' device to the DEVICE variable; otherwise, we assign the 'cpu' device. This step ensures that the model is placed on the available hardware for efficient computation. We load the PyTorch model using the Whisper Python package.
Hugging Face framework
- Save model artifacts
The second option is to use Hugging Face’s Whisper implementation. The model can be loaded using the AutoModelForSpeechSeq2Seq transformers class. The learnable parameters are saved in a binary (bin) file using the save_pretrained method. The tokenizer and preprocessor also need to be saved separately to ensure the Hugging Face model works properly. Alternatively, you can deploy a model on Amazon SageMaker directly from the Hugging Face Hub by setting two environment variables: HF_MODEL_ID and HF_TASK. For more information, please refer to this webpage.
- Select DLC
Similar to the PyTorch framework, you can choose a pre-built Hugging Face DLC from the same link. Make sure to select a DLC that supports the latest Hugging Face transformers and includes GPU support.
- Create Amazon SageMaker models
Similarly, we utilize the SageMaker Python SDK to create Hugging Face models. The Hugging Face Whisper model has a default limitation where it can only process audio segments up to 30 seconds. To address this limitation, you can include the chunk_length_s parameter in the environment variable when creating the Hugging Face model, and later pass this parameter into the custom inference script when loading the model. Lastly, set the environment variables to increase payload size and response timeout for the Hugging Face container.
| Framework | Environment variables |
HuggingFace Inference Container (based on MMS) | ‘MMS_MAX_REQUEST_SIZE‘: ‘2000000000’‘ MMS_MAX_RESPONSE_SIZE‘: ‘2000000000’‘ MMS_DEFAULT_RESPONSE_TIMEOUT‘: ‘900’ |
- Define the model loading method in inference.py
When creating custom inference script for the Hugging Face model, we utilize a pipeline, allowing us to pass the chunk_length_s as a parameter. This parameter enables the model to efficiently process long audio files during inference.
Exploring different inference options on Amazon SageMaker
The steps for selecting inference options are the same for both PyTorch and Hugging Face models, so we won’t differentiate between them below. However, it’s worth noting that, at the time of writing this post, the serverless inference option from SageMaker doesn’t support GPUs, and as a result, we exclude this option for this use-case.
We can deploy the model as a real-time endpoint, providing responses in milliseconds. However, it’s important to note that this option is limited to processing inputs under 6 MB. We define the serializer as an audio serializer, which is responsible for converting the input data into a suitable format for the deployed model. We utilize a GPU instance for inference, allowing for accelerated processing of audio files. The inference input is an audio file that is from the local repository.
The second inference option is the batch transform job, which is capable of processing input payloads up to 100 MB. However, this method may take a few minutes of latency. Each instance can handle only one batch request at a time, and the instance initiation and shutdown also require a few minutes. The inference results are saved in an Amazon Simple Storage Service (Amazon S3) bucket upon completion of the batch transform job.
When configuring the batch transformer, be sure to include max_payload = 100 to handle larger payloads effectively. The inference input should be the Amazon S3 path to an audio file or an Amazon S3 Bucket folder containing a list of audio files, each with a size smaller than 100 MB.
Batch Transform partitions the Amazon S3 objects in the input by key and maps Amazon S3 objects to instances. For example, when you have multiple audio files, one instance might process input1.wav, and another instance might process the file named input2.wav to enhance scalability. Batch Transform allows you to configure max_concurrent_transforms to increase the number of HTTP requests made to each individual transformer container. However, it’s important to note that the value of (max_concurrent_transforms* max_payload) must not exceed 100 MB.
Finally, Amazon SageMaker Asynchronous Inference is ideal for processing multiple requests concurrently, offering moderate latency and supporting input payloads of up to 1 GB. This option provides excellent scalability, enabling the configuration of an autoscaling group for the endpoint. When a surge of requests occurs, it automatically scales up to handle the traffic, and once all requests are processed, the endpoint scales down to 0 to save costs.
Using asynchronous inference, the results are automatically saved to an Amazon S3 bucket. In the AsyncInferenceConfig, you can configure notifications for successful or failed completions. The input path points to an Amazon S3 location of the audio file. For additional details, please refer to the code on GitHub.
Optional: As mentioned earlier, we have the option to configure an autoscaling group for the asynchronous inference endpoint, which allows it to handle a sudden surge in inference requests. A code example is provided in this GitHub repository. In the following diagram, you can observe a line chart displaying two metrics from Amazon CloudWatch: ApproximateBacklogSize and ApproximateBacklogSizePerInstance. Initially, when 1000 requests were triggered, only one instance was available to handle the inference. For three minutes, the backlog size consistently exceeded three (please note that these numbers can be configured), and the autoscaling group responded by spinning up additional instances to efficiently clear out the backlog. This resulted in a significant decrease in the ApproximateBacklogSizePerInstance, allowing backlog requests to be processed much faster than during the initial phase.
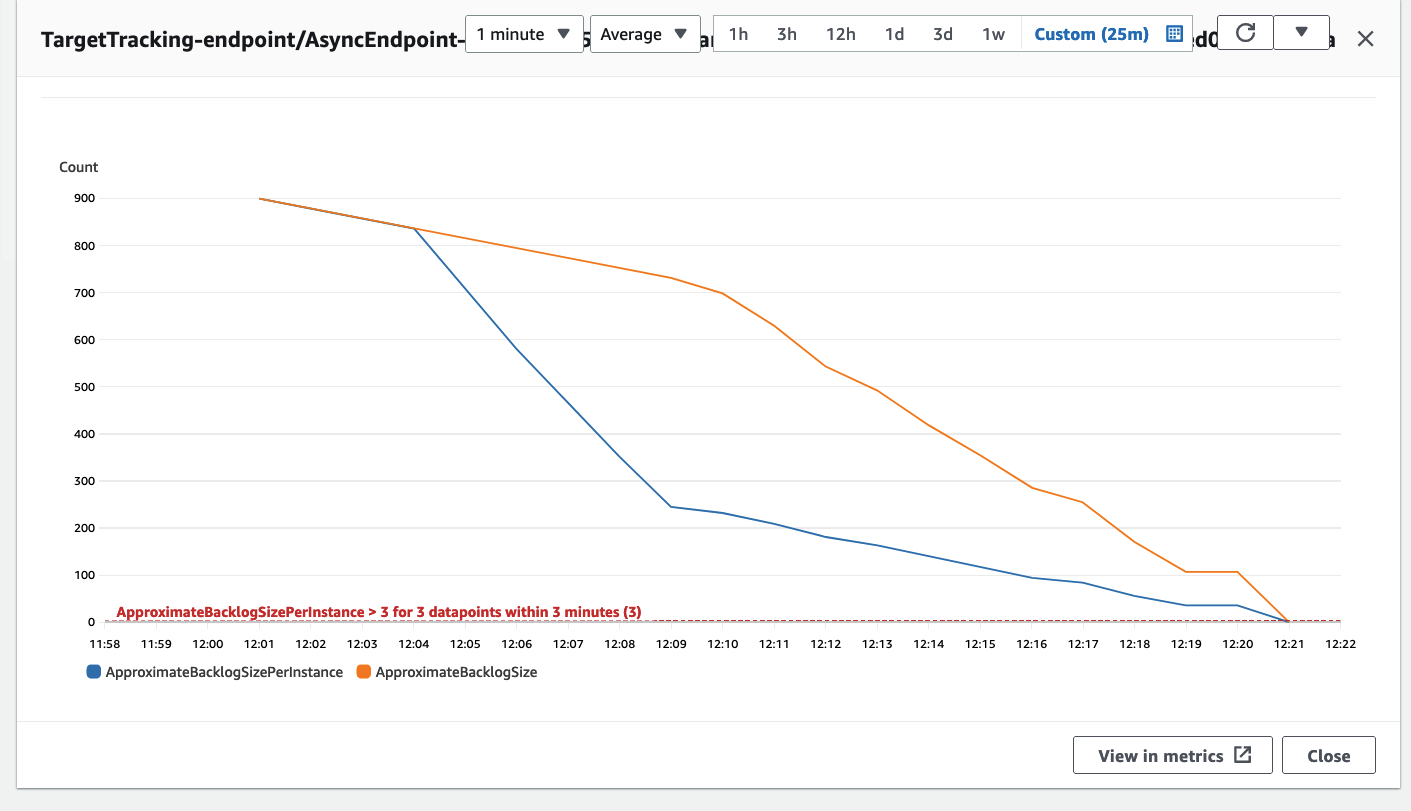
Figure 2. Line chart illustrating the temporal changes in Amazon CloudWatch metrics
Comparative analysis for the inference options
The comparisons for different inference options are based on common audio processing use cases. Real-time inference offers the fastest inference speed but restricts payload size to 6 MB. This inference type is suitable for audio command systems, where users control or interact with devices or software using voice commands or spoken instructions. Voice commands are typically small in size, and low inference latency is crucial to ensure that transcribed commands can promptly trigger subsequent actions. Batch Transform is ideal for scheduled offline tasks, when each audio file’s size is under 100 MB, and there is no specific requirement for fast inference response times. Asynchronous inference allows for uploads of up to 1 GB and offers moderate inference latency. This inference type is well-suited for transcribing movies, TV series, and recorded conferences where larger audio files need to be processed.
Both real-time and asynchronous inference options provide autoscaling capabilities, allowing the endpoint instances to automatically scale up or down based on the volume of requests. In cases with no requests, autoscaling removes unnecessary instances, helping you avoid costs associated with provisioned instances that aren’t actively in use. However, for real-time inference, at least one persistent instance must be retained, which could lead to higher costs if the endpoint operates continuously. In contrast, asynchronous inference allows instance volume to be reduced to 0 when not in use. When configuring a batch transform job, it’s possible to use multiple instances to process the job and adjust max_concurrent_transforms to enable one instance to handle multiple requests. Therefore, all three inference options offer great scalability.
Cleaning up
Once you have completed utilizing the solution, ensure to remove the SageMaker endpoints to prevent incurring additional costs. You can use the provided code to delete real-time and asynchronous inference endpoints, respectively.
Conclusion
In this post, we showed you how deploying machine learning models for audio processing has become increasingly essential in various industries. Taking the Whisper model as an example, we demonstrated how to host open-source ASR models on Amazon SageMaker using PyTorch or Hugging Face approaches. The exploration encompassed various inference options on Amazon SageMaker, offering insights into efficiently handling audio data, making predictions, and managing costs effectively. This post aims to provide knowledge for researchers, developers, and data scientists interested in leveraging the Whisper model for audio-related tasks and making informed decisions on inference strategies.
For more detailed information on deploying models on SageMaker, please refer to this Developer guide. Additionally, the Whisper model can be deployed using SageMaker JumpStart. For additional details, kindly check the Whisper models for automatic speech recognition now available in Amazon SageMaker JumpStart post.
Feel free to check out the notebook and code for this project on GitHub and share your comment with us.
About the Author
 Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS. Her primary areas of interest encompass Deep Learning, with a focus on GenAI, Computer Vision, NLP, and time series data prediction. In her spare time, she relishes spending quality moments with her family, immersing herself in novels, and hiking in the national parks of the UK.
Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS. Her primary areas of interest encompass Deep Learning, with a focus on GenAI, Computer Vision, NLP, and time series data prediction. In her spare time, she relishes spending quality moments with her family, immersing herself in novels, and hiking in the national parks of the UK.